Enterprise software buyers stopped trusting vendor websites years ago. In 2026, they ask ChatGPT, Perplexity, and Gemini before they ever talk to sales, and the brands those models recommend already won the deal before the RFP went out. If your $200K ACV product isn’t in the consideration set when a Fortune 1000 buyer types “best enterprise data observability platform,” you’re not losing on price or features. You’re losing on visibility. AI visibility for enterprise software is the discipline of ensuring large language models cite your product as a credible option when buyers research solutions in your category. It’s harder than B2B SaaS visibility because procurement, security, and compliance signals factor heavily into how AI models weigh enterprise vendors, and most companies have built none of them in a way machines can read.
What You’ll Learn
- Why enterprise software has a unique AI visibility problem, and what makes it different from B2B SaaS or DevTools
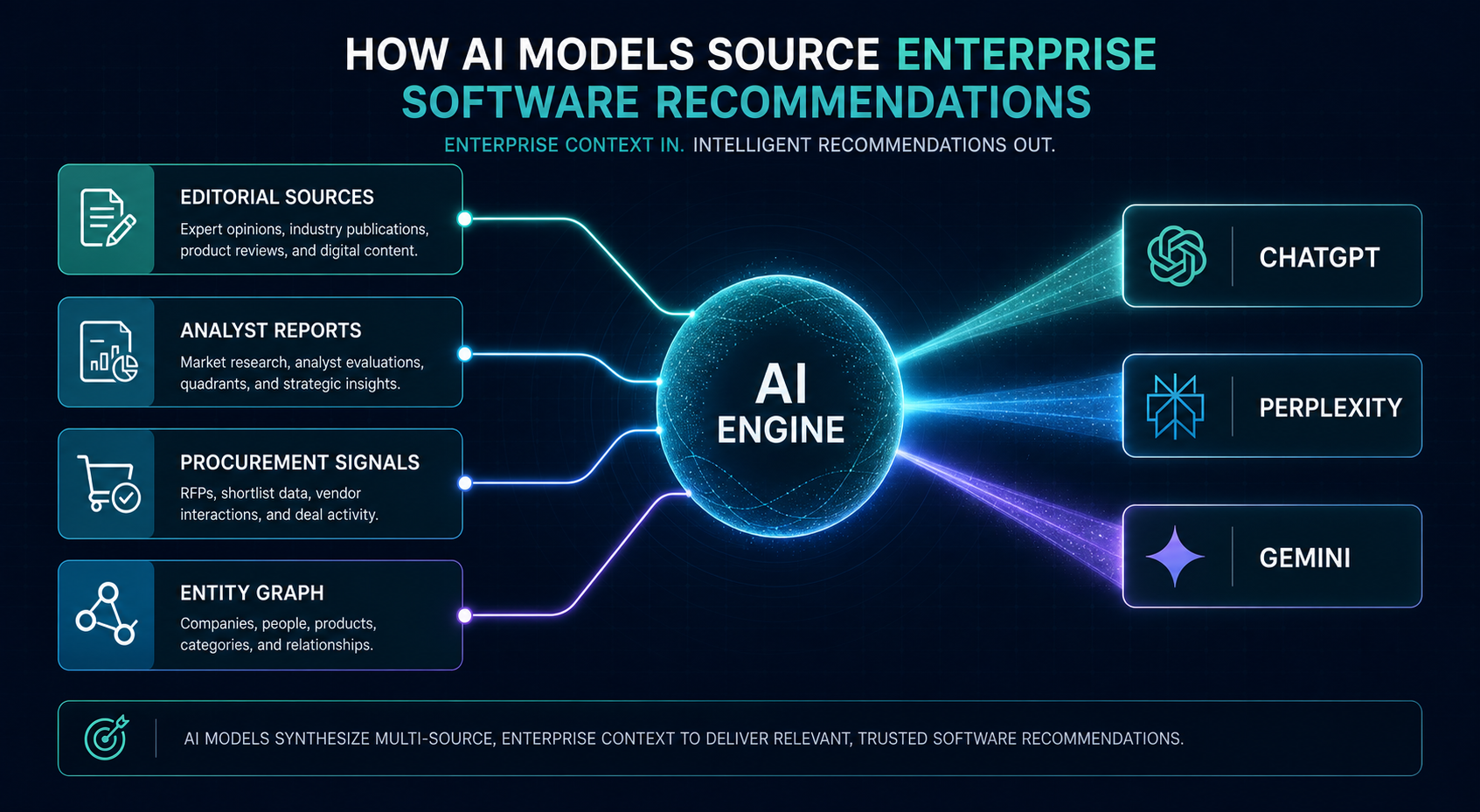
- The four signal layers AI models use to weight enterprise vendors: editorial, analyst, procurement, and entity
- How to audit your current AI citation rate across ChatGPT, Perplexity, Gemini, and Copilot in under 90 minutes
- The procurement-grade content gaps that block enterprise visibility (and how to close them)
- What to measure quarterly so your CMO and CRO see AI visibility as pipeline infrastructure, not a marketing experiment
Why Enterprise Software Has a Different AI Visibility Problem
B2B SaaS visibility playbooks assume the buyer is one person making a $5K, $50K decision. Enterprise software doesn’t work that way. A $500K platform sale involves a champion, an economic buyer, a technical evaluator, a security reviewer, and a procurement lead, and each one asks AI different questions at different stages.
