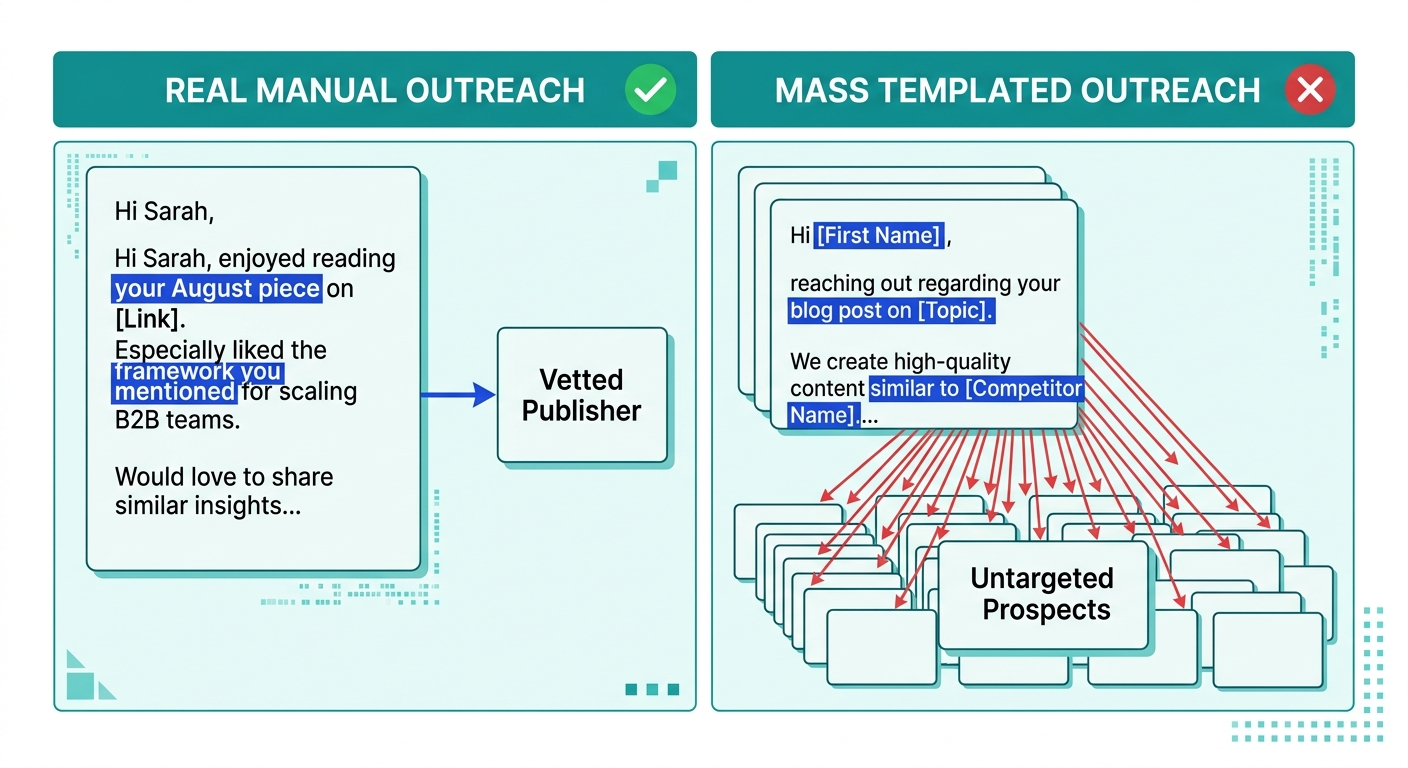
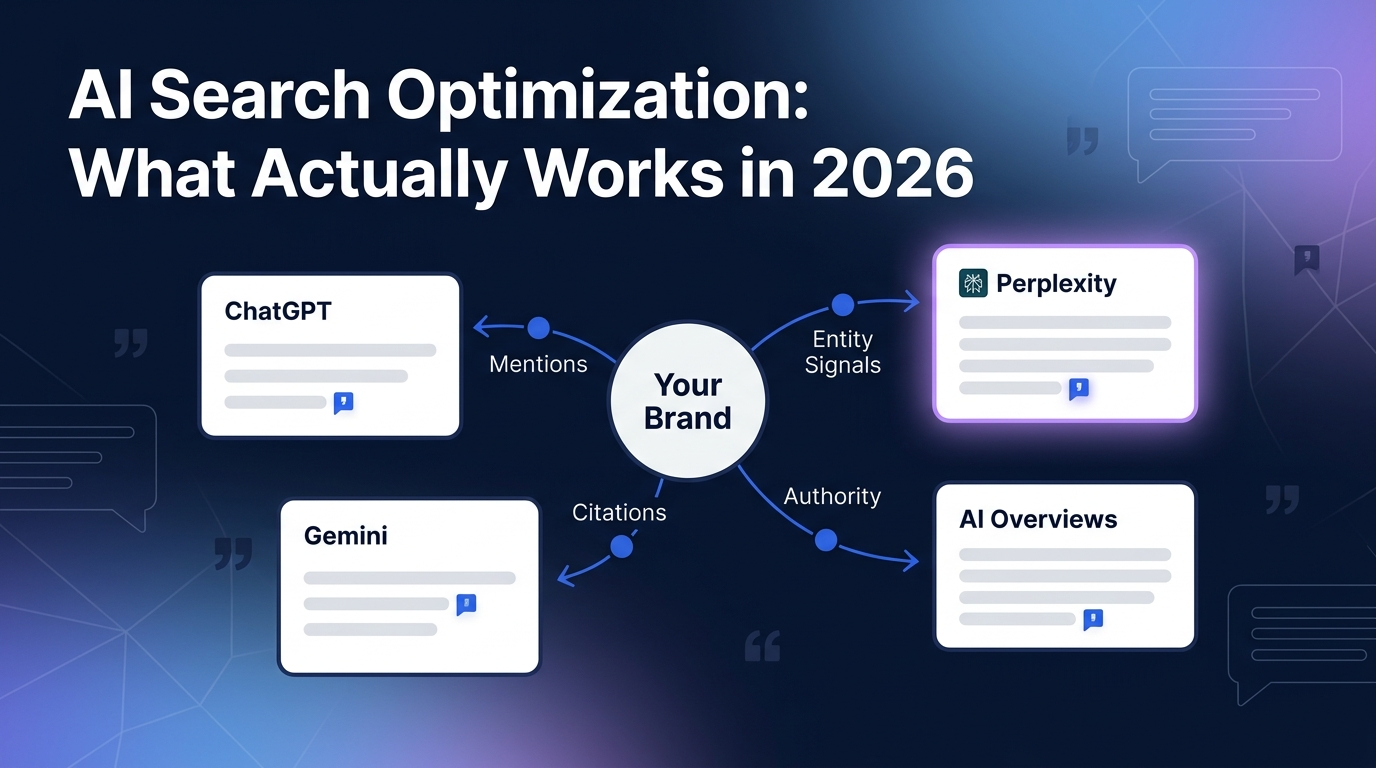
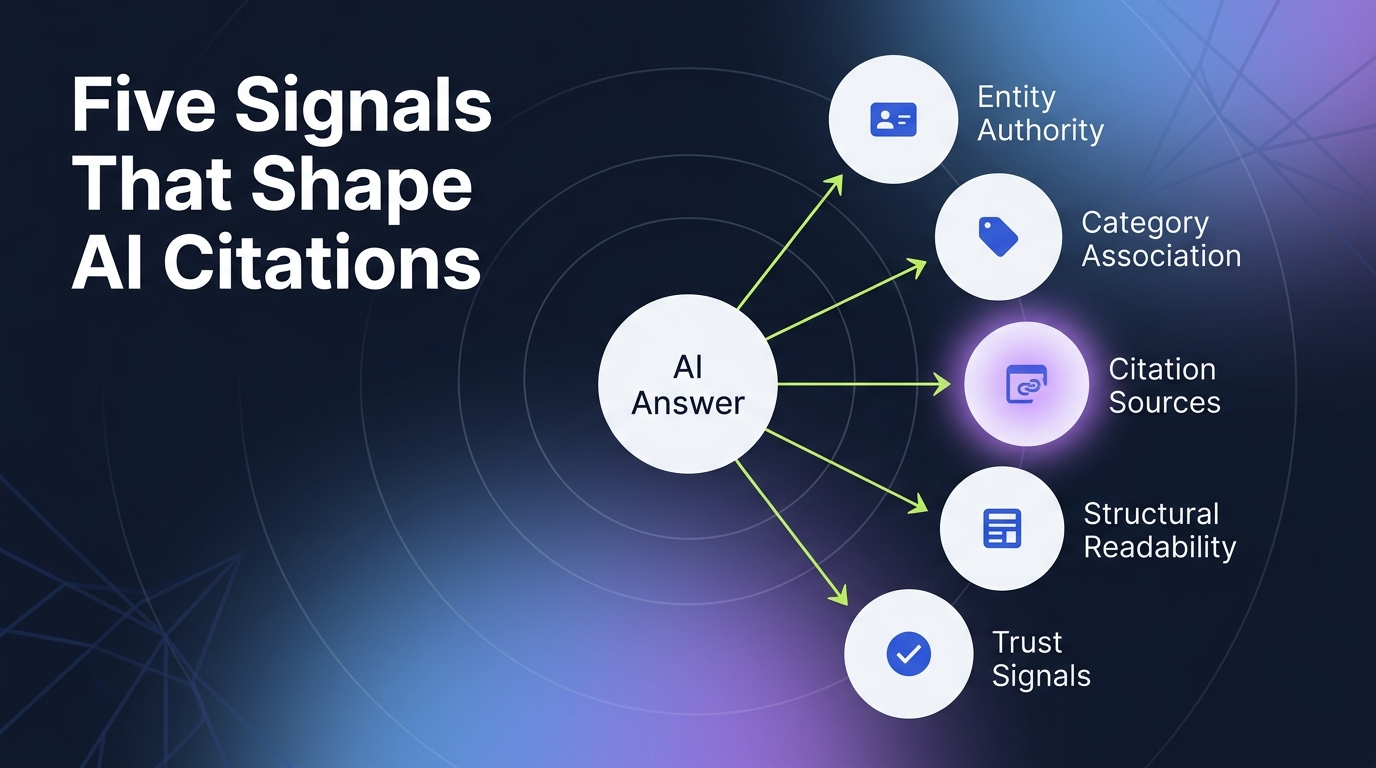
A CFO evaluating payment infrastructure in 2026 doesn’t open a browser. She opens ChatGPT, types “best B2B payment platforms for mid-market SaaS with PCI compliance,” and gets a shortlist of four vendors. If your fintech isn’t on that list, you’re not losing the deal. You’re not even in the room.
AI visibility for fintech companies is the practice of getting your brand cited, recommended, and accurately described by AI assistants like ChatGPT, Perplexity, Gemini, and Claude when buyers research financial products. It’s harder than B2B SaaS visibility because fintech is YMYL. Your Money or Your Life, which means LLMs apply stricter trust thresholds before they’ll mention your name. Regulatory proof, editorial consensus, and entity consistency aren’t nice-to-haves. They’re the ticket to the conversation.
This playbook covers what actually moves the needle: the trust hierarchy LLMs apply to fintech, the publication tiers that influence training data, the compliance boundary you can’t cross, and the 90-day execution plan for payments, lending, banking-as-a-service, and regtech brands.
What You’ll Learn
- Why fintech AI visibility operates under stricter rules than other B2B categories
- The four-layer trust hierarchy LLMs apply before recommending a financial brand
- Which publications, registries, and review sites actually feed AI training data
- The compliance boundary, what you can claim, what you can’t, and why most fintech PR fails this test
- A 90-day execution plan with milestones for payments, lending, and regtech
- How to measure citation share, accuracy, and recommendation rate across ChatGPT, Perplexity, and Gemini

Why Fintech Is the Hardest Category for AI Visibility
Every category has its own trust threshold inside LLMs. Recipe blogs have a low one. SaaS productivity tools sit in the middle. Fintech sits at the top, alongside healthcare, law, and elections, because the cost of a wrong recommendation is somebody’s money.
