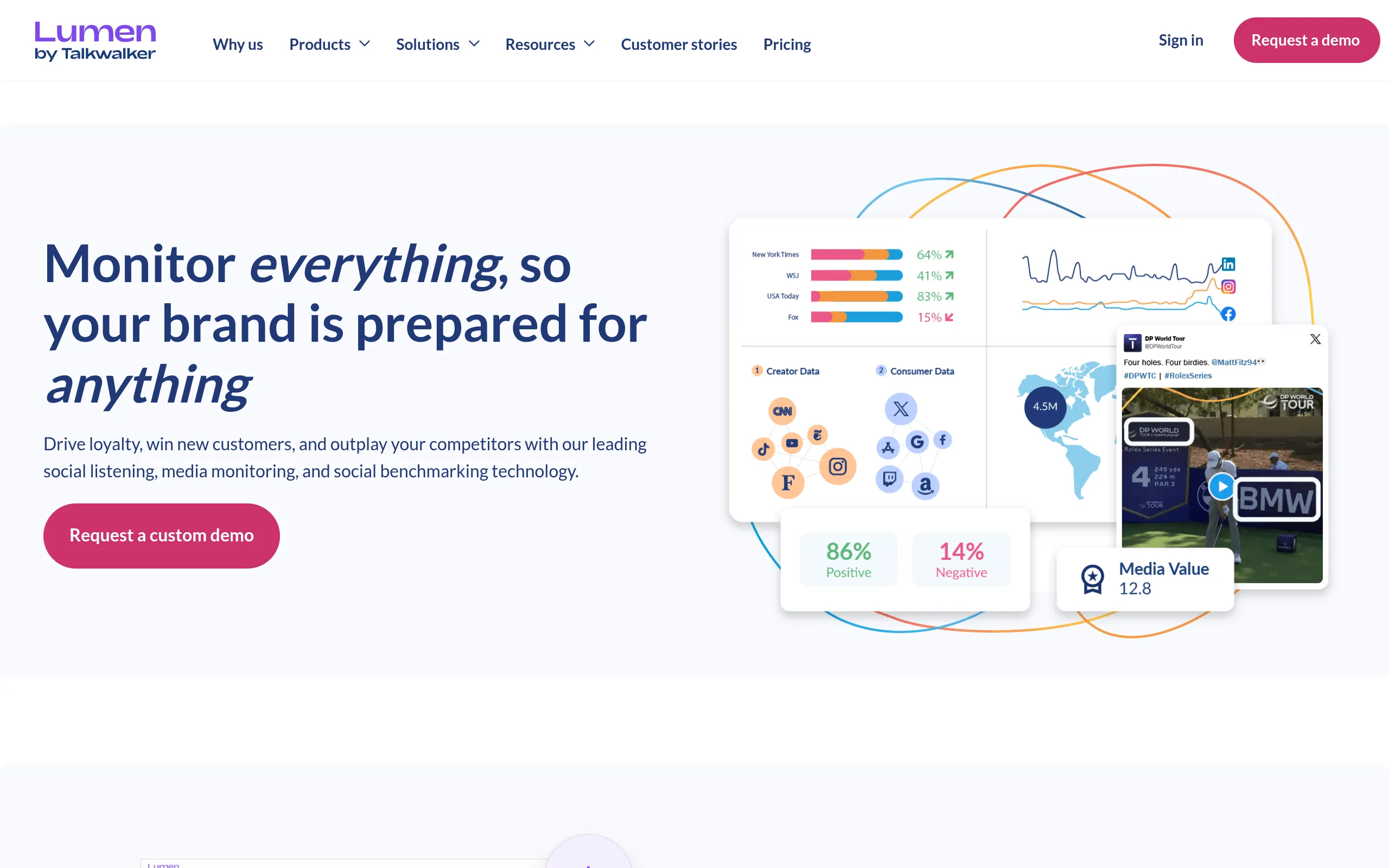
Search demand for a “brand mentions service” is climbing for a simple reason: ChatGPT, Perplexity, and Google’s AI Overviews now name-check brands directly in their answers instead of just ranking a link to them, and most agencies selling “brand mentions” haven’t rebuilt their process around that shift.