| Signal layer | What it is | Buyer it answers | How enterprise vendors build it |
|---|---|---|---|
| Editorial | Independent coverage, reviews, and category articles that mention your product as a credible option | The champion (“best alternatives to [incumbent]”) | Earn mentions in third-party publications and category comparisons buyers and models already trust |
| Analyst | Recognition in analyst evaluations and category research that models treat as authoritative | The economic buyer evaluating the category | Get represented in analyst reports and named in the vendor landscape for your category |
| Procurement | Machine-readable security, compliance, and pricing facts (e.g., SOC 2, HIPAA, typical enterprise pricing) | The security reviewer and procurement lead | Publish procurement-grade content stating certifications, compliance scope, and pricing clearly |
| Entity | A consistent, structured definition of your company that models can resolve and connect | The technical evaluator confirming who you are | Keep your company described the same way across the sources models read so they resolve you as one clear entity |
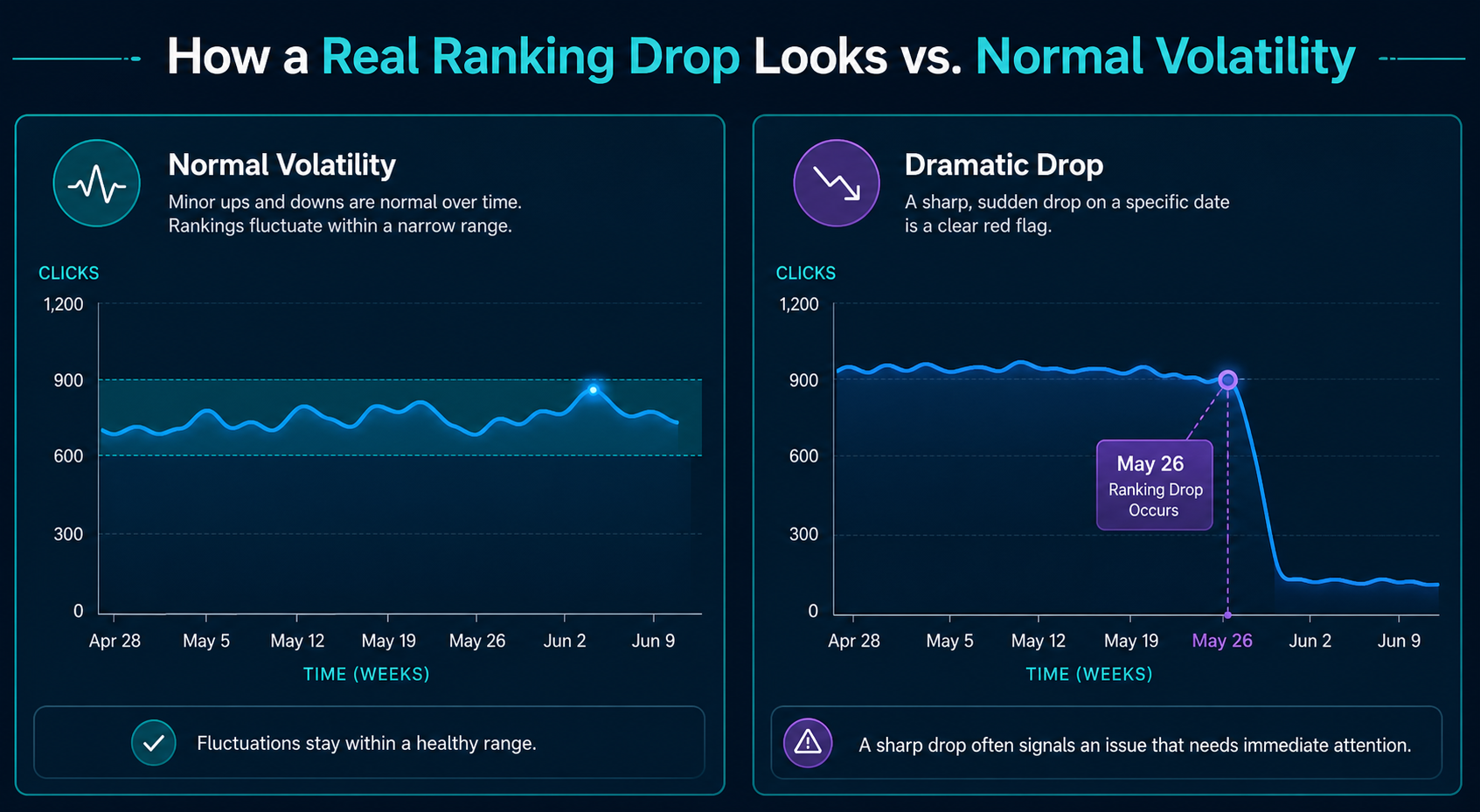
The champion asks “best alternatives to Snowflake for healthcare data.” The security reviewer asks “is Databricks SOC 2 Type II compliant for HIPAA workloads.” The procurement lead asks “typical enterprise pricing for cloud data warehouses.” If your brand only surfaces for one of these queries, you’re invisible at three of the five touchpoints that actually decide the deal.
