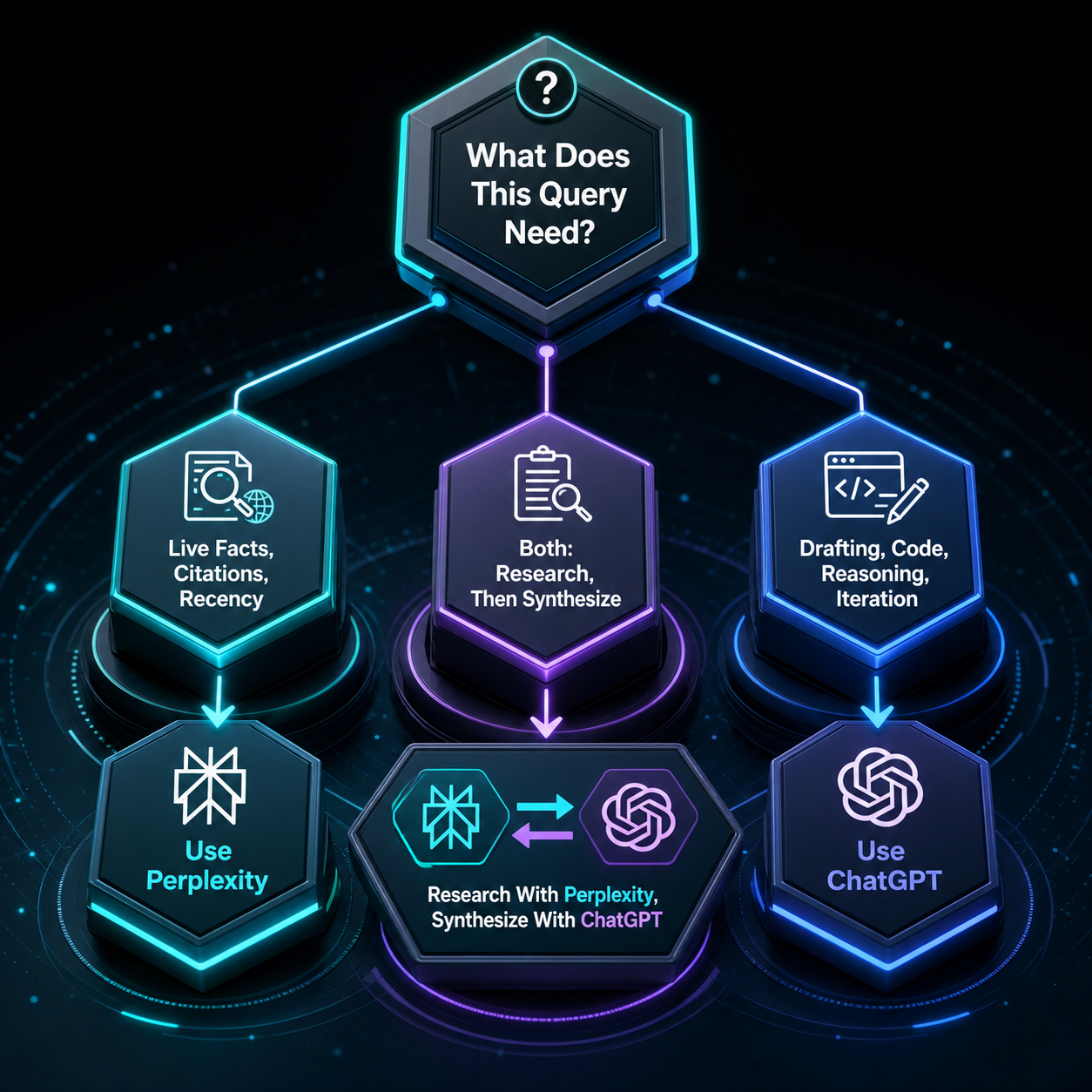
Quick answer: Pick Perplexity when you need cited answers from the live web. Pick ChatGPT when you need a thinking partner that drafts, codes, and iterates. That’s the whole comparison in two sentences, and most teams still get it wrong because they treat both tools like interchangeable chatbots. They aren’t. One is a research engine that talks. The other is a reasoning engine that searches. The difference shows up in every workflow you build around them.
The Short Version
- Perplexity wins for live research, source-backed answers, fact-checking, and any task where you need to verify a claim against the open web.
- ChatGPT wins for drafting, coding, data analysis on files you upload, creative work, and multi-step reasoning that builds on itself.
- Pricing is nearly identical at the Pro tier: $20 per month each, with ChatGPT offering a cheaper Go tier and Perplexity bundling premium data sources.
- Citation behavior differs structurally: Perplexity shows sources inline by design, ChatGPT shows confidence and cites only when prompted or in search mode.
- The honest answer for most B2B teams: use both. Perplexity for the research pass, ChatGPT for the synthesis pass.
Below, you’ll see how the two tools actually behave across the tasks marketing and growth teams run every day, where each one breaks, and what that means for how your brand gets cited inside them.

What Each Tool Actually Is
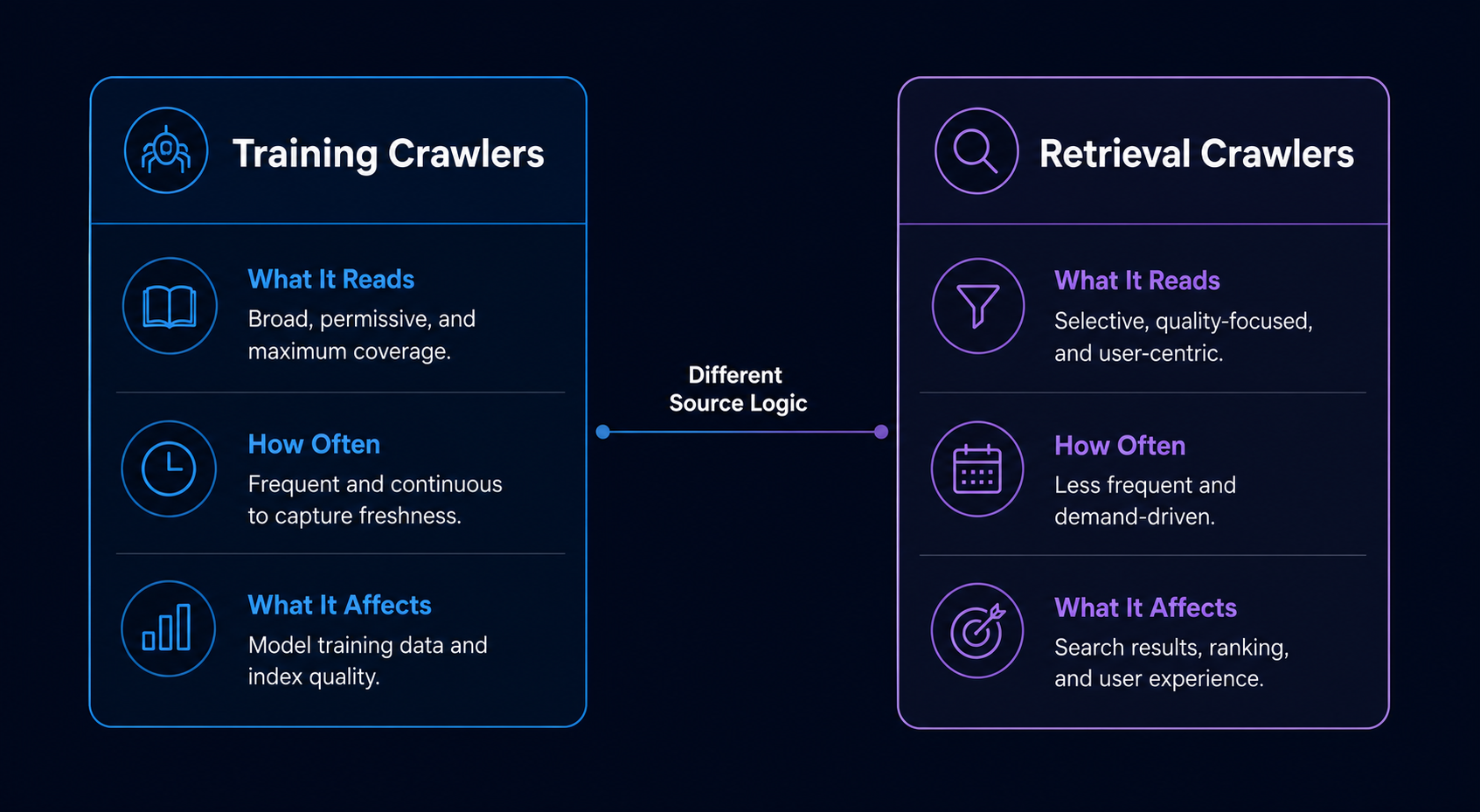
Perplexity is an AI answer engine. You ask a question, it searches the web in real time, then returns a synthesized answer with numbered citations to the pages it pulled from. The model behind the answer rotates: Sonar (Perplexity’s own), GPT, Claude, and others depending on your tier and selection.