This article ranks 10 US brand mentions agencies against six explicit criteria: publication quality, AI-citation tracking, transparency, pricing clarity, industry specialization, and verifiable track record. You’ll get a full profile for each, a comparison table, and a straight flag on which agencies are genuine AI-citation specialists versus relabeled link builders.
One disclosure up front: BrandMentions.link publishes this article and is one of the ten, so vet it with the same scrutiny you’d apply to any vendor here.
What a Brand Mentions Service Agency Actually Does
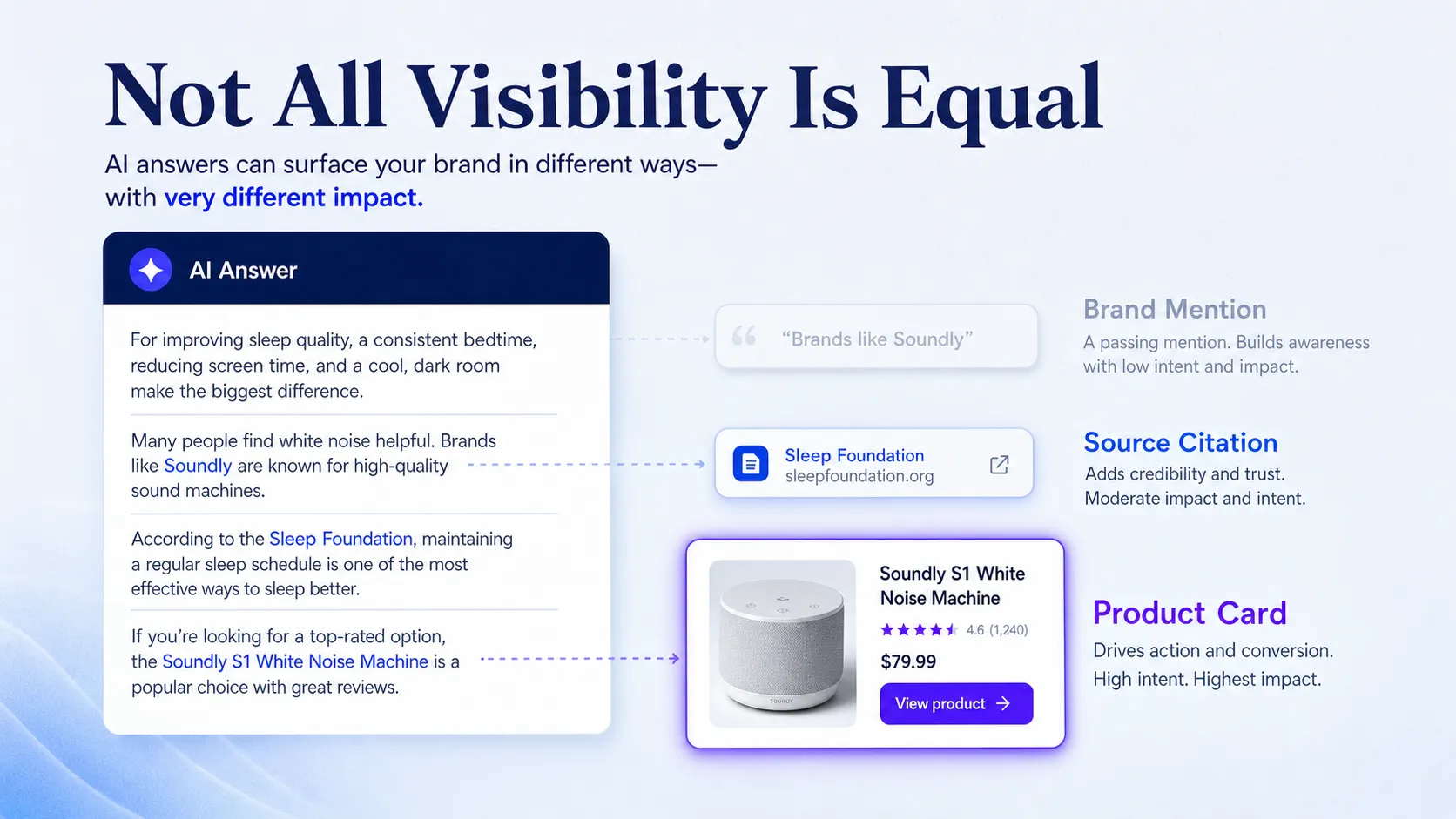
A brand mentions service places editorial references to your brand name or entity inside third-party content, whether or not that reference carries a hyperlink. That’s the core distinction from a backlink-first guest post or niche edit, where the link is the deliverable and the mention is incidental.