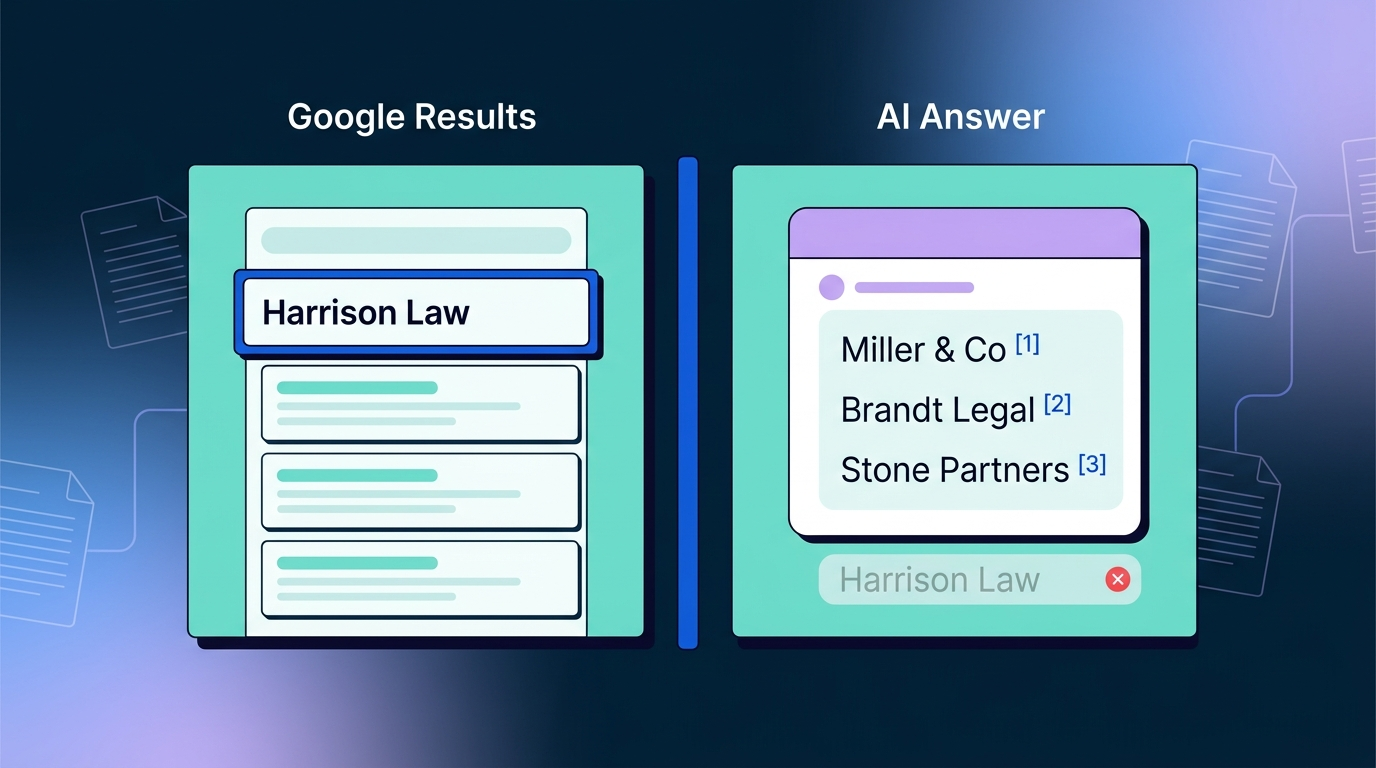
This shows up in how AI assistants behave. Ask ChatGPT for the best Slack alternatives, and you’ll get a confident list of eight. Ask it for the best business banking platform for an early-stage startup, and the answer becomes hedged, source-heavy, and weighted toward names with regulatory proof and major editorial coverage. The model is doing more verification before it speaks.
That verification draws from a narrower pool of sources. For fintech, LLMs lean disproportionately on:
- Government and regulatory registries (SEC EDGAR, FCA, FDIC, FINRA BrokerCheck, NMLS)
- Tier-1 financial press (Reuters, Bloomberg, Financial Times, Wall Street Journal)
- Trade publications with editorial standards (American Banker, Finextra, Tearsheet, Payments Dive, Fintech Futures)
- Analyst coverage (Gartner, Forrester, CB Insights, Aite-Novarica)
- Established review platforms with verification (G2, Capterra, Trustpilot for consumer-facing)
If your name doesn’t appear in those sources, repeatedly, accurately, and recently, you’re not in the consideration set. You can have the best product in your category and still be invisible.
The YMYL Penalty Is Real
Across the AI visibility audits we’ve run for fintech clients, one pattern repeats: brands with strong organic traffic and decent press coverage still see citation rates near zero in ChatGPT and Perplexity. The pages that rank on Google don’t translate. Why? Because Google’s algorithm rewards relevance and link equity, while LLMs weight regulatory and editorial signals far more aggressively in financial categories.
Translation: a great SEO program is necessary but nowhere near sufficient. You need a different input layer.
The Four-Layer Trust Hierarchy LLMs Apply to Fintech
Think of fintech AI visibility as a stack. Each layer feeds the next. Skip a layer and the layers above don’t compound.