ChatGPT is a general-purpose AI assistant built around OpenAI’s GPT models. It writes, codes, reasons, analyzes uploaded files, generates images, and yes, searches the web when you turn that on. But search is a feature inside ChatGPT, not the product itself.
That structural difference drives everything else in this article. Perplexity treats every query as a research task. ChatGPT treats every query as a conversation that might need research.
How They Compare at a Glance
| Dimension | Perplexity | ChatGPT |
|---|---|---|
| Primary use | Live web research with citations | Reasoning, writing, coding, analysis |
| Citations | Inline by default, always shown | Only in search mode or when asked |
| Real-time web | Always on | Optional, model decides when to use it |
| File analysis | Supported, limited iteration | Strong, iterative, code interpreter |
| Coding | Workable for snippets | Stronger for multi-file projects |
| Image generation | Supported via partner models | Native, integrated with chat |
| Memory across chats | Limited, Spaces for grouping | Full memory feature on Plus and Pro |
| Free tier | Generous for casual research | Capped, with smaller model |
| Paid entry | $20/month Pro | $20/month Plus, $9.99 Go tier |
| Browser product | Comet | Atlas |
Read the table once. Now forget the spec sheet and focus on what these differences feel like in real work.
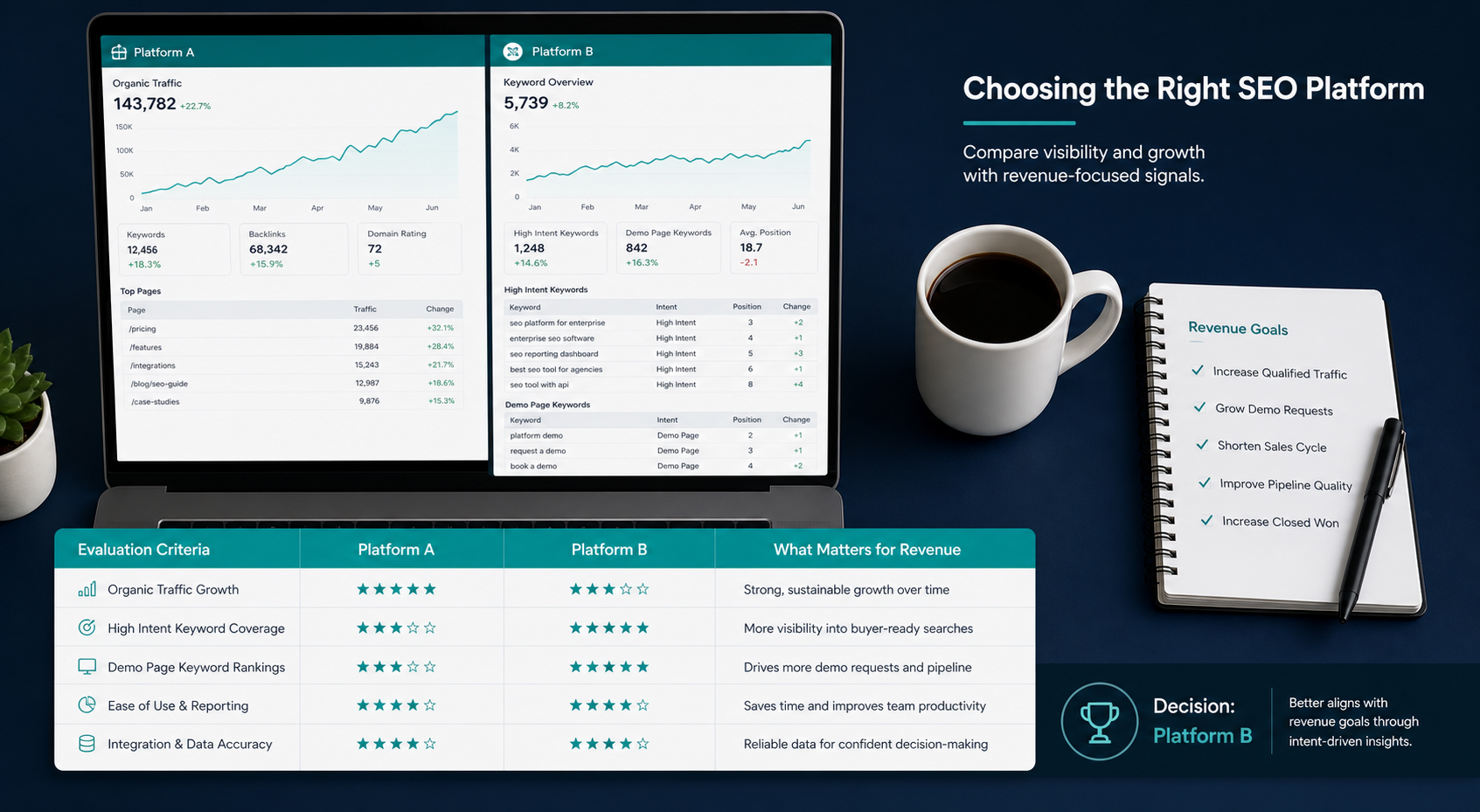
Research Tasks: Where Perplexity Earns Its Subscription
Perplexity is the better research partner because it shows its work. Every claim sits next to a numbered citation you can click. When you’re vetting a vendor, checking a competitor’s pricing, or sourcing a stat for a board deck, that audit trail matters more than eloquence.