An unlinked brand mention still teaches AI answer engines to associate your brand with a topic, which is why the “mention” matters even when no link comes with it. If you want the mechanism in depth, the difference between mentions and backlinks is worth a separate read.
Here’s the pattern worth watching before you hire anyone. A subset of “brand mentions agencies” are link-building shops that swapped the word “backlink” for “brand mention” on their sales page without changing publication selection, outreach cadence, or reporting.
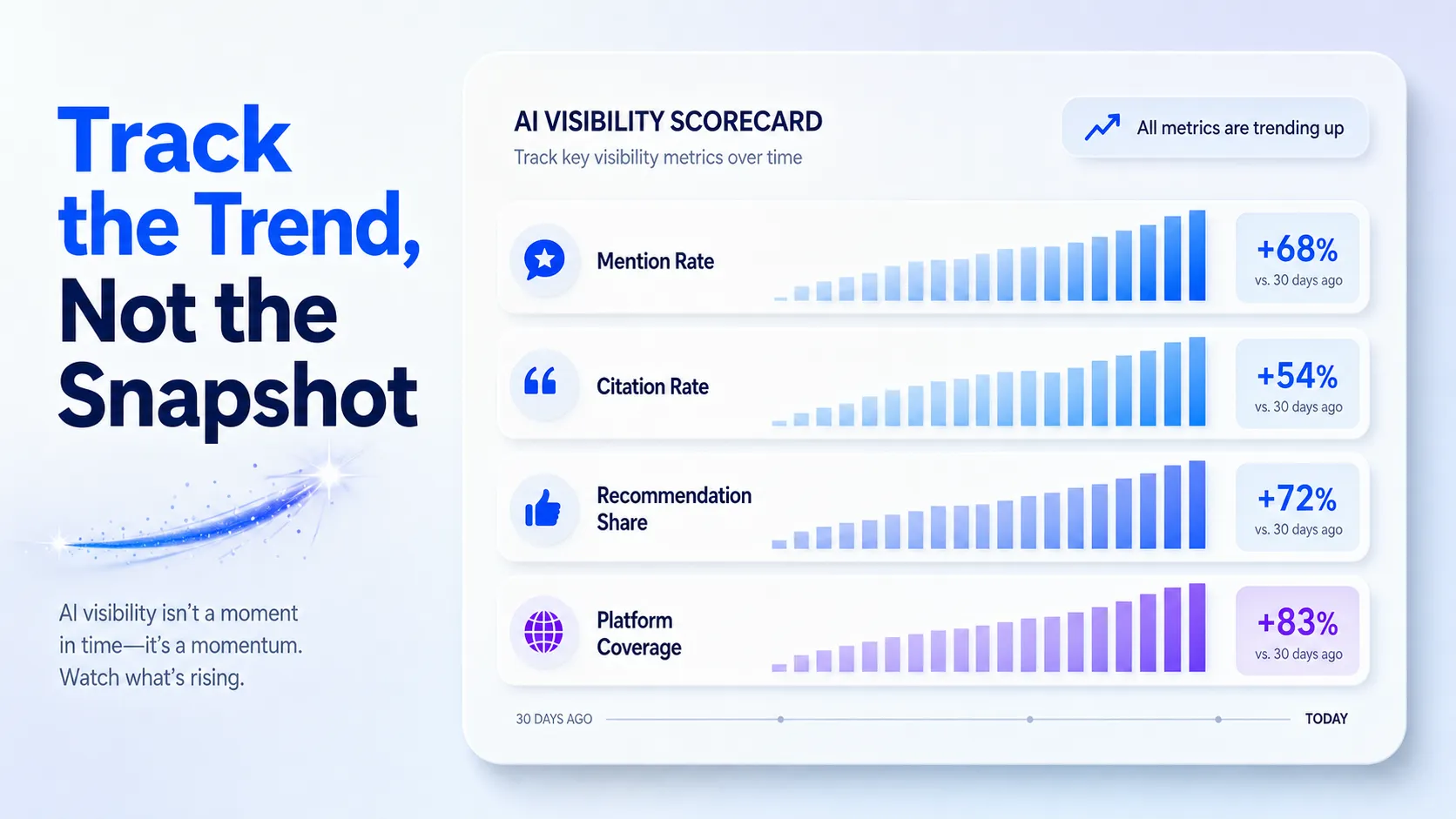
The real difference in an AI-citation-focused program shows up after placement: it tracks whether the mention surfaces in ChatGPT, Perplexity, Gemini, or AI Overviews, not just domain rating and referral traffic. That tracking-and-measurement gap, not a vague claim about training cycles, is the filter the rest of this article applies.
Criteria for Selection
Every agency below was judged against the same six factors, and each profile names the one or two that earned its placement. That closes the most common gap in competitor roundups, where the criteria get described but never visibly applied.

- Publication network quality: named outlet tiers or categories the agency actually places in, not generic “high-DA” claims.
- AI-citation focus and tracking: whether the agency checks and reports if placements surface in ChatGPT, Perplexity, Gemini, or AI Overviews, and how.
- Transparency and reporting: live dashboards or named URLs versus vague monthly recaps, and disclosed versus hidden pricing.