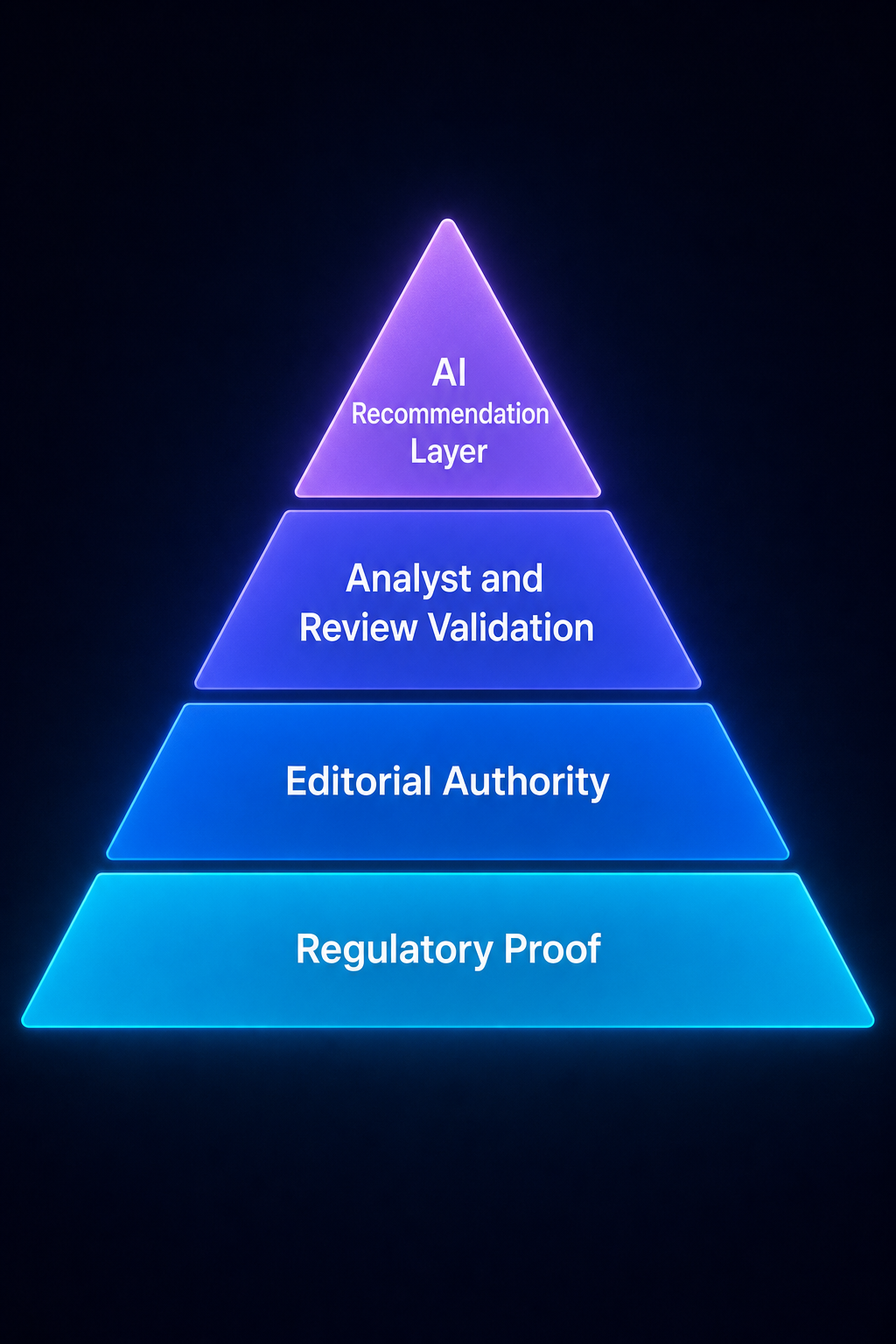
Layer 1. Regulatory Proof
This is the foundation. LLMs cross-reference brand names against public regulatory data. If your fintech is registered, licensed, or chartered, that record needs to exist where AI crawlers can find it and where editorial systems reference it.
Concrete actions:
- Make your SEC, FCA, FINRA, FDIC, NMLS, or relevant registration numbers visible on your trust or compliance page
- Publish a dedicated security and compliance page with SOC 2, PCI DSS, ISO 27001 status (with audit dates)
- List your state money transmitter licenses if you operate in payments or lending
- Mirror this data in your Wikidata entry, LinkedIn company page, and Crunchbase profile so consistency signals match
This isn’t marketing. It’s verification infrastructure for AI systems that won’t recommend a financial brand they can’t validate.
Layer 2. Editorial Authority
Once regulatory proof exists, LLMs look for editorial consensus. This is the layer most fintech teams underinvest in because traditional SEO doesn’t reward it the same way.
The editorial sources that move citation rates in fintech split into three lanes:
- Financial press: Reuters, Bloomberg, Financial Times, Wall Street Journal, Forbes, Fortune, Business Insider, Yahoo Finance
- Trade press: American Banker, Finextra, Tearsheet, Payments Dive, Fintech Futures, The Financial Brand, Banking Dive, PYMNTS
- Tech-financial crossover: TechCrunch, The Information, Wired, VentureBeat, Axios Pro Rata
You don’t need coverage in all of them. You need consistent, accurate mentions across at least two lanes over 12+ months. Repetition is what creates the brand-category association LLMs internalize.
Layer 3. Analyst and Review Validation
Analyst reports and structured review platforms add a verification layer that LLMs weight heavily for B2B fintech specifically. If Gartner names you in a Magic Quadrant, if Forrester includes you in a Wave, if CB Insights lists you in a fintech market map, those references compound.
For B2B fintech: prioritize G2 and Capterra category presence with verified reviews. For consumer fintech: prioritize Trustpilot, BBB, and category-specific review sites. The signal AI models look for is third-party verification of what your brand claims to do.
Layer 4. The AI Recommendation Layer
Once layers 1, 3 are solid, the recommendation layer becomes possible. This is where you measure whether AI assistants actually cite, mention, and recommend you for the prompts your buyers ask. Without the layers below it, this layer doesn’t form. With them, it compounds quickly.
The Compliance Boundary You Can’t Cross
Most fintech founders we work with assume the hardest part of AI visibility is getting cited. It isn’t. The hardest part is getting cited accurately, in language your compliance team will sign off on.
Fintech communications operate under regulatory regimes that ban specific claim patterns. Cross the line and you’re not just embarrassed, you’re exposed.
The patterns that get fintech brands in trouble when they show up in AI summaries:
| Forbidden Claim Pattern | Why It Fails | Compliance-Safe Alternative |
|---|---|---|
| “Guaranteed returns” / “risk-free” | SEC, FCA, and most regulators ban implied guarantees | “Historical performance” with disclosure |
| “FDIC insured” (when you’re a fintech, not a bank) | FDIC has aggressively enforced misuse since 2024 | “FDIC insurance via partner bank [name]” |
| “Best [category] for [outcome]” | Comparative claims trigger UDAAP scrutiny | Specific feature claims with proof |
| “Regulated by [unrelated agency]” | Misrepresenting your regulatory status | Name the exact registration with number |
| Implied investment advice | Triggers RIA requirements | Educational content with disclaimers |
Here’s why this matters for AI visibility specifically: when your editorial coverage uses sloppy language, LLMs absorb that language into their summaries of your brand. We’ve audited fintech brands whose ChatGPT summary started with “FDIC-insured neobank offering up to 5% APY”, neither of which was technically accurate. The journalists wrote it casually. The model parroted it. The compliance team had a heart attack.
The fix: every earned media placement, every brand mention, every analyst writeup needs to use language your compliance team has pre-approved. This is the boring, expensive, and unavoidable part of fintech AI visibility.
Subcategory Differences That Change the Playbook
Fintech isn’t one category. The visibility playbook shifts meaningfully across subcategories because regulators, publications, and buyer behavior differ.