That’s the structural problem. Enterprise software needs visibility across a wider query surface, and across query types that consumer-grade content rarely satisfies. AI models won’t cite your blog post about “10 reasons to choose our platform” when a CISO asks about compliance posture. They’ll cite the Gartner Magic Quadrant, the G2 Enterprise Grid, the analyst report your competitor sponsored last quarter, and the practitioner thread on Stack Overflow where your product never appeared.
This is the gap. And it’s why enterprise software vendors with strong G2 reviews and decent SEO still get zero AI citations for high-intent enterprise queries. The inputs AI models trust for enterprise decisions are different from the inputs they trust for SMB decisions. Most marketing teams haven’t adjusted.
The Four Signal Layers AI Models Weight for Enterprise Vendors
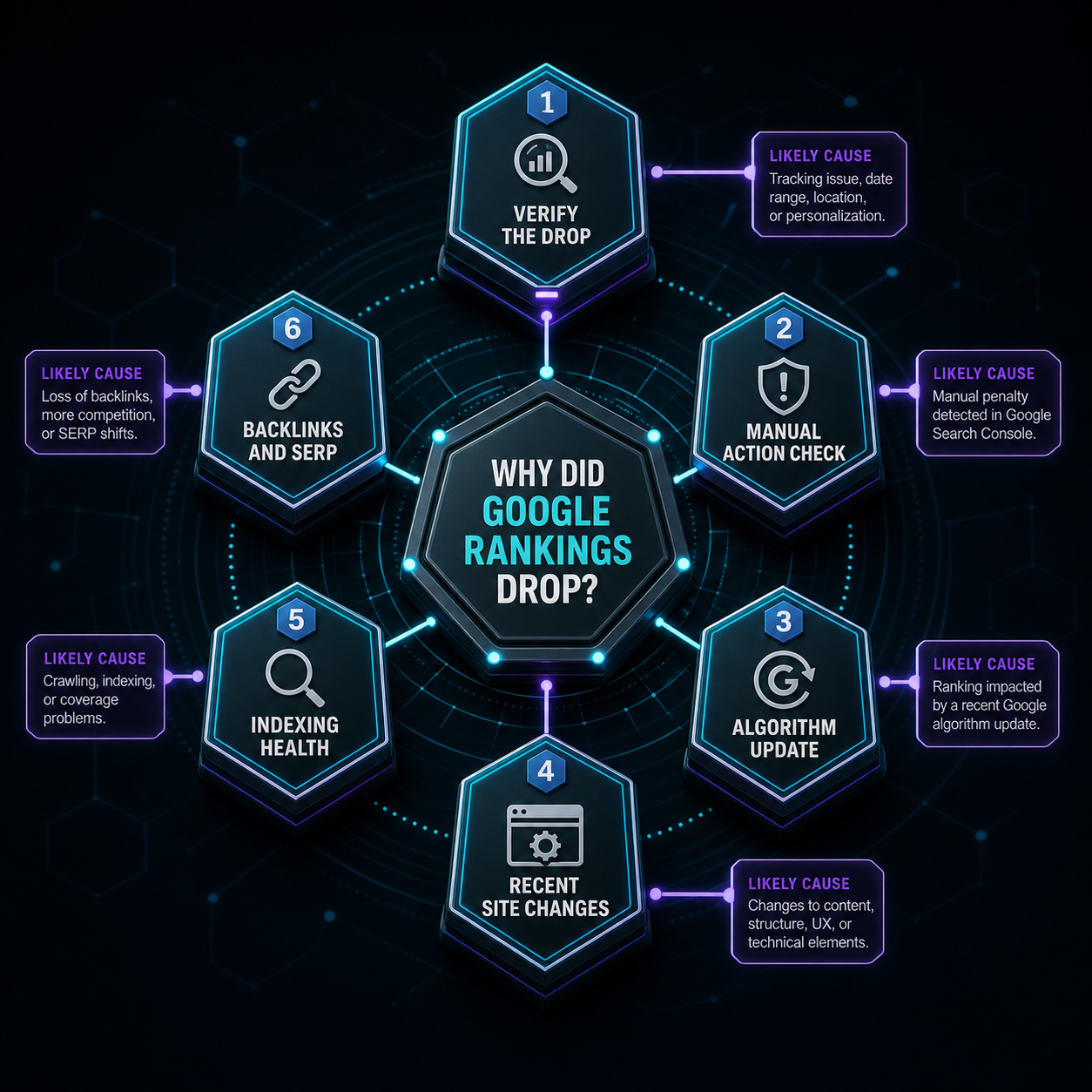
After running visibility audits across hundreds of B2B software brands, four signal categories consistently determine whether an enterprise vendor gets cited:
- Editorial signals, coverage in tier-1 trade publications (TechCrunch, The Information, Protocol, sector-specific outlets), executive bylines on industry sites, and original research that other publications cite back.
- Analyst signals, placement in Gartner, Forrester, IDC, and G2 Enterprise Grid reports. AI models index analyst content heavily because it’s structured, dated, and treated as third-party validation.
- Procurement signals, public pricing tiers, SOC 2/ISO 27001/HIPAA documentation, transparent SLAs, and case studies with named Fortune 1000 customers. These signal “enterprise-ready” to models trained on procurement workflows.
- Entity signals. Wikipedia presence, Crunchbase entity data, LinkedIn company size and growth signals, and consistent NAP across knowledge graph sources. Without entity confirmation, AI models hedge or omit your brand entirely.