Three specific research jobs where Perplexity beats ChatGPT cleanly:
Fact Verification
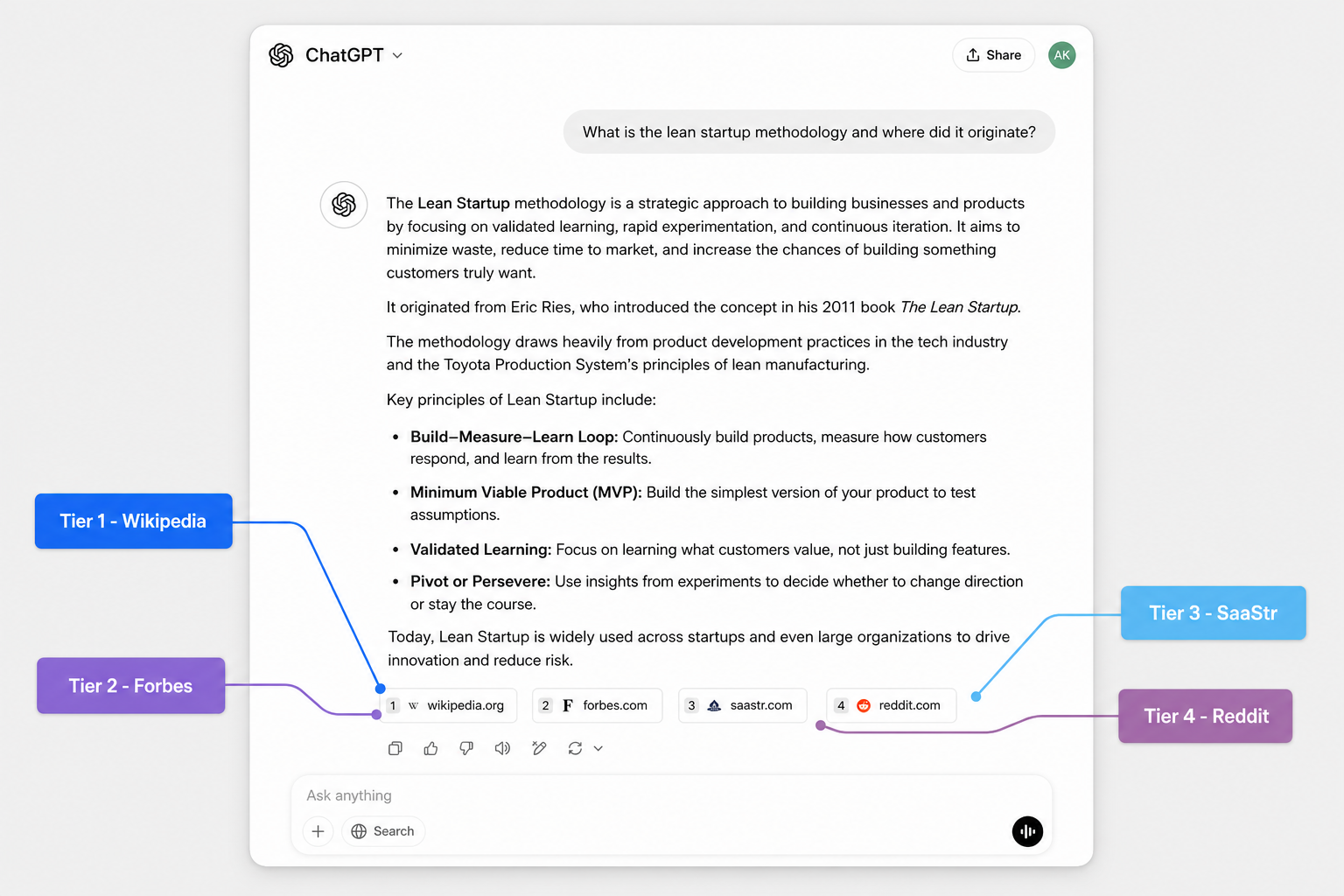
Ask “did Anthropic raise a Series E in 2026?” Perplexity returns the answer with the press release, the funding round size, and the lead investor, all cited. ChatGPT will often answer correctly too, but you don’t see the source unless you toggle search on and prompt for it.
Competitive Scans
“List the pricing tiers for the top 5 brand monitoring tools.” Perplexity pulls live pricing pages. ChatGPT may pull from training data that’s six months stale.
News-Driven Questions
Anything tied to “this week,” “last month,” or “in 2026” goes to Perplexity first. ChatGPT’s search works, but Perplexity makes recency the default state, not a setting you remember to flip on.
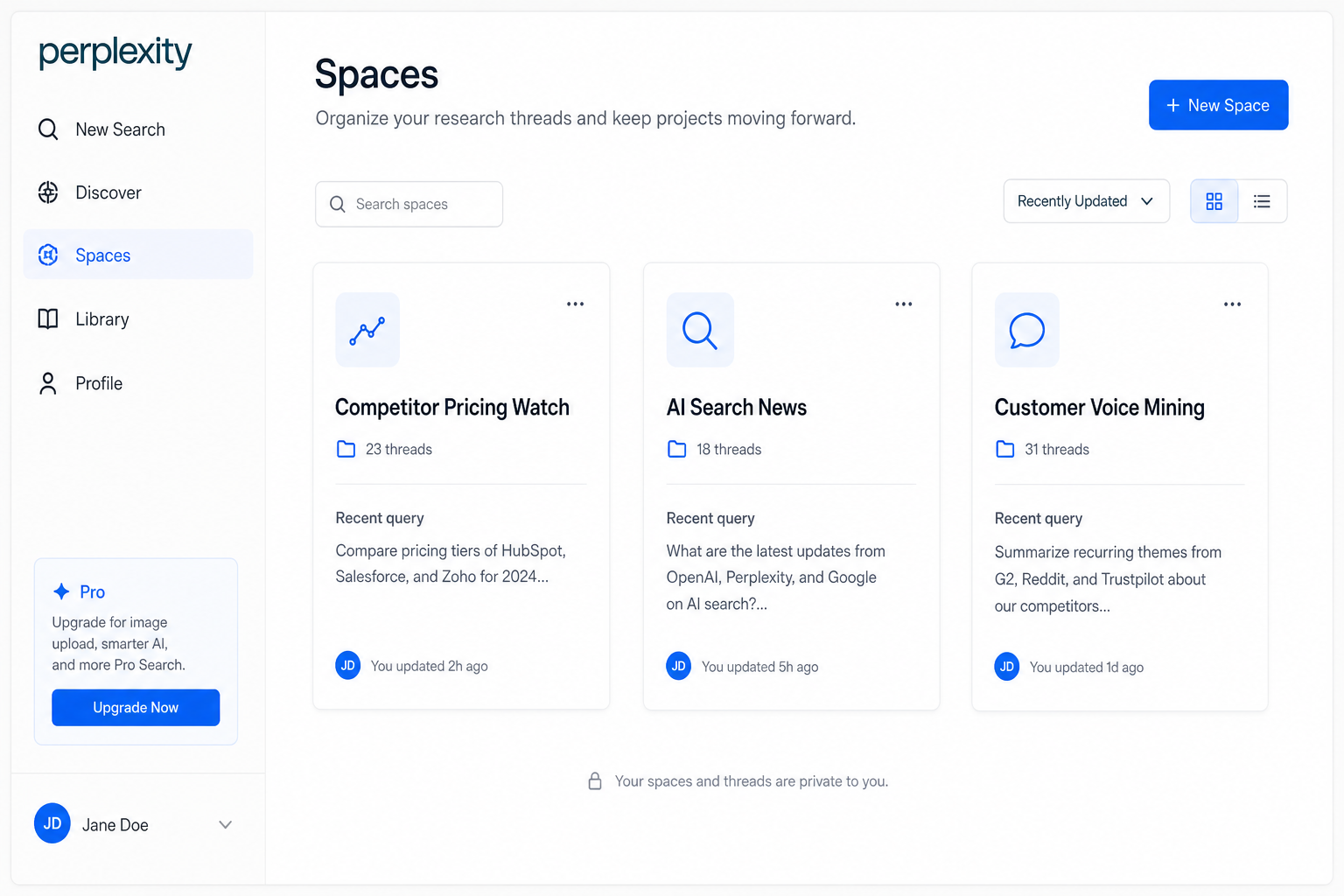
The Pro tier on Perplexity also gives you access to Focus modes (Academic, Social, Reddit, YouTube) and Spaces, which group related research threads with custom instructions. For an in-house researcher running ongoing competitive intelligence, Spaces is genuinely useful. For everyone else, it’s overkill.
Where Perplexity Falls Short on Research
The citations aren’t always great. Perplexity will sometimes cite a low-authority blog summarizing a primary source instead of the primary source itself. It will pull from SEO listicles when a peer-reviewed paper exists. The citations exist. The judgment about which citations matter is still your job.
And Perplexity’s synthesis is shallower than ChatGPT’s. It aggregates well. It connects poorly. Ask it to reason across five sources and tell you what they collectively imply, and you’ll often get five summaries glued together instead of one argument.
Writing, Coding, and Reasoning: Where ChatGPT Pulls Ahead
ChatGPT is the better thinking partner. The difference is most obvious in three places: long-form drafting, code, and any task that requires the model to hold context across many turns.
For drafting, ChatGPT produces tighter prose, follows brand-voice prompts more reliably, and iterates without losing the thread. Give it a 2,000-word brief and ask for a 1,400-word draft in your voice, then revise it three times. ChatGPT will track your edits and apply them consistently. Perplexity won’t, because Perplexity isn’t built to maintain that kind of working memory.