Payments and Card Issuing
Buyers (Heads of Payments, fintech founders, ecommerce CFOs) prompt AI for “best payment processor for [vertical]” or “Stripe alternatives for [use case].” The dominant cited brands. Stripe, Adyen, Checkout.com, Marqeta, control AI mindshare through years of compounded coverage in TechCrunch, The Information, Payments Dive, and developer documentation that LLMs trained on.
For challengers: focus on vertical-specific coverage (e.g., payments for marketplaces, payments for SaaS, payments for healthcare) where Stripe’s brand gravity is weaker. Publish structured comparison content on your own site, and earn third-party mentions specifically tied to your vertical.
Lending and BNPL
Higher YMYL risk. LLMs are particularly cautious about recommending lenders. Visibility here depends heavily on:
- State licensing data clearly published
- Coverage in American Banker, Banking Dive, and Tearsheet
- Better Business Bureau rating and complaint resolution
- Trustpilot/Trustradius presence with response patterns
Neobanks and Banking-as-a-Service
The 2024, 2025 wave of FDIC enforcement actions on neobank-bank partnerships changed the language LLMs use about this category. If you’re a neobank, your AI summaries probably already include cautionary language about partner-bank deposit insurance. Audit those summaries quarterly and correct misrepresentations through accurate, repeated editorial placements.
Regtech and Compliance Software
Buyers (Chief Compliance Officers, BSA officers) trust analyst reports more than press coverage. Gartner, Chartis Research, and Aite-Novarica matter disproportionately here. G2 and Capterra category leadership compound quickly because the buying committee actually reads them.
Crypto and Digital Assets
The most volatile subcategory for AI visibility. LLMs apply extreme caution. Editorial coverage in CoinDesk and The Block helps, but mainstream financial press coverage (Reuters, Bloomberg) is what shifts AI confidence. Most crypto brands underinvest in earning that crossover coverage.

The 90-Day Execution Plan
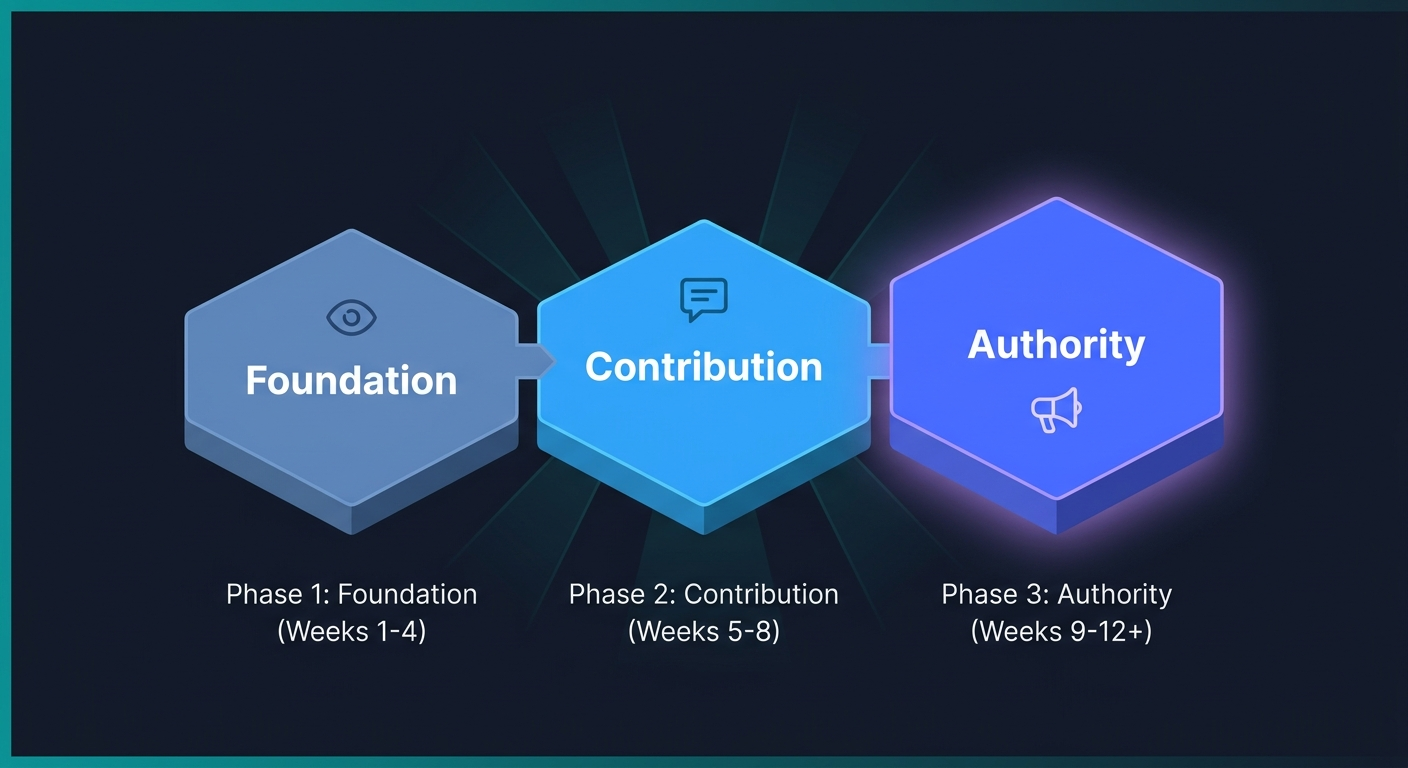
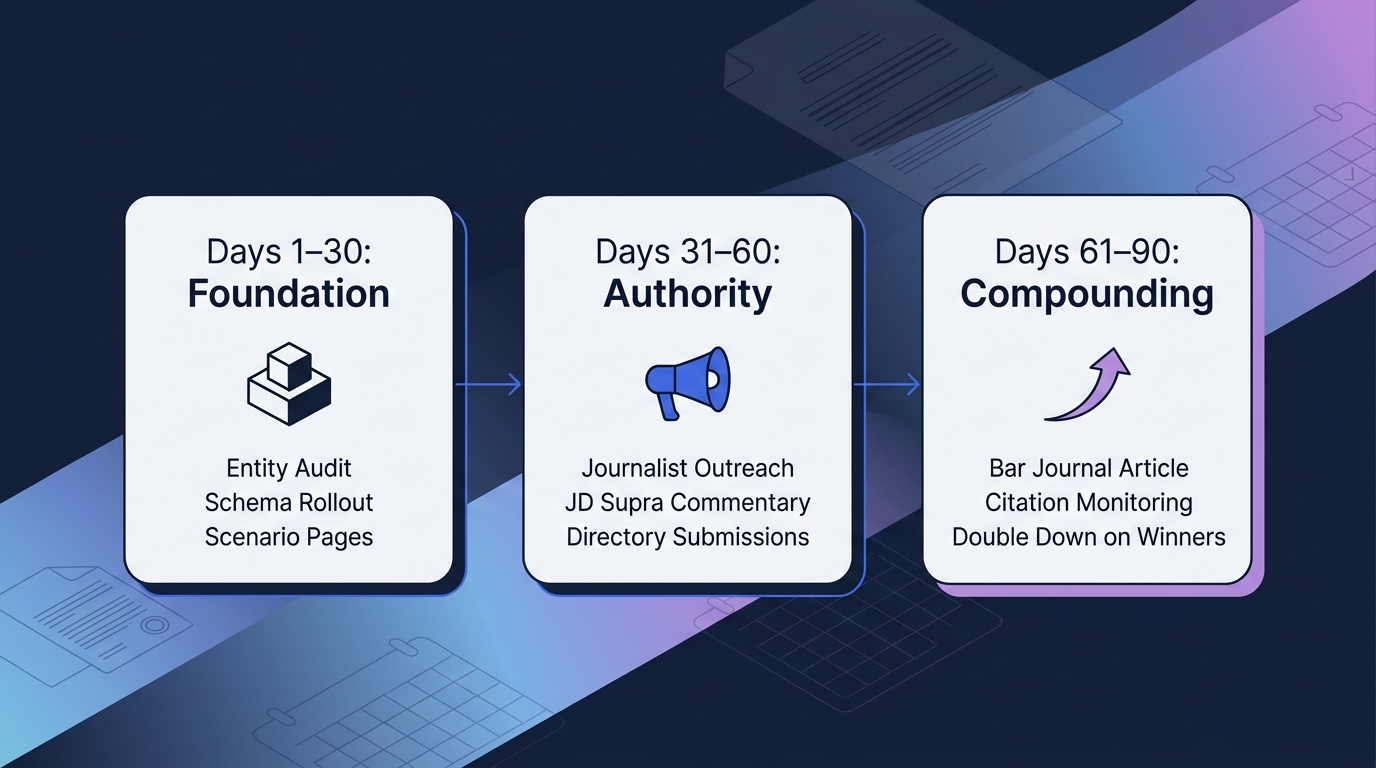
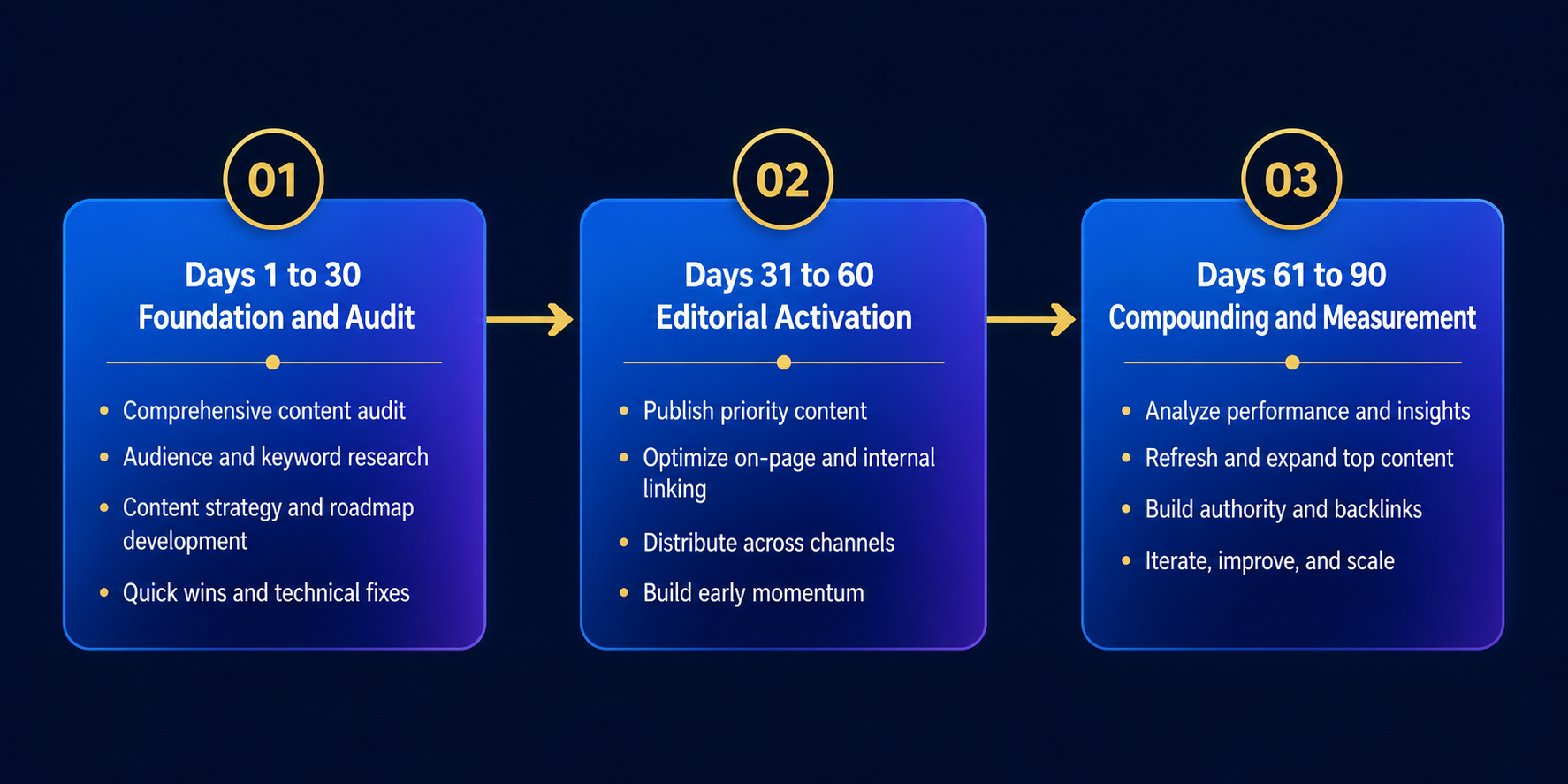
You can’t build fintech AI visibility in 30 days. You can build the foundation that produces measurable results within 90 and compounding results across 6, 12 months. Here’s the sequence.