- Pricing clarity: a published rate card versus “contact for a quote,” and whether pricing is per-placement, per-campaign, or retainer.
- Industry specialization: a narrow vertical focus versus generalist full-service coverage.
- Verifiable track record: public case studies, named clients, and third-party review platforms versus anecdote-only claims.
One pattern from reviewing vendor sites for this piece: pricing opacity is the single most common reason a mention-focused agency scores low on transparency. “Contact us for a custom quote” is a fine sales tactic, but it makes side-by-side comparison harder for you, so it counts against the agency here.
The Top 10 Brand Mentions Service Agencies in the USA (2026)
Each profile follows the same shape: what the agency is, why it made the list tied to named criteria, its key differentiator, a directional pricing signal, and the reader it fits best. No entry runs much longer than any other, including the publisher’s own.
1. BrandMentions.link (Disclosed Interested Party)
BrandMentions.link publishes this article and is included here as a disclosed interested party. Evaluate it against the same six criteria, and against the other nine agencies, before shortlisting.
It runs an in-house programmatic mention placement service on a claimed 255-publication network with built-in AI-citation tracking. It scores on pricing clarity, unusual on this list, through a published tiered pricing page, and on AI-citation focus by tracking placements across ChatGPT, Perplexity, Gemini, and Copilot. Its differentiator is a published process and industry-specific programmes rather than a one-size pitch.