A vendor strong in two of these layers gets cited occasionally. Strong in three gets cited consistently. Strong in all four gets recommended by default, which is the only position that matters when a $1M deal starts with an AI query.
How to Audit Your Current AI Visibility in Under 90 Minutes
Before fixing anything, you need a baseline. Here’s the audit we run before any enterprise engagement. It takes about 90 minutes and requires no tooling beyond a free account on each AI platform.
Step 1: Build Your Query Matrix (20 minutes)
List 15 queries across five buyer roles. For each role, write three queries, one early-stage (“what is data observability”), one comparative (“Datadog vs Splunk for enterprise logs”), and one high-intent (“best enterprise APM platform with HIPAA compliance”). The mix matters. Visibility on early-stage queries means nothing if you’re invisible when buyers are ready to act.
Step 2: Test Across Four Engines (40 minutes)
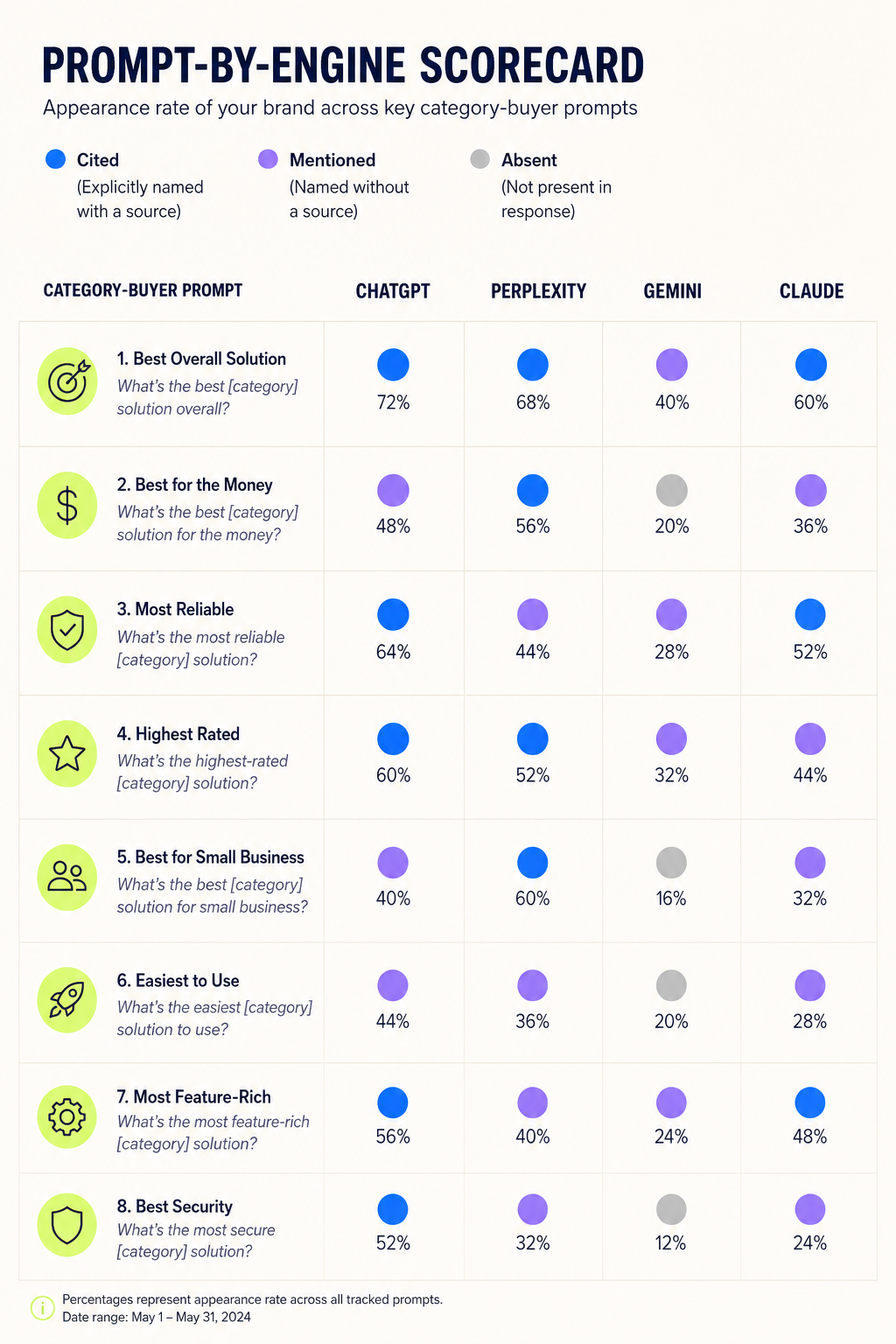
Run every query in ChatGPT (with browsing on), Perplexity, Gemini, and Microsoft Copilot. Record three data points per query: (1) does your brand appear, (2) what position in the response, (3) which sources the AI cited to justify the recommendation.
That third data point is the one most teams skip. It’s also the most valuable. If Perplexity cited G2, a Forrester Wave, and a TechCrunch piece, none of which mention your product, you now know exactly which sources to target.
