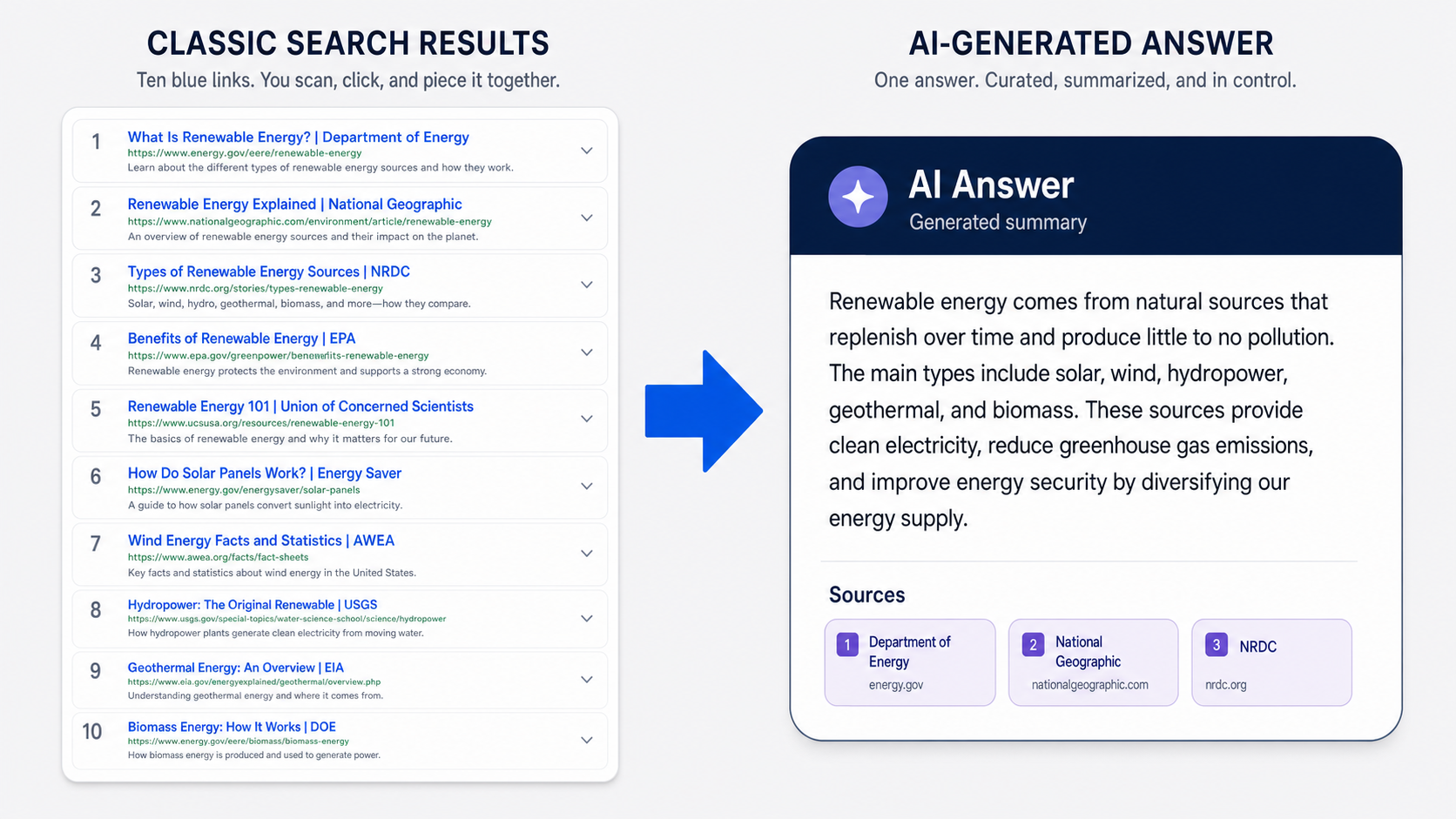