Days 1, 30: Foundation and Audit
The first 30 days are entirely about diagnosis and infrastructure. No outreach yet.
AI Baseline Audit
Run 50+ buyer prompts across ChatGPT, Perplexity, Gemini, and Claude. Document where you appear, where you don’t, and what’s said about you. This is your starting line.
Entity Audit
Verify your brand name, founding year, headquarters, executive team, and product description match across your website, Wikipedia/Wikidata, LinkedIn, Crunchbase, G2, and any registry filings. Inconsistencies confuse LLMs.
Compliance Language Lock
Work with legal to produce a one-page approved-language sheet: how you describe your product, your regulatory status, your security posture, and your performance claims. Every external mention from this point forward uses this language.
Trust Page Build
Publish or upgrade a single page that consolidates licenses, certifications, audits, executive bios, and regulatory registrations with hyperlinks to public records.
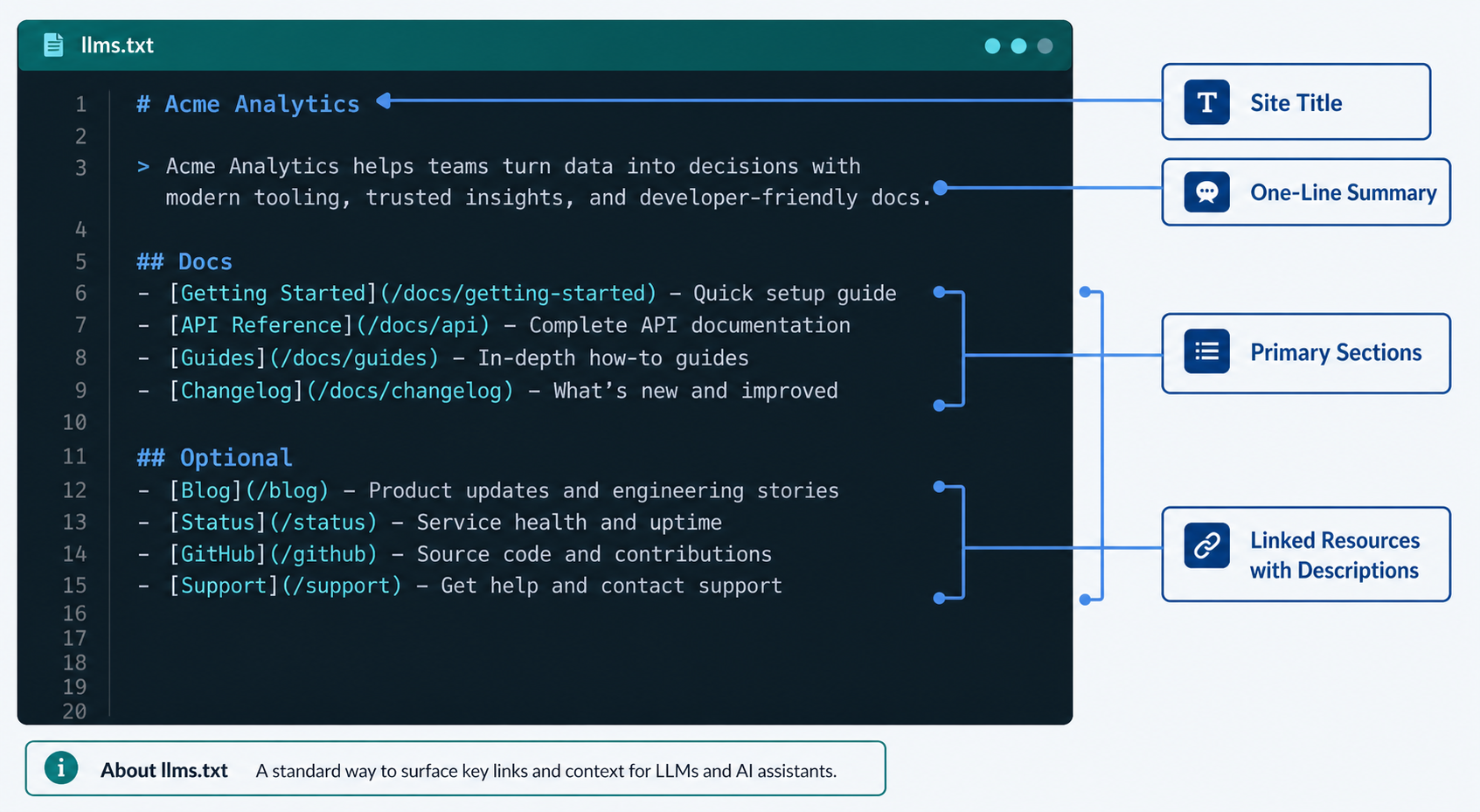
llms.txt and Structured Data
Implement Organization schema, FinancialService schema where applicable, and an llms.txt file pointing AI crawlers to your authoritative content.
Days 31, 60: Editorial and Analyst Activation
Now you push outward. The goal is two to four high-quality editorial placements and one analyst touchpoint.
Trade Press First
American Banker, Finextra, Tearsheet, Payments Dive, or your subcategory’s top trade publication. Trade press has higher accept rates than tier-1 financial press and feeds AI training data effectively.
Original Data Hook
Pitch with proprietary data, transaction volume trends, fraud pattern shifts, customer behavior insights. Data-led pitches earn coverage. Product-announcement pitches don’t.
Analyst Briefings
Book introductory briefings with Gartner, Forrester, or CB Insights analysts who cover your category. You’re not buying placement, you’re entering their awareness.
G2/Capterra Activation
If you’re B2B, drive 15, 20 verified reviews from real customers within your category page.
Days 61, 90: Compounding and Measurement
The last 30 days are about reinforcement and measuring lift.
Tier-1 Financial Press
With trade coverage in hand, pitch Reuters, Bloomberg, Forbes, or Business Insider with a sharper angle that builds on the trade narrative.