For code, ChatGPT’s Code Interpreter (now folded into the broader analysis tools) executes Python, plots data, and debugs files you upload. You can hand it a CSV, ask for a regression, and watch it run the analysis and explain the output. Perplexity will write the code. ChatGPT will run it.
For reasoning, ChatGPT’s reasoning models think before answering on complex problems. Perplexity has reasoning options too, but ChatGPT’s tooling around them is more mature. If you’re walking through a pricing model, a forecast, or a multi-step strategic question, ChatGPT is the better whiteboard.
One Place ChatGPT Quietly Loses
Confidence without sources. ChatGPT will state things plainly that turn out to be wrong, especially on recent events or niche topics. Perplexity’s citation-first design makes its uncertainty legible. ChatGPT’s clean prose hides it. For low-stakes drafting, that’s fine. For anything that goes to a client, a board, or a regulator, you verify.
Pricing and Value
Both products sit at $20 per month for their main paid tier. The value math diverges from there.
ChatGPT Plus at $20 gets you the latest GPT models, image generation, file analysis, custom GPTs, and full memory. ChatGPT Go at $9.99 strips out some of the heavier features for casual users. ChatGPT Pro at $200 is for power users who want the highest-reasoning models with no rate limits.
Perplexity Pro at $20 gets you unlimited Pro searches, file uploads, model selection (including frontier models from OpenAI, Anthropic, and Google), and access to premium data sources like Statista and academic databases bundled in. Perplexity Max at higher tiers unlocks larger usage caps and earlier feature access.
For a B2B marketing team, the value comparison comes down to a question: do you do more research, or more drafting and analysis? If research dominates, Perplexity Pro’s bundled premium sources are worth real money on their own. If drafting and analysis dominate, ChatGPT Plus pays for itself in two saved hours a week.
Most teams I work with end up paying for both. The combined $40 a month is trivial compared to what either subscription replaces in research time, drafting time, or contractor hours.
Citations and Brand Visibility: The Part Most Comparisons Skip
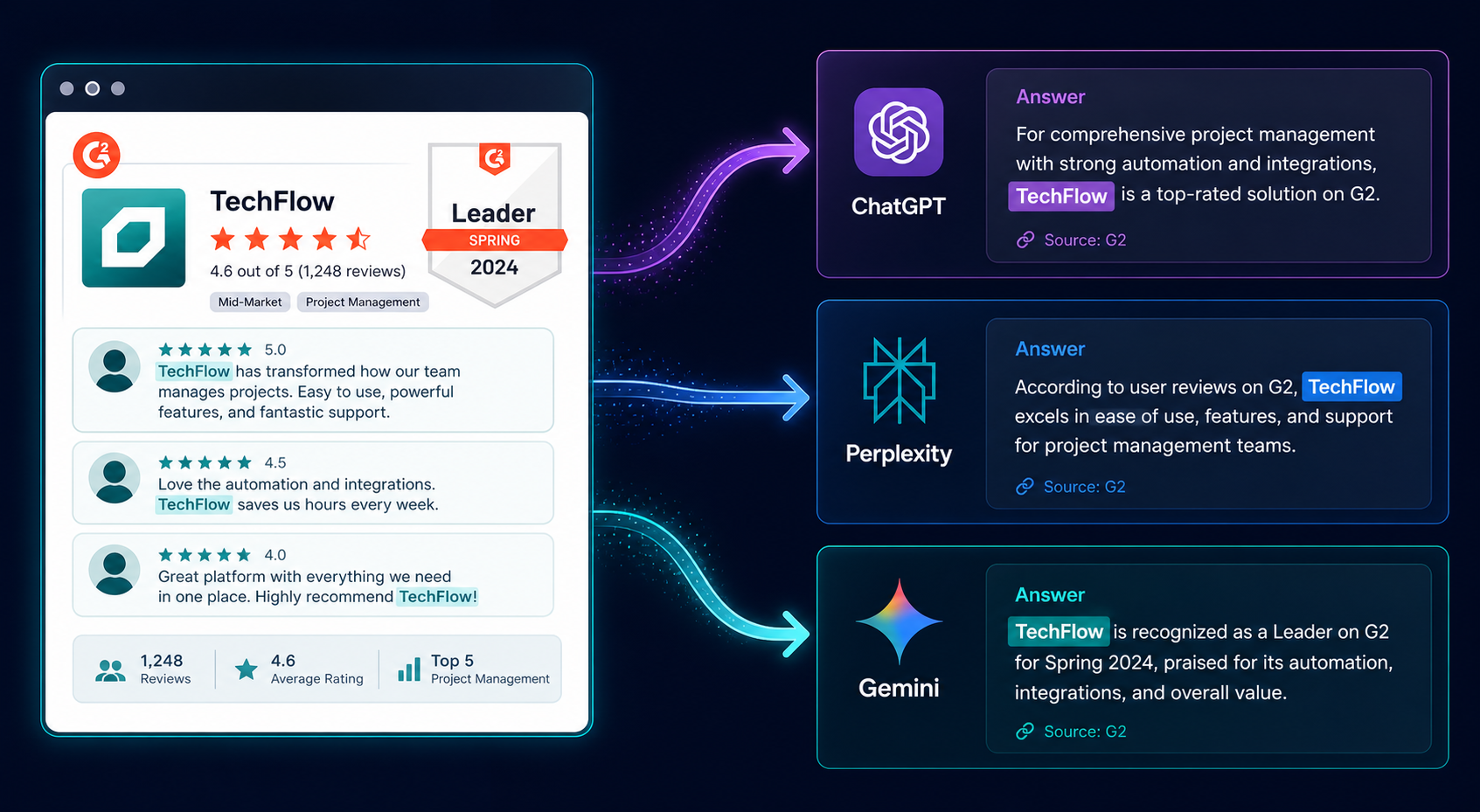
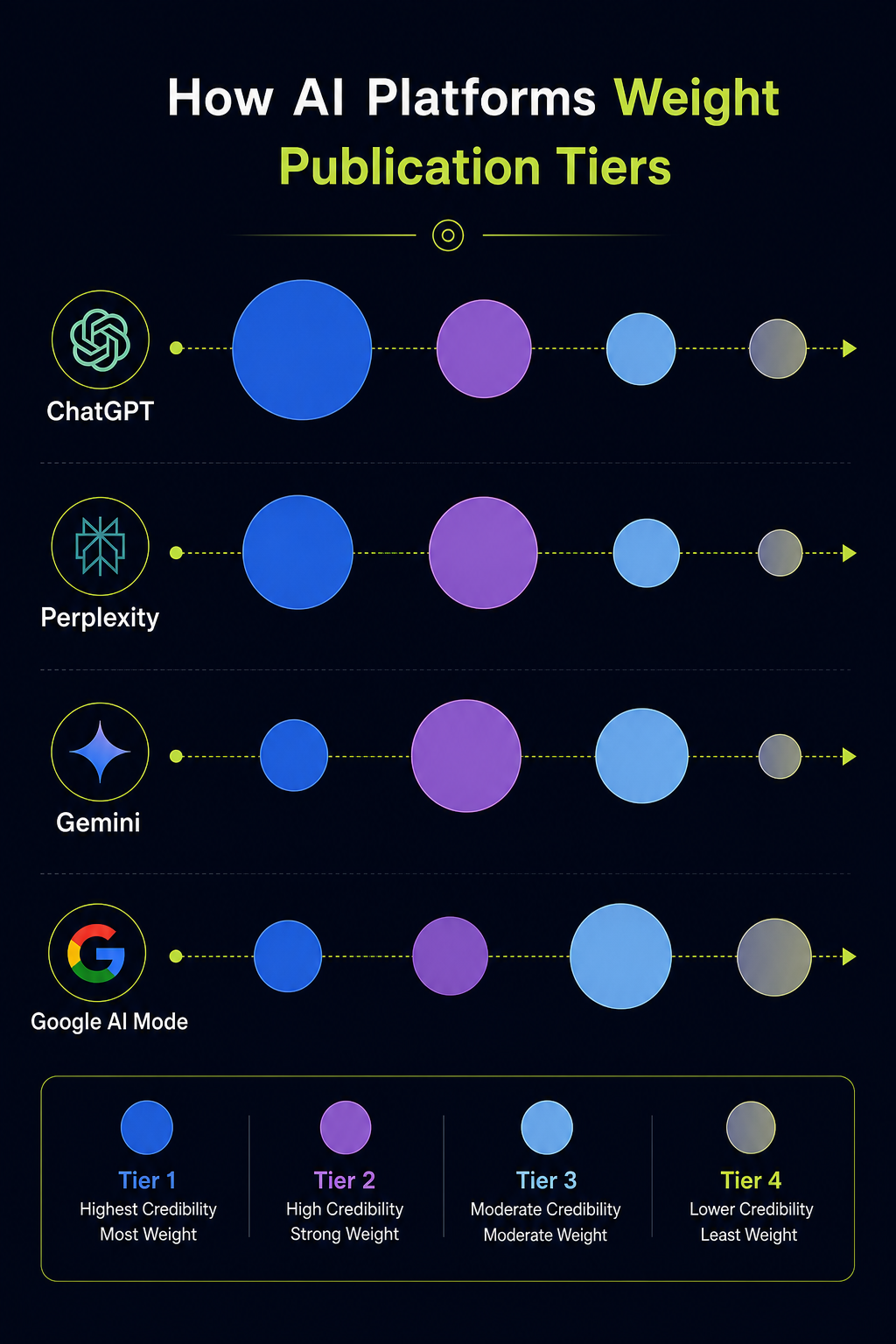
Here’s the angle every other “Perplexity vs ChatGPT” article on the SERP misses. The two tools don’t just answer differently. They cite differently, and that changes which brands they recommend.