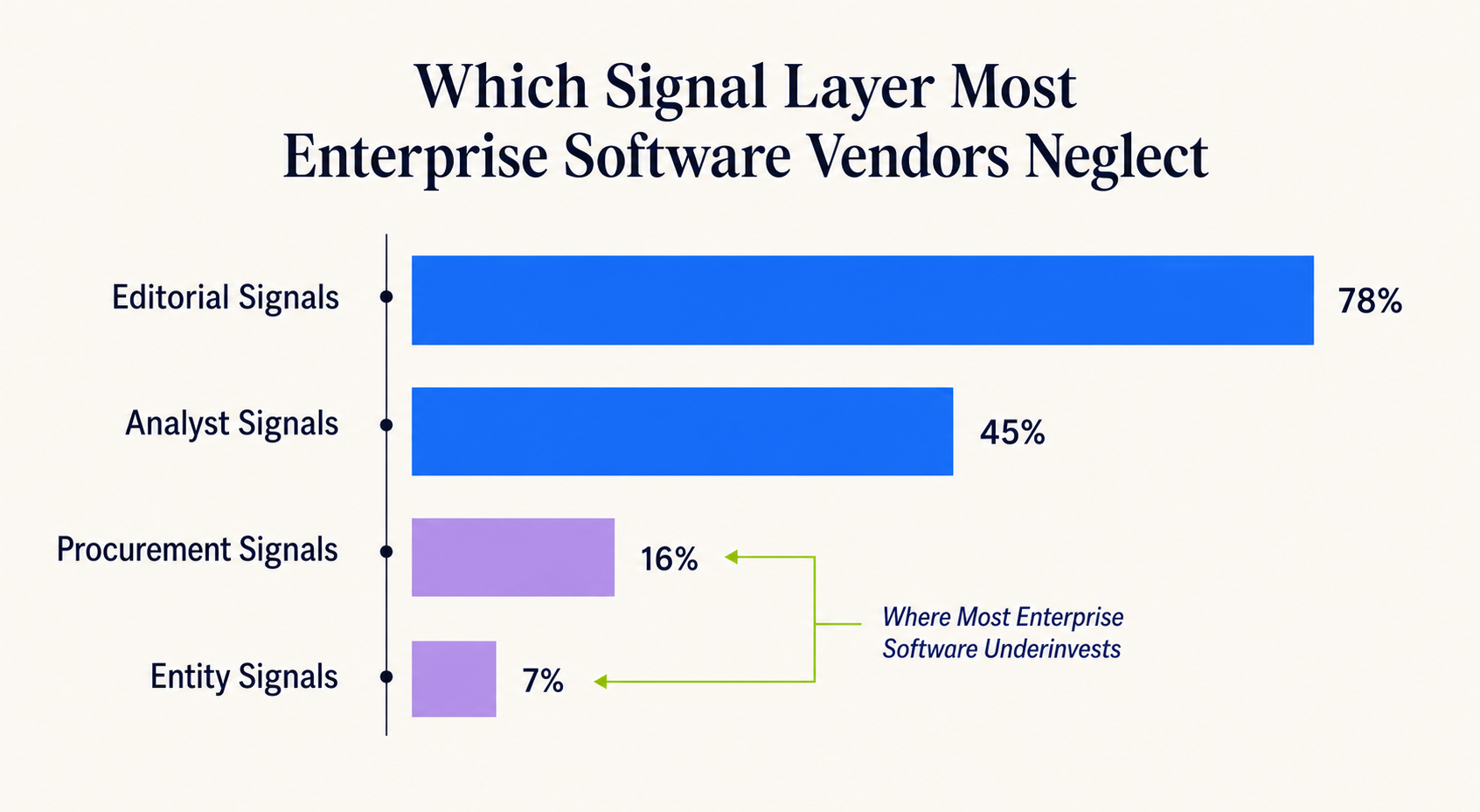
Step 3: Score Citation Rate and Source Gaps (20 minutes)
Calculate two numbers. Citation rate = queries where your brand appeared ÷ total queries. Source gap rate = cited sources where you’re absent ÷ total cited sources. Most enterprise software vendors we audit score under 20% on citation rate and over 80% on source gap rate. Those numbers are your starting line.
Step 4: Identify the Highest-use Sources (10 minutes)
Sort the cited sources by frequency across your 15 queries. The sources cited most often are your highest-use targets. If G2 is cited in 11 of 15 queries and you have 12 reviews while your competitor has 340, that’s not an AI visibility problem you’ll solve with blog content. That’s a review acquisition problem masquerading as one.