- Best for: buyers running the same reference checks below on the vendor that authored this list
- Pricing model: published tiers, roughly $1,997 to $4,997+ per month (self-reported)
- Standout strength: published pricing plus multi-engine AI-citation tracking
2. Outreach Desk

Outreach Desk is a managed, fully transparent link insertion and digital PR service that places mentions through real manual outreach to topically relevant publishers, and it fits agencies and B2B teams wanting predictable, transparent pricing with clear sourcing.
It scores on transparency and reporting through full visibility into where every placement lands, and on pricing clarity through a published per-placement rate card. Its differentiator is a dedicated account manager plus a link replacement guarantee if a placement is removed within six months, trading same-day marketplace speed for manually vetted relevance. One of its published case studies shows a SaaS client’s traffic growing from 9.6K to 123K monthly visitors across 611 placed links.
- Best for: agencies and B2B teams wanting manual, transparent placements with clear sourcing
- Pricing model: $200 to $300 per placement across Foundation, Growth, and Custom tiers, published (self-reported)
- Standout strength: dedicated account manager plus a six-month link replacement guarantee
3. Siege Media
Siege Media is a content-and-links agency that earns brand mentions mainly through original research and interactive assets rather than pitched placements, and it fits mid-market to enterprise teams that want earned, non-paid mentions.
It scores on publication network quality, with mentions landing in mid-to-top-tier business and tech press, and on verifiable track record through public case studies. The differentiator is that mentions are a byproduct of high-production content, not a standalone outreach line item, which means a slower cadence but stronger editorial authenticity. That trade-off is real: you’re buying a content program that produces mentions, not a per-mention service. Its published case studies name results like Zendesk reaching 98 percent LLM visibility and Instacart earning 46,500 citations across large language models.
- Best for: mid-market and enterprise SaaS or fintech teams wanting earned mentions
- Pricing model: monthly retainer, roughly $10K to $30K+ (directional)
- Standout strength: mentions earned through original research and content assets
4. Omniscient Digital
Omniscient Digital is a B2B SaaS-focused SEO and content agency where brand mentions fold into a broader organic growth engine, built for teams that want mentions bundled into a full-funnel retainer.
It scores on industry specialization through its narrow SaaS focus and on transparency through public case studies with traffic and pipeline figures attached. Because mentions aren’t sold as a separate line, cost-per-mention is hard to isolate, which is worth knowing if you want to attribute spend tightly. You’re hiring a growth partner, not a placements desk. Named case studies on its site claim an 810 percent organic session increase for Jasper and $3.7 million in pipeline generated for Smartling.
- Best for: SaaS marketing teams wanting mentions inside a content and SEO retainer
- Pricing model: monthly retainer, roughly $8K to $20K (directional)
- Standout strength: topic-authority content tied to pipeline reporting
5. iPullRank
iPullRank is a technical SEO and generative engine optimization consultancy that added structured AI-citation auditing to its core offering, and it suits enterprise brands wanting a technical-plus-editorial hybrid. Generative engine optimization, or GEO, means shaping your content and markup so AI answer engines can parse and cite it.
It scores on AI-citation focus through published GEO research and LLM-prompt testing, and on verifiable track record through public audits and speaking work. The differentiator is that it leads with schema and entity markup, then pairs that with editorial mention-building rather than leaning on outreach volume. Founder Mike King’s “Relevance Engineering” framework is the basis for a claimed $2.4 billion in incremental revenue for one financial-services client.
- Best for: enterprise brands wanting a technical and editorial GEO strategy
- Pricing model: custom-scoped; GEO audits reportedly from around $15K (directional)
- Standout strength: schema and entity markup paired with editorial placement
6. Click Intelligence
Click Intelligence is a digital PR agency offering brand mention campaigns bundled with traditional link building, and it fits brands wanting combined backlink-and-mention work without dedicated AI-citation tracking.