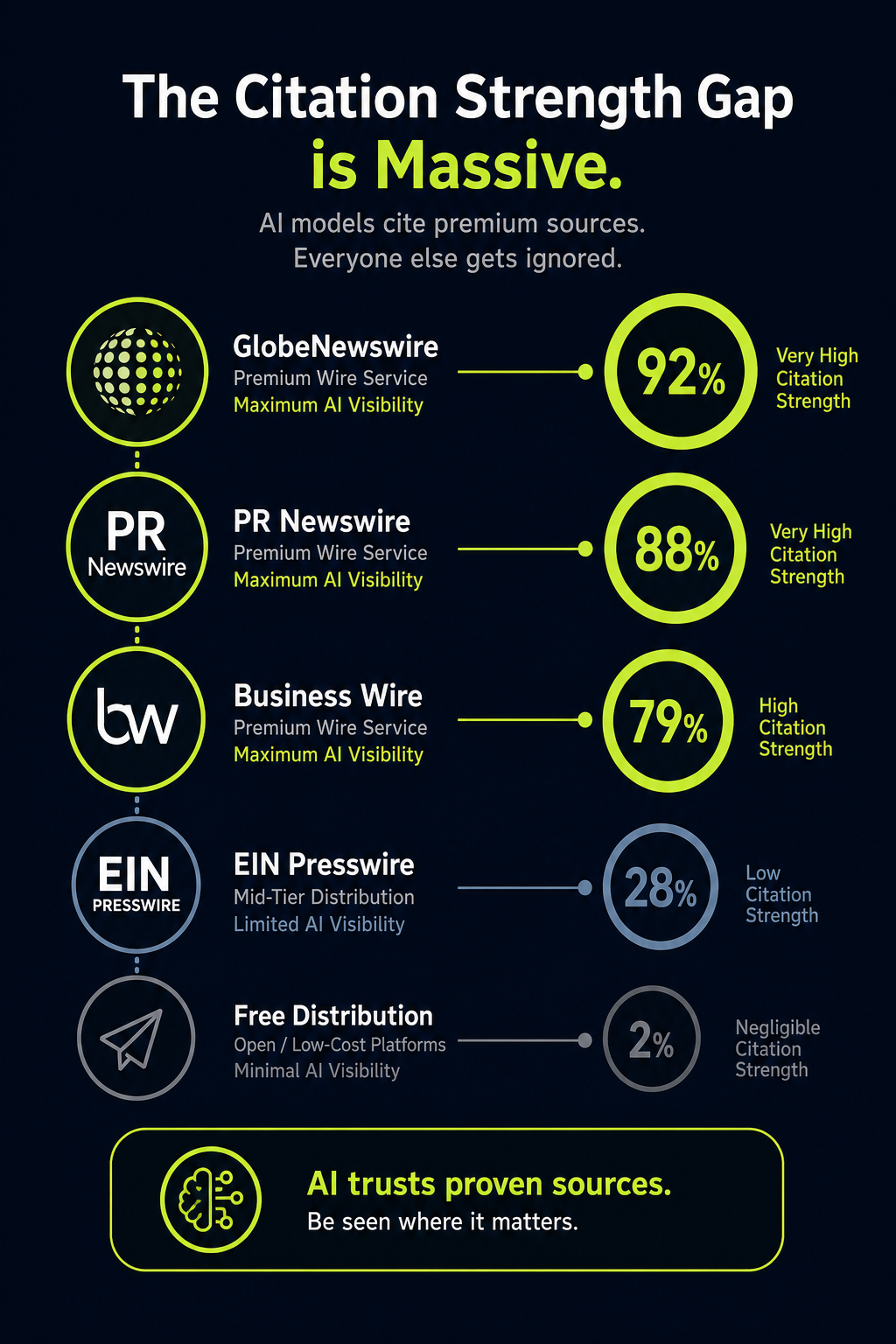
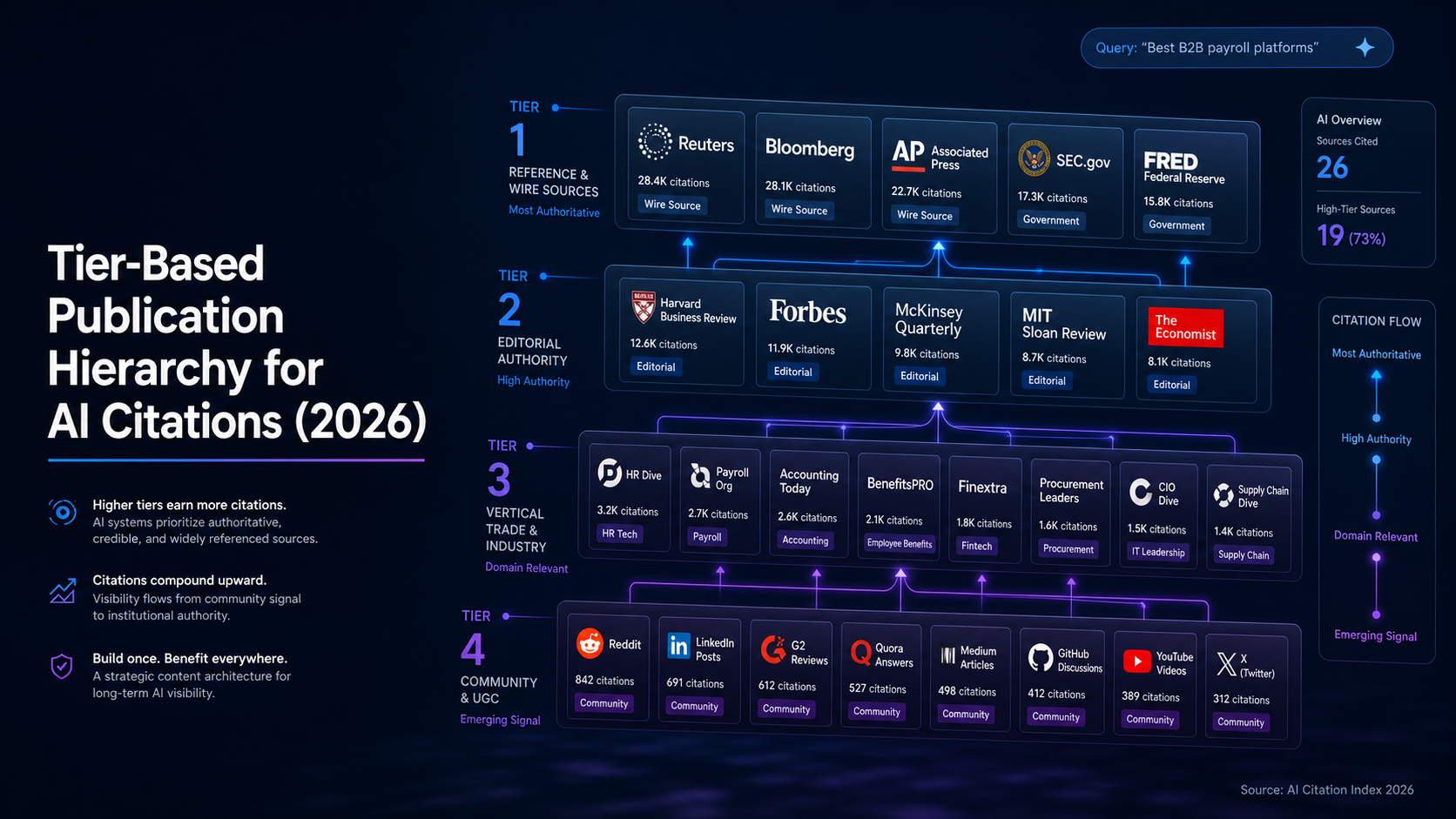
Perplexity surfaces citations as part of every answer. When someone asks “what are the best brand monitoring tools for B2B SaaS,” Perplexity will list 5 to 8 tools, each tied to a specific URL it pulled from. Those URLs come from a live web search. Recency matters. Domain authority matters. Whether your brand appears on the pages Perplexity ranks for that query matters.