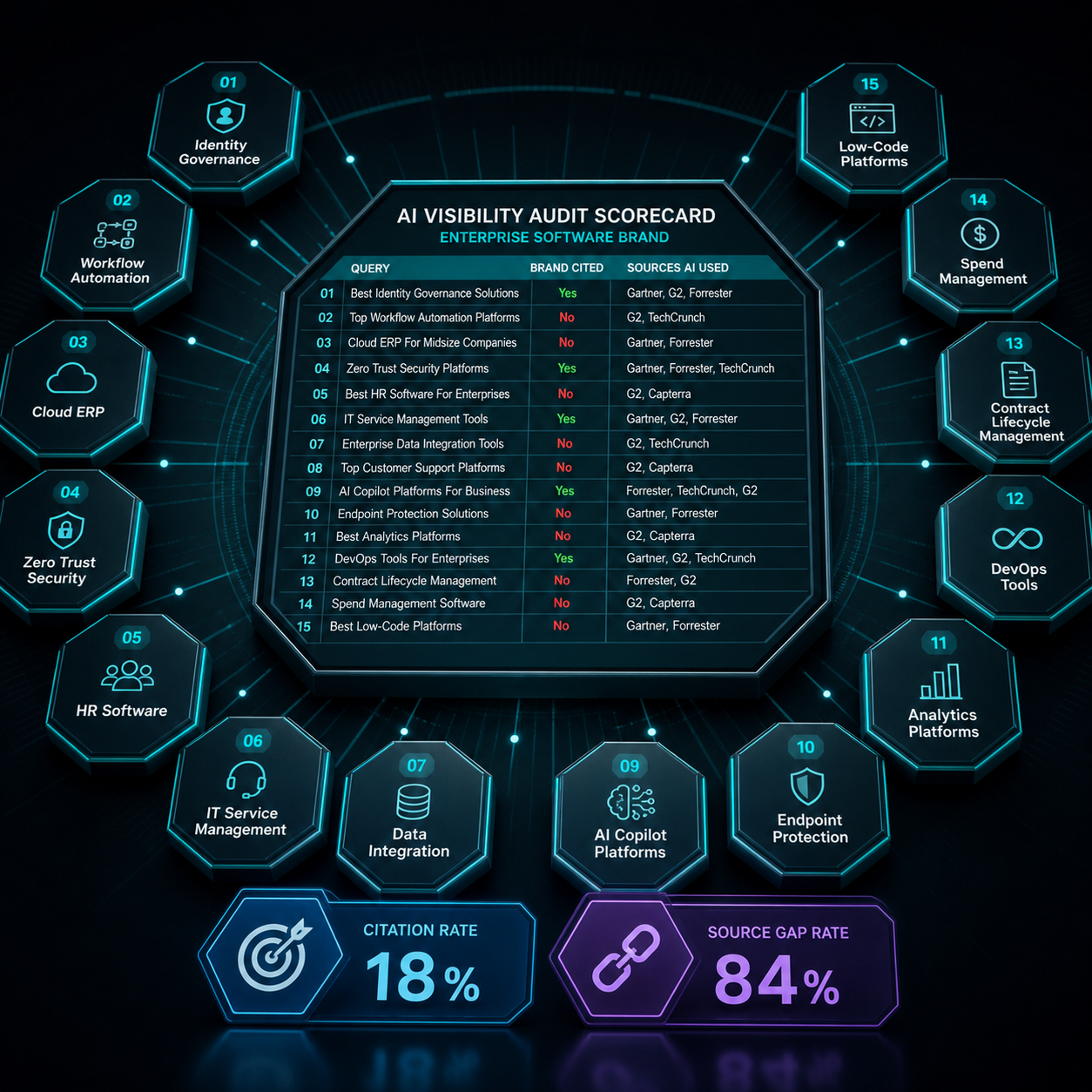
The audit output is a ranked list of fixable gaps. You can run it again every quarter and watch the citation rate climb as you close them.
Closing the Procurement-Grade Content Gaps
Once you’ve audited, the work splits into two streams: content you control and signals you earn. Most enterprise software teams over-invest in the first and ignore the second. That’s backwards. AI models weight earned third-party signals more heavily than owned content for enterprise queries, because procurement decisions are too high-stakes for models to recommend based on self-published claims.
But owned content still matters in one specific way: it needs to be machine-readable enough for AI to extract procurement-grade facts. That means structured, dated, and specific.
What Procurement-Grade Content Looks Like
Take a security page. Most enterprise software vendors have a page that says “We take security seriously. We’re SOC 2 compliant and follow industry best practices.” That sentence tells an AI model nothing it can cite back.
A procurement-grade version reads: “Acme is SOC 2 Type II audited annually by Schellman, with our most recent report covering January 2026 through December 2026. We maintain ISO 27001:2022 certification (certificate number XXXXX, valid through March 2027) and offer HIPAA Business Associate Agreements for healthcare customers on Enterprise plans.”
The second version is extractable. An AI model asked “is Acme SOC 2 compliant” can cite the specific report period. Asked about HIPAA, it can confirm the BAA availability and the plan tier. This is what “answerable content” means at the enterprise tier, and it’s the foundation of scalable AI visibility for B2B software.
The Five Pages Every Enterprise Software Site Needs
- Security & compliance page with specific certifications, dates, audit firms, and customer-grade documentation
- Pricing tier page with enough specificity that AI can answer “what does enterprise tier include”, even if exact prices are gated
- Integration directory listing every supported system with version compatibility and authentication method
- Customer page with named enterprise logos, industry verticals served, and case studies tied to measurable outcomes
- Comparison pages for your top 5 named competitors, written with intellectual honesty, not feature-bait
Each of these pages exists to give AI models extractable facts when buyers ask procurement-level questions. The absence of any one of them is a citation gap your competitors will fill.