It scores on publication network through claimed relationships across niche and national outlets, but it’s flagged lower on transparency because pricing isn’t published anywhere reviewed for this piece. The differentiator is that mentions are one output of a backlink-first campaign, not a standalone AI-citation program. If AI-engine tracking is a priority, this is not the pick. Its published case studies include a 500 percent year-over-year user increase for one client, and it has been named a finalist or winner in several UK and global search-marketing awards.
- Best for: brands wanting combined backlink and mention campaigns
- Pricing model: per-campaign, third-party sources cite roughly $2,000+ (unconfirmed)
- Standout strength: niche-to-national publisher relationships
7. Outreach Monks
Outreach Monks is a manual outreach shop selling brand mentions and links on a per-placement basis, built for smaller budgets testing the channel before a retainer.
It scores on pricing clarity through published per-placement rates and partially on track record through published, though largely anecdotal, case studies. The differentiator is à la carte pricing instead of a retainer, which lowers the entry barrier. The caveat that comes with per-placement buying: you carry more of the strategy and cadence decisions yourself. Founded in 2017, it now runs a 70-plus person team serving 500-plus agencies and brands across 40-plus countries, publishing a 12-point domain-vetting checklist for every placement.
- Best for: small businesses or solo marketers testing brand mentions
- Pricing model: per-placement, $99 to $299 depending on domain rating (self-reported)
- Standout strength: à la carte per-mention pricing with a low entry point
8. NP Digital

NP Digital is a large full-service digital marketing agency offering brand mentions and digital PR as one component of broader retainers, and it fits enterprise brands wanting mentions as a line item inside integrated marketing.
It scores on verifiable track record through a large public client roster and case study library, but scores lower on industry specialization given its generalist positioning. The differentiator is scale and channel integration across SEO, paid, content, and PR under one roof, not a mention-specific methodology.
- Best for: enterprise brands wanting mentions inside an integrated retainer
- Pricing model: retainer, roughly $10K to $50K+ per month blended (directional)
- Standout strength: scale and cross-channel integration
9. Seer Interactive
Seer Interactive is a data-driven enterprise SEO and digital PR agency known for analytics rigor, built for teams that want mention campaigns tied to a measurement framework.
It scores on transparency and reporting through detailed analytics dashboards and on verifiable track record through enterprise case studies. The differentiator is a heavier measurement layer than most mention-focused vendors, which helps you correlate mentions with pipeline instead of just counting placements. That rigor suits teams with the analytics maturity to use it. Founded more than 20 years ago, it serves 130-plus enterprise clients at a 92 percent retention rate and has published monthly AI-visibility research since January 2023.
- Best for: enterprise teams wanting mentions tied to measurement
- Pricing model: enterprise retainer, typically from $15K+ per month (directional)
- Standout strength: analytics depth linking mentions to pipeline
10. LinkGraph

LinkGraph is an SEO agency built around its SearchAtlas software, offering mention and link campaigns with in-platform reporting, and it fits buyers who specifically want a live reporting tool alongside the service.
It scores on transparency and reporting through a live client-facing dashboard and on pricing clarity through published package tiers. The differentiator is the software-plus-service model, where you see placement status inside a live dashboard rather than a static monthly PDF. With over a decade in SEO, it counts P&G and Zynga among named clients and cites average client traffic gains of 135 to 568 percent.
- Best for: buyers wanting a live reporting dashboard with the service
- Pricing model: published packages, reportedly from around $1,500 to $5,000 per month (directional)
- Standout strength: live in-platform placement reporting
Comparison Summary Table
Here’s the full set side by side, sorted in the same order as the profiles above so nothing gets silently re-ranked. Every pricing cell keeps its directional or self-reported label, and the AI-citation column is the honest credibility check.