ChatGPT cites less often, and when it does cite, the citations come from a different mechanism. In conversational mode without search, ChatGPT recommends brands based on patterns absorbed during training. In search mode, it pulls from live results and behaves more like Perplexity. The brands that show up consistently across both modes are the brands with strong editorial coverage in high-tier publications AI models trust.
This matters for your brand strategy in three concrete ways:
Optimize for Citation Surface, Not Just SERP Rank
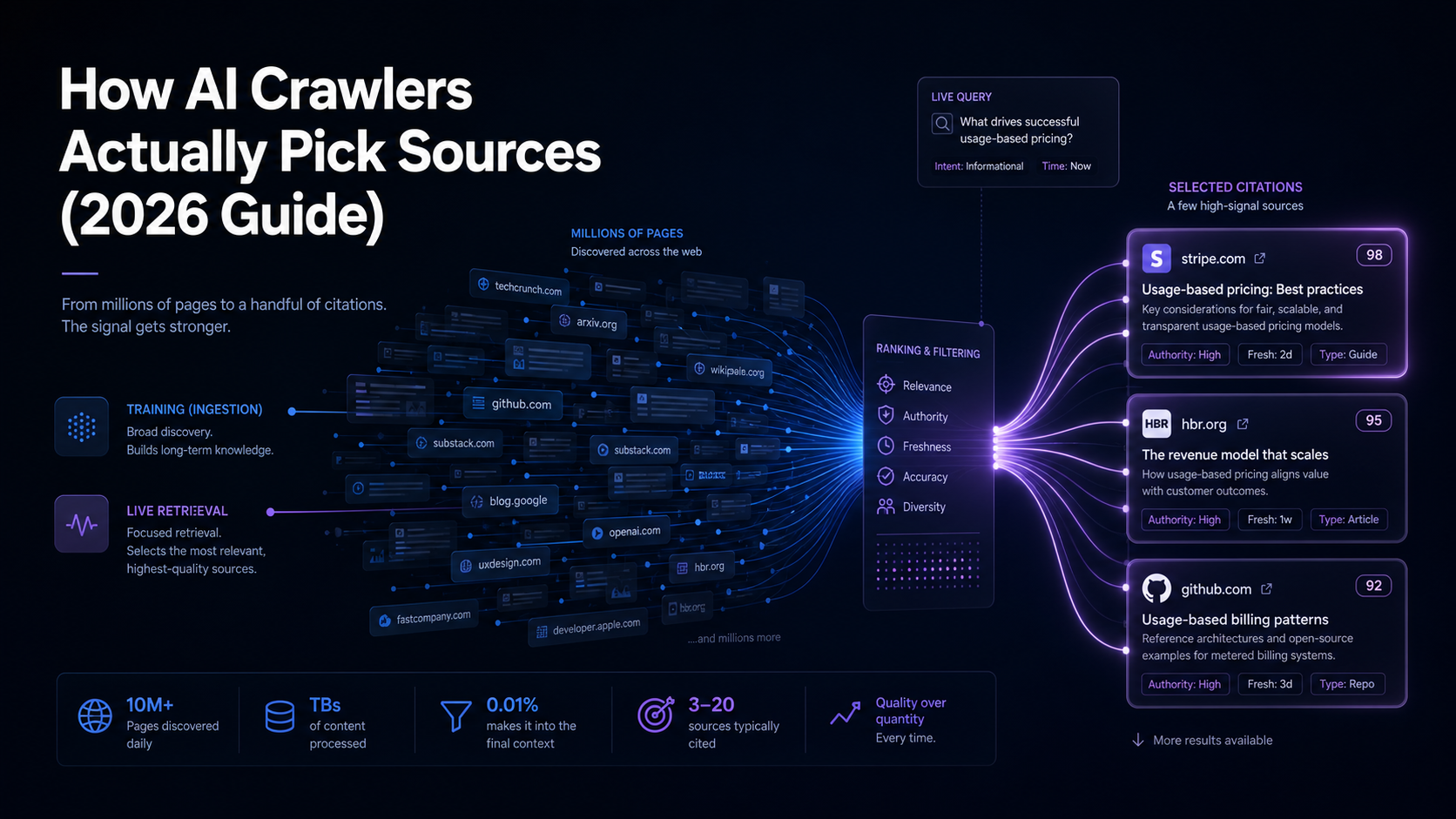
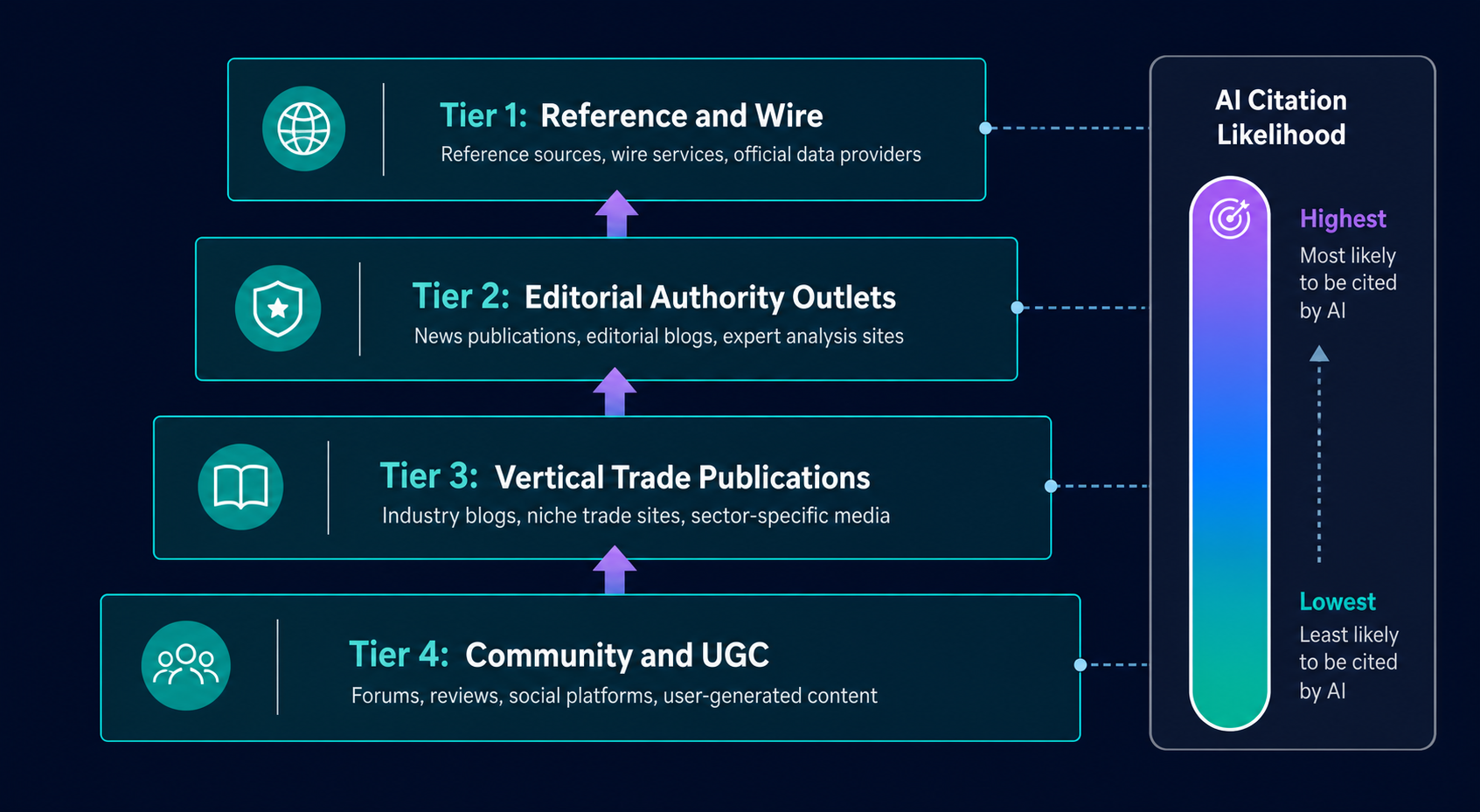
Getting cited in a Perplexity answer for “best [your category] tools” requires you to appear on the third-party pages Perplexity considers authoritative. How AI crawlers pick sources explains the selection logic.
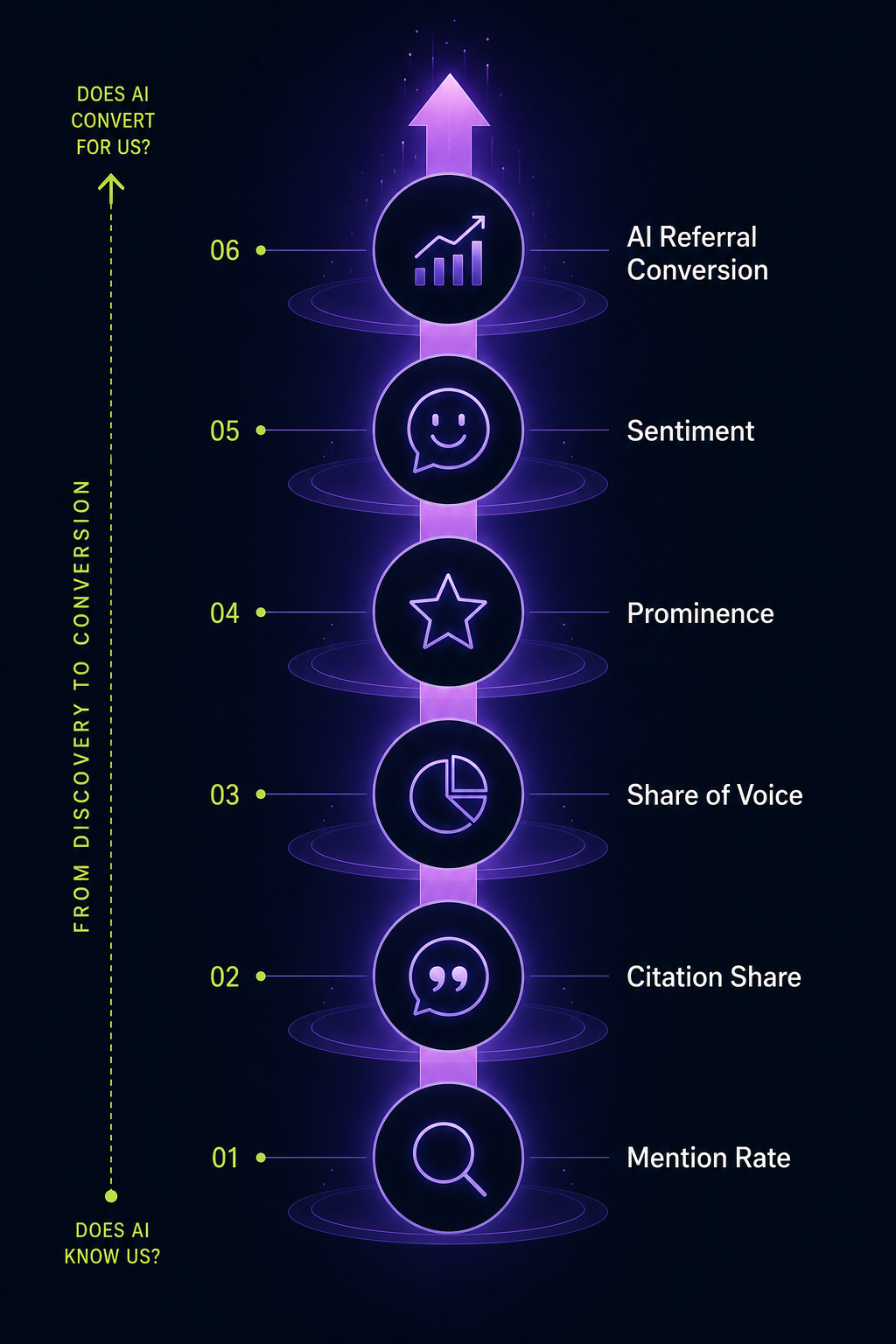
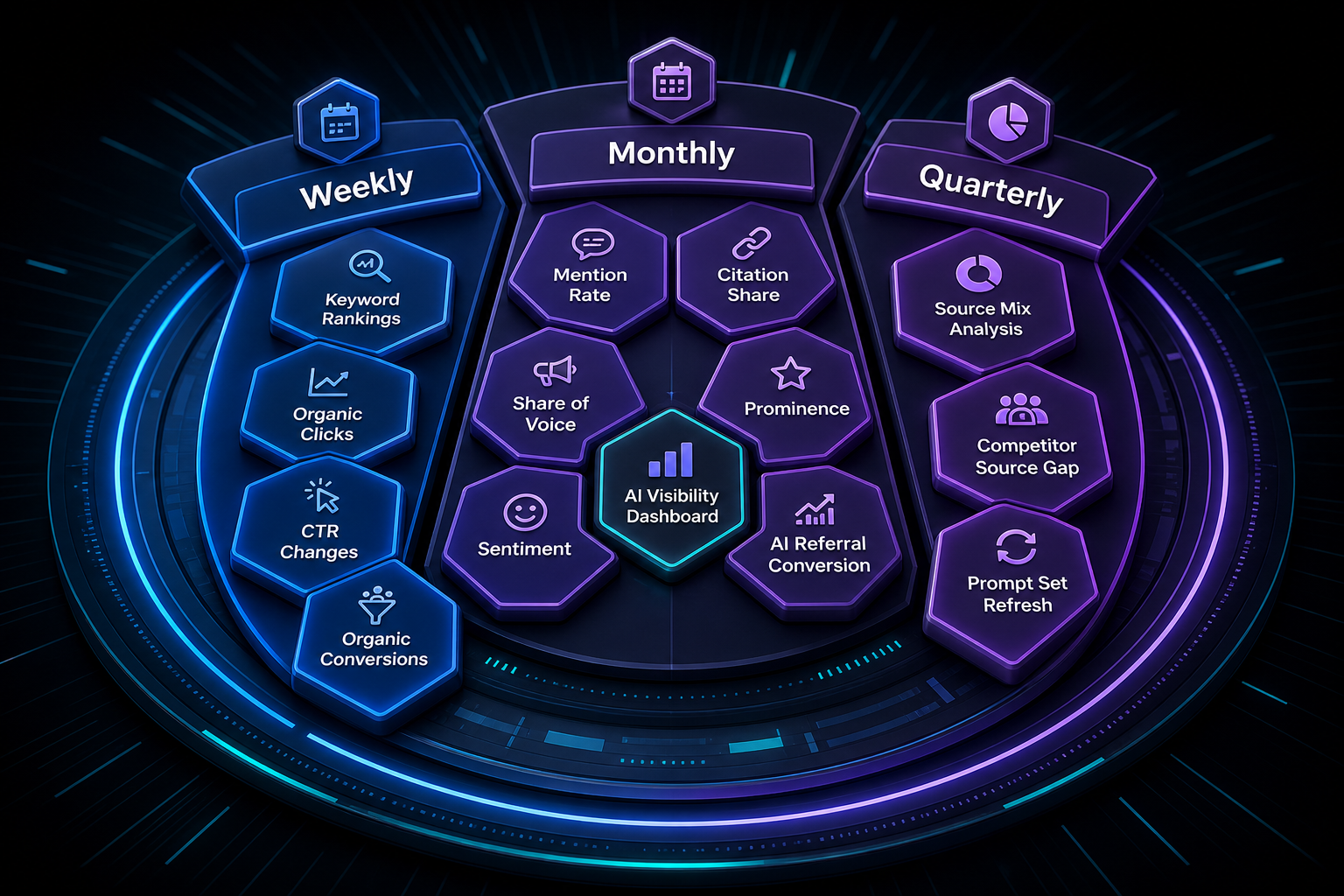
Track Mentions in Both Tools Separately
Your Perplexity citation rate and your ChatGPT recommendation rate move on different signals. You need to track brand mentions across AI search platforms to see both pictures.