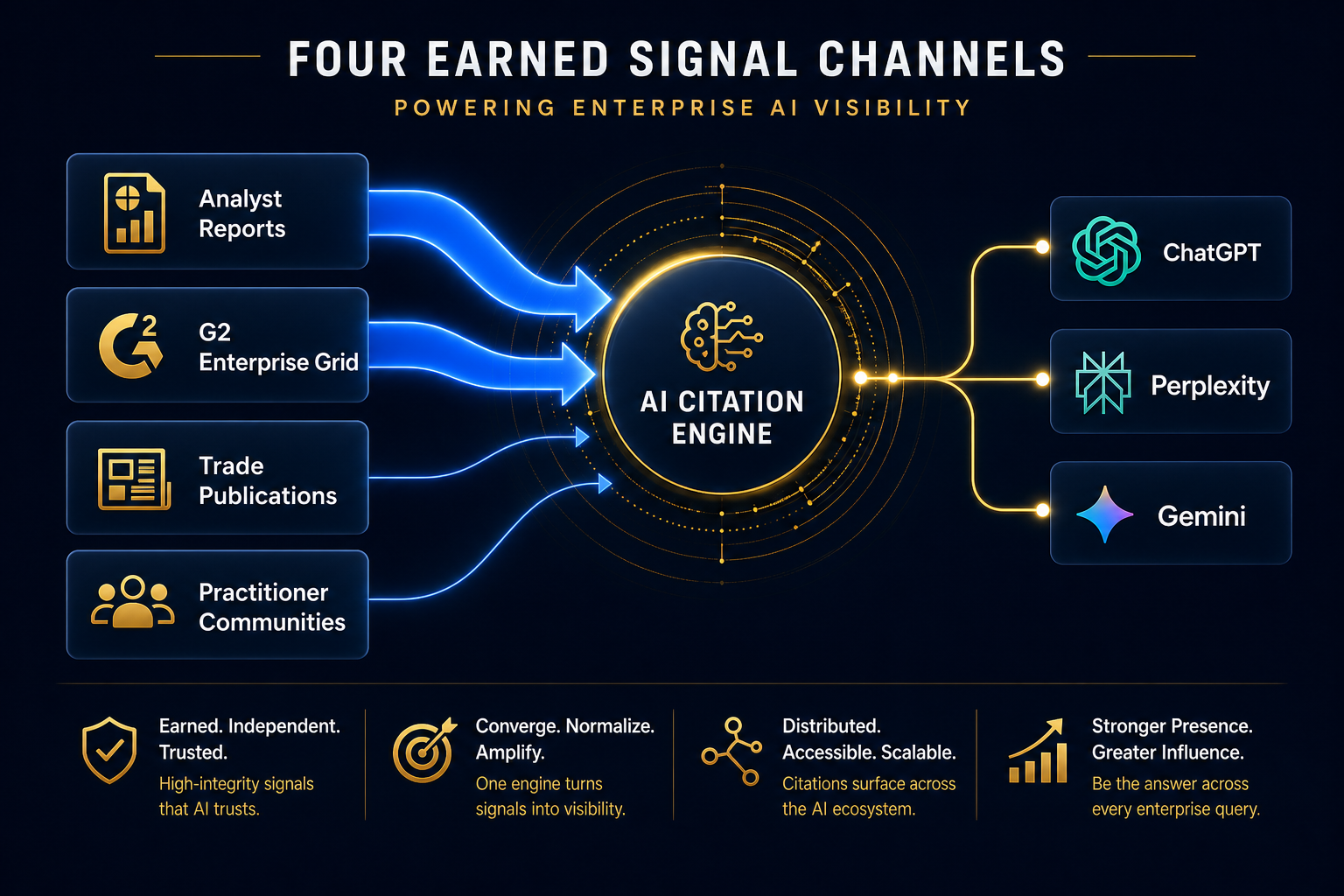
Earning the Signals You Don’t Control
The harder work is on the earned side. AI models cite Gartner, Forrester, G2, TechCrunch, and tier-1 trade press because those sources have editorial standards and were indexed during training in ways that mark them as authoritative. Your blog post, no matter how good, won’t substitute.
For enterprise software, four earned channels move the needle:
Analyst Briefings That Translate to Reports
Gartner, Forrester, and IDC analysts publish reports AI models heavily index. If you’re not in the Magic Quadrant, the Wave, or the MarketScape for your category, you’re invisible to AI in any query where analyst context drives the answer. Budget for analyst relations the same way you budget for paid media. The reports compound for years.
G2 Enterprise Grid Placement
G2 is cited in roughly 70% of B2B software AI responses we’ve measured. The Enterprise Grid (filtered to companies over $1B revenue) is what matters for enterprise queries. That requires reviews from actual enterprise users, not SMB customers padding your overall rating.
Tier-1 Trade Publication Coverage
Earned coverage in publications AI models trust, not press release distribution. The Information, Protocol, TechCrunch’s enterprise vertical, sector-specific trades like Healthcare IT News or FinTech Futures. One substantive feature outperforms 50 syndicated press releases. This is the kind of editorial coverage that compounds over time.
Practitioner Communities Where Buyers Verify
Reddit’s r/sys****SECRET_REDACTED****, r/devops, r/cybersecurity, and Stack Overflow tags for your category. Enterprise buyers cross-check AI recommendations against practitioner discussions. If those threads don’t mention your product, or worse, mention it negatively. AI models notice. The Reddit authority playbook matters more for enterprise software than most teams realize, because technical buyers verify there first.
The Entity Layer Most Enterprise Teams Forget
The fourth signal layer, entity confirmation, is where I see the most preventable losses. AI models need to confirm your company exists, what category it operates in, who founded it, and roughly how large it is. If they can’t confirm these basics from authoritative entity sources, they hedge or omit you from recommendations entirely.