| Agency | Best For | Pricing Model / Range | AI-Citation Focus | Specialization |
|---|---|---|---|---|
| BrandMentions.link | Buyers who reference-check | $1,997 to $4,997+/mo (self-reported) | Yes | AI-citation placements |
| Outreach Desk | Manual, transparent placements | $200 to $300/placement (self-reported) | No | Managed outreach and digital PR |
| Siege Media | Earned, non-paid mentions | $10K to $30K+/mo (directional) | Partial | Content and links |
| Omniscient Digital | SaaS growth retainers | $8K to $20K/mo (directional) | Partial | B2B SaaS |
| iPullRank | Technical plus editorial GEO | From ~$15K audits (directional) | Yes | GEO and technical SEO |
| Click Intelligence | Backlink plus mention combos | ~$2,000+/campaign (unconfirmed) | No | Digital PR |
| Outreach Monks | Testing before a retainer | $199 to $299/placement (self-reported) | No | Manual outreach |
| NP Digital | Integrated enterprise retainers | $10K to $50K+/mo (directional) | Partial | Generalist full-service |
| Seer Interactive | Measurement-led campaigns | From $15K+/mo (directional) | Partial | Data-driven digital PR |
| LinkGraph | Live dashboard reporting | $1,500 to $5,000/mo (directional) | Partial | Software plus service |
“Partial” is the most common rating in this set, and that’s the honest state of the market in 2026, not a flaw in the method. Most agencies can place a mention; far fewer will tell you whether it surfaced inside an AI answer.
How these were picked: each agency was scored against the six criteria at the top of this article, using public case studies, published pricing where it exists, and vendor positioning drawn from their own sites. No agency was tested with live client campaigns for this piece, so rankings reflect documented signals and stated focus, not proprietary performance data.

How These Agencies Compare on Scale and Proof
The table above compares service model and pricing. This one adds the scale and proof points each agency publishes about itself, useful context for a reference call, but not independently verified for this piece. Treat named clients and case-study numbers as a starting point for your own diligence, not a substitute for it.
| Agency | Scale / Experience | Notable Named Clients | Headline Published Result |
|---|---|---|---|
| BrandMentions.link | 255-publication network, tracking across 4 AI engines | Not published (agency-side network, not client case studies) | N/A, network size is self-reported |
| Outreach Desk | 500+ agencies and 1,000+ businesses served (self-reported) | Not named; case studies are anonymized | 9.6K to 123K monthly traffic for one SaaS client, across 611 links |
| Siege Media | 4 US offices, 8 industry verticals | Airbnb, HubSpot, Zendesk, Instacart, Adidas | Zendesk: 98% LLM visibility; $148.6M cumulative client traffic value claimed |
| Omniscient Digital | 5 US offices, B2B SaaS focus | Jasper, Drift, TikTok Shop, Smartling | Jasper: 810% organic session growth |
| iPullRank | Founder-led (Mike King), enterprise focus | Target, American Express, MLB, Adidas | $2.4B incremental revenue claimed for one financial-services client |
| Click Intelligence | UK-based, offices in Cheltenham and London | Holiday Inn, eBay, Betway Group, 888 Poker | 500% year-over-year user increase for one client |
| Outreach Monks | Founded 2017, 70+ staff, active in 40+ countries | ExpressVPN, Coinbase, Sephora, TripAdvisor | 499% traffic growth over 35 months for one client |
| NP Digital | Global full-service agency | Not independently verified for this piece | Not independently verified for this piece |
| Seer Interactive | 20+ years in business, 130+ enterprise clients | American Family Insurance, Drexel University, TIME, Intuit | 92% client retention rate, self-reported |
| LinkGraph | 10+ years in SEO, built around SearchAtlas software | P&G, Zynga, Shutterfly, Verkada | Average client traffic gains cited at 135% to 568% |
NP Digital did not return verifiable scale or case-study detail for this piece; its comparison-table entries above still stand on published positioning and specialization.
How to Vet a Brand Mentions Agency Before Signing
These five questions work on any agency, including the ones above. Ask them before a contract, not after a dispute.
Ask for three recent placements and one client reference
Request three specific publication names they’ve placed in during the last 90 days, plus one client you can contact directly. Recent, named placements prove the network is live rather than historical, and a reachable reference tells you what working with them is actually like.