The Training Data Window Matters for ChatGPT
If your brand wasn’t on the web at scale 12 to 18 months ago, ChatGPT’s base model doesn’t know you exist. That’s a compounding problem. How brand mentions in AI actually work walks through the mechanics.
I’ve watched two B2B SaaS clients in adjacent categories run identical Perplexity queries last quarter. Client A appears in the first answer paragraph with three citations to industry publications. Client B doesn’t appear at all. The difference wasn’t product. It wasn’t even SEO. It was four months of consistent editorial placement on the publications Perplexity surfaces for that category, while Client B was still chasing backlinks.
When to Use Each Tool: A Practical Routing Guide
| If your task is… | Use this | Why |
|---|---|---|
| Verifying a recent stat or event | Perplexity | Live citations, recency by default |
| Drafting a 1,500-word article | ChatGPT | Better long-form coherence and iteration |
| Competitive pricing scan | Perplexity | Pulls live pricing pages |
| Analyzing a CSV or PDF | ChatGPT | Code Interpreter runs the analysis |
| Writing and debugging code | ChatGPT | Multi-file context, iterative debugging |
| Sourcing quotes for a thought piece | Perplexity | Citations show the source verbatim |
| Building a custom workflow assistant | ChatGPT | Custom GPTs, memory, instructions |
| Academic or paywalled research | Perplexity Pro | Bundled premium source access |
| Strategic reasoning across multiple inputs | ChatGPT | Reasoning models hold and weigh context |
| Tracking how AI describes your brand | Both, separately | Different signals drive different citations |
The routing table is the single most useful artifact in this article. Save it. Hand it to your team. The teams that get the most value from both tools are the ones who stop arguing about which is “better” and start matching the tool to the task.
Browser Products: Comet and Atlas
Both companies launched AI-native browsers in 2026. Perplexity’s Comet bakes the answer engine into the browser chrome, so any page you visit becomes a research surface. Highlight a paragraph, ask a question, get an answer that pulls from the page and the wider web. For research-heavy work, Comet feels like a natural extension of Perplexity Pro.
ChatGPT’s Atlas is more agentic in framing. It can navigate sites for you, fill forms, complete multi-step tasks, and hold context across pages. The vision is closer to “browser as autonomous assistant.” It works well for repetitive workflows and falls apart on edge cases that need judgment.
Neither browser is ready to replace Chrome or Safari for everyone. Both are worth installing if you live in the tool they pair with.
The Honest Take on Hallucinations
Both tools hallucinate. Anyone selling you a comparison that says one is “hallucination-free” is selling you something.
Perplexity hallucinates less on factual lookups because it grounds every answer in retrieved sources. But it will still misattribute claims, conflate similar entities, and sometimes cite a source that doesn’t actually say what the answer claims. Verify the citation, not just the answer.
ChatGPT hallucinates more in plain-text mode and less when search is on. The hallucinations are smoother, which makes them harder to catch. A confidently-stated wrong fact in a clean paragraph is more dangerous than a wrong fact next to a clickable citation.
For B2B work where accuracy matters, the rule is simple: if a claim is going to a client, a board, a regulator, or a public byline, verify it against a primary source you can read yourself. Neither tool replaces that step.
Frequently Asked Questions
Is Perplexity better than ChatGPT?
Neither is universally better. Perplexity is better for live research, citations, and fact verification. ChatGPT is better for drafting, coding, analysis, and multi-step reasoning. The right answer for most teams is to use both for the tasks each one handles well.
Can Perplexity do what ChatGPT does?
Partially. Perplexity can draft, summarize, and code at a reasonable level, especially on Pro tier with frontier model selection. But it isn’t built for sustained drafting, iterative code work, or complex file analysis. ChatGPT remains stronger for those tasks.
Is ChatGPT’s web search as good as Perplexity’s?
Close, but not equivalent. ChatGPT’s search works well when you remember to use it, and it cites sources when you ask. Perplexity makes search the default state and surfaces citations on every answer. For research-heavy workflows, Perplexity’s design wins. For occasional lookups inside a longer conversation, ChatGPT’s search is sufficient.
Which is better for SEO and content research?
Perplexity for the research phase, ChatGPT for the drafting phase. Use Perplexity to pull live SERP context, competitor positioning, and source material. Use ChatGPT to synthesize that input into an outline, draft, and revisions. The combined workflow saves more time than either tool alone.
Which tool cites my brand more often?
It depends on where your brand earns coverage. Perplexity cites brands that appear on the pages it ranks for category-defining queries, which usually means high-authority editorial publications and Reddit. ChatGPT recommends brands present in its training data and surfaces newer brands through search mode. Tracking both separately is the only way to see the full picture.
Should I pay for both?
If you do AI-assisted research more than twice a week and AI-assisted drafting more than twice a week, yes. $40 a month for both is a small budget line that replaces hours of work. If your usage skews heavily one direction, pay for the matching tool and use the other’s free tier for occasional tasks.
What This Means for Your AI Visibility Strategy
The right question isn’t “Perplexity or ChatGPT.” It’s “what does each tool say about my brand when a prospect asks for recommendations in my category?” If the answer is “nothing” or “wrong things,” your AI visibility work hasn’t started yet.
Run three queries today. Ask Perplexity to recommend the top tools in your category. Ask ChatGPT the same question. Ask one more in Google’s AI Mode. Write down which brands show up, in what order, with what framing. That snapshot is your starting line.
Then check what AI says about your brand right now, and where the gap is between the brands AI recommends and the brand you’re trying to build. Book a free AI visibility audit if you want a second set of eyes on the gap and a 90-day plan to close it.
Here’s the published-ready HTML file for “perplexity vs chatgpt.” background reading