Wikipedia/Wikidata Update
If your brand has earned coverage, update or create your Wikipedia entry following neutrality and notability rules. Wikidata entries should reflect every regulatory registration and editorial reference.
Re-audit AI Assistants
Run the same 50+ prompts from Day 1. Document changes in citation rate, mention accuracy, and recommendation frequency. This is your delta.
Correction Loop
Where AI summaries are inaccurate, identify the source content driving the error and pursue corrections, either through publisher edits or by publishing authoritative counter-content.
Across the fintech AI visibility programs we’ve audited at BrandMentions, the brands that hit measurable lift in 90 days share one trait: they treated layers 1 and 2 of the trust hierarchy as parallel workstreams, not sequential ones. Compliance language locked in week one. Editorial outreach started week two. Analyst briefings booked by week three. The teams that ran these in sequence took 6+ months to see the same results.
How to Measure What’s Actually Working
Most fintech teams measure AI visibility wrong. They run a few prompts in ChatGPT, see their name, and call it a win. That’s a vanity check, not a measurement system.
Real measurement tracks four metrics across four assistants over time:
| Metric | What It Measures | Why It Matters |
|---|---|---|
| Citation Share | % of relevant prompts where you appear among recommended brands | Direct proxy for shortlist inclusion |
| Mention Accuracy | % of mentions that describe your brand correctly | Inaccurate mentions can hurt more than no mentions |
| Recommendation Position | Where in the list you appear (1st, 3rd, 7th) | Top 3 captures most buyer attention |
| Source Attribution | Which publications LLMs cite when explaining you | Reveals which editorial work is paying off |
Run this measurement quarterly. Track deltas, not absolutes. The brands compounding fastest aren’t the ones with highest citation share, they’re the ones improving every quarter on all four dimensions.
Fintech AI visibility is measured across four metrics: citation share, mention accuracy, recommendation position, and source attribution. Run 50+ buyer-relevant prompts across ChatGPT, Perplexity, Gemini, and Claude each quarter. Track deltas, not absolutes, the goal is consistent improvement across all four dimensions.
The Mistakes Costing Fintech Brands Their AI Mindshare
Across the fintech AI visibility audits we’ve completed, the same mistakes keep showing up. None of them are exotic. All of them are fixable.
Treating AI Visibility as an SEO Project
The team that owns rankings doesn’t have the relationships, compliance fluency, or editorial chops to drive citation programs. This needs cross-functional ownership between marketing, PR, and compliance.
Pitching Product Launches
Journalists don’t cover fintech product launches anymore. They cover trends, data, and category shifts. Lead with what’s changing in the market, not with what you built.
Ignoring Trade Press
Founders chase Forbes and skip American Banker. American Banker drives more AI citation lift in B2B fintech than Forbes does, because LLMs weight category-specific authority.
Inconsistent Entity Data
Your LinkedIn says you were founded in 2019. Crunchbase says 2018. Wikidata is missing. AI assistants notice.
Skipping the Compliance Language Lock
Earning coverage with sloppy claims is worse than earning no coverage. The bad language compounds in AI summaries for years.
Measuring Once and Stopping
AI visibility is a moving target. Quarterly re-audits aren’t optional.
Fintech compliance constraints reshape which analytics tools you can actually use. The AI visibility analytics review flags which platforms meet SOC 2 and data-residency requirements out of the box.
Related: AEO for fintech compliance · AI visibility for B2B SaaS · AI visibility for enterprise software
Frequently Asked Questions
How long does it take to see AI visibility lift for a fintech brand?
Most fintech brands see measurable lift in citation share within 90 days if regulatory proof and entity consistency are already in place. If those foundations are missing, expect 5, 7 months before editorial work starts compounding. The variable that compresses the timeline most is whether your compliance team can approve language quickly.
Which AI assistant matters most for fintech buyers?
ChatGPT drives the largest share of buyer research prompts in fintech, followed by Perplexity for B2B technical evaluations and Gemini for buyers already inside Google Workspace. Claude matters most in regulated enterprise contexts. Track all four, the citation patterns differ meaningfully across them.
Do AI assistants actually trust trade publications more than tier-1 press?
For category-specific recommendations, yes. When ChatGPT explains why a particular payments platform is good for marketplaces, it leans on Payments Dive and PYMNTS more than on Forbes. Tier-1 press builds general brand authority. Trade press drives category-specific recommendation behavior.
Can I get cited by AI assistants without earned media?
Theoretically yes, through proprietary data publication, authoritative documentation, and developer-facing content. Practically no, because YMYL guardrails in fintech mean LLMs want third-party validation. Stripe’s documentation drives some citations, but Stripe also has 13 years of compounded earned coverage. New brands can’t replicate that with owned content alone.
What about AI visibility for fintech startups with no press coverage yet?
Start with the layers you control: regulatory proof page, entity consistency across LinkedIn/Crunchbase/Wikidata, structured data, and llms.txt. Then earn 2, 3 trade publication mentions before pursuing tier-1 press. Trying to skip to Forbes without trade coverage is the most common startup mistake, and it almost never works.
How do I correct inaccurate information AI assistants are saying about my fintech?
Trace the source. AI hallucinations in fintech usually trace back to one or two pieces of inaccurate or outdated coverage that the model trained on. Identify those sources, pursue publisher corrections where possible, and publish authoritative content (data pages, trust pages, leadership bios) that gives the model better signal. Over the next 1, 2 training cycles, the corrected information replaces the old.
Does Wikipedia matter for fintech AI visibility?
More than for most categories. Wikipedia and Wikidata feed structured entity data that AI assistants weight heavily for YMYL topics. If your fintech meets notability standards, a well-maintained Wikipedia entry with proper citations is one of the highest-ROI moves available. If you don’t meet notability yet, focus on earning the editorial coverage that will support an entry later.
What Comes Next for Fintech AI Visibility
The fintech brands that will own AI mindshare in 2027 are running their citation programs now, in 2026. The ones still treating this as an experiment will spend 2027 trying to catch up, and the gap will be wider than they expect. AI visibility compounds, first slowly, then suddenly. The brands that built editorial authority in 2026 and 2025 are already pulling away.
Audit your AI visibility this quarter. Run 50 buyer prompts across the four major assistants, document where you stand, and start the 90-day plan. The compounding starts the day you do.
Get a free AI visibility audit for your fintech brand, we’ll show you where you stand across ChatGPT, Perplexity, Gemini, and Claude, and what’s driving the gap.