Ask exactly how they check AI-engine appearance
Ask how they confirm a placement gets surfaced by ChatGPT, Perplexity, Gemini, or Google AI Overviews, and demand the actual method: manual prompt testing, a named tool, or a partner platform. “We monitor AI visibility” is not an answer, and the specificity of the response separates specialists from marketers using the phrase as decoration.
Ask about contract term and ownership
Ask for the minimum term, the cancellation notice period, and whether placements stay live and owned by you if you cancel. Term length and ownership decide how much leverage you keep, and a short answer here often signals a fairer deal.
Ask what happens if a placement disappears
Ask what they do if a placement is removed, deindexed, or the host site’s quality drops after publication, and get the replacement or refund policy in writing. This is the question buyers skip most often and the one where disputes cluster, so pin it down before money changes hands.
Ask what the quoted price excludes
Ask what’s outside the quote: content writing, revision rounds, expedited placement fees, or exclusivity clauses on the publication. Exclusions are where a clean-looking price quietly inflates, so surface them before you compare two agencies on cost.
Frequently Asked Questions
Are brand mentions better than backlinks for AI search visibility?
For AI answer engines, brand mentions and backlinks do different jobs, and mentions often carry more weight for citations. A link passes authority a crawler follows, while a mention, linked or not, builds the entity association an engine uses to decide who to name in an answer.
The honest read: you want both, but if AI citation is the goal, prioritize mentions in sources the engines already draw from. The full breakdown lives in how brand mentions work in AI search.
How much should I budget for a brand mentions service in 2026?
Budget ranges from roughly $199 to $299 per placement at the à la carte end to $8K to $50K+ per month for enterprise retainers, based on the pricing signals in the profiles above.
A small business testing the channel can start per-placement, while a SaaS or enterprise team building sustained citation authority usually needs a retainer. Match the model to your goal: one-off tests reward per-placement pricing, compounding authority rewards a monthly cadence.
How long does it take for a brand mention to show up in ChatGPT or Google AI Overviews?
Timing varies by engine and by whether the placement sits in a source the engine retrieves live. Engines that pull real-time web results can surface a mention within weeks, while appearances tied to a model’s training refresh are far less predictable and shouldn’t be promised on a fixed date.
Treat any agency guaranteeing a specific appearance date with caution, because no vendor controls when an engine chooses to name you.
Do unlinked brand mentions still help SEO if there’s no hyperlink?
Yes, unlinked mentions still help by strengthening entity recognition, even without passing link equity. Search and AI systems increasingly read your brand name in context to understand what you’re known for, which shapes both classic rankings and answer-engine citations. Converting some of those unlinked references into links adds authority on top, which is a separate workflow worth running.
Can I build brand mentions in-house instead of hiring an agency?
You can, and it makes sense when you already have outreach capacity and editorial relationships. The trade-off is time and access: agencies bring existing publisher contacts and tracking infrastructure you’d otherwise build from scratch. A practical middle path is running monitoring of brand mentions in LLMs in-house while outsourcing the placement outreach, so you keep visibility without staffing the whole function.
How do agencies actually verify that a placement influenced an AI-generated answer?
The credible method is manual prompt testing: running the buying questions your customers ask into ChatGPT, Perplexity, Gemini, and AI Overviews, then recording whether your brand gets named and which source is cited. Some agencies pair this with tools that log citations at scale. Be skeptical of any explanation built on “training cycles” you can’t inspect, because verification should come from observable answers, not unverifiable claims about model internals.
Choosing Your Shortlist
The ranking matters less than the fit. Two agencies on this list can both be excellent and still be wrong for you, because a SaaS growth team and a small business testing the channel need different models entirely.
Pick two or three agencies here that match your industry and budget, run each through the five vetting questions above, and request a baseline AI-citation audit, from one of them or from us, before you sign anything.