The entity sources that matter for enterprise software:
- Wikipedia, even a stub page dramatically increases citation confidence
- Crunchbase, funding, headcount, leadership data structured for machine consumption
- LinkedIn, company size, growth trajectory, employee technical skills
- Google Knowledge Panel, the public-facing entity confirmation
- Wikidata, the underlying structured data that powers knowledge graphs
Most enterprise software companies have inconsistencies across these sources, different founding dates, different headcount ranges, different category descriptions. Each inconsistency is friction. Cleaning up entity data is the lowest-cost, highest-use AI visibility work most teams haven’t done. This is foundational entity SEO work that compounds across every AI surface.
Measuring What Matters Quarterly
Enterprise CMOs don’t want another vanity metric. The measurement frame that survives executive scrutiny tracks three numbers:
- Citation rate, percentage of your tracked query matrix where your brand appears. Track per engine. Target 60%+ on high-intent queries within 12 months.
- Share of recommendation, when AI lists multiple options, where do you rank? Position 1, 3 is the only one that matters; positions 4+ rarely convert to consideration.
- Source coverage, percentage of AI-cited sources where your brand has presence. This is the leading indicator. Citation rate follows source coverage with a lag of 60, 120 days.
Report these quarterly to the CRO. Tie them to pipeline influence by tracking AI-referred traffic through GA4 and pipeline conversion rates on AI-sourced leads. The pattern we see: AI-referred leads close at 2, 3x the rate of paid search leads because the AI did the qualification work upfront.
A Realistic Timeline for Enterprise Visibility
Entity cleanup shows results within 30 days. Owned content updates move citation rates in 60, 90 days. Earned signals, analyst reports, G2 enterprise reviews, trade press, compound on a 6, 12 month curve. Anyone selling you 30-day enterprise AI visibility results is selling you something else.
The brands winning enterprise software AI visibility in 2026 started this work in late 2024 and early 2025. The brands starting now are competing for 2027 positioning. That’s the actual timeline.
Enterprise software brands need analytics that scale across product lines. The platform comparison for AI visibility analytics covers which tools handle multi-product portfolios without dashboard sprawl.
Frequently Asked Questions
How is AI visibility for enterprise software different from B2B SaaS?
Enterprise software requires visibility across more buyer roles and more query types, particularly procurement, security, and compliance queries that B2B SaaS rarely faces. AI models weight analyst reports, named enterprise customer references, and structured compliance documentation more heavily for enterprise vendors than for SMB-focused software. The signal mix shifts from “G2 reviews and content marketing” to “Gartner placement, enterprise case studies, and procurement-grade documentation.”
Which AI engines should enterprise software brands prioritize?
ChatGPT and Perplexity drive the most buyer research traffic, with Microsoft Copilot growing fast inside enterprise environments where it’s the default assistant. Gemini matters because of Google Workspace penetration. Prioritize by where your specific buyers actually work, if you sell to financial services, Copilot inside Microsoft 365 matters more than consumer ChatGPT.
Do we still need traditional SEO if we focus on AI visibility?
Yes. AI models heavily cite content that ranks well in traditional search, especially for technical queries. Strong SEO is now a precondition for AI visibility, not a replacement for it. The strategy is integrated, content built for citation extraction also tends to rank, and content that ranks gets cited more often.
How long before we see results from an enterprise AI visibility program?
Entity cleanup and structured content updates show movement in 30, 90 days. Earned signals, analyst reports, tier-1 press, enterprise reviews, show up in citation rates over 6, 12 months. Most enterprise software brands see citation rates double in 6 months and quadruple in 12 if they execute across all four signal layers.
What’s the single biggest mistake enterprise software teams make with AI visibility?
Treating it as a content marketing problem. AI visibility for enterprise software is 30% content, 70% earned signals and entity infrastructure. Teams that pour budget into blog content and ignore analyst relations, G2 enterprise reviews, and entity cleanup get marginal returns. The teams that win invert that ratio.
How do we measure ROI on AI visibility for enterprise deals?
Track AI-referred traffic in GA4, tag those visitors as a discrete lead source, and measure pipeline conversion and close rates against other channels. Most enterprise software teams find AI-referred leads convert at 2, 3x the rate of paid search because buyers arrive already qualified. The reporting frame that lands with CFOs: pipeline influenced divided by program cost, tracked over rolling 12-month windows.
Should we build this in-house or work with a specialized agency?
The entity cleanup and content restructuring can be in-house if you have a technical SEO lead who understands schema, knowledge graphs, and citation mechanics. The earned signal work, analyst relations, G2 enterprise programs, tier-1 press, typically requires either dedicated specialists or a partner with established relationships. The most expensive mistake is having a content team try to manage analyst relations on the side.
The Window Is Closing Faster Than You Think
Enterprise buyers consulted AI for a quarter of their software research in early 2025. By late 2026, the number is closer to two-thirds and climbing. The brands that built citation infrastructure in 2026, 2025 are now the default recommendations for their categories, and displacing a default takes years of investment, not months. If your enterprise software brand isn’t yet showing up when buyers ask AI for recommendations, the right move isn’t to panic. It’s to run the audit this week, identify the three highest-use gaps, and start closing them quarter by quarter. The compounding starts the day you begin. Want help mapping your current AI visibility against your top three competitors? Request an AI visibility audit and we’ll send back a ranked fix list within 10 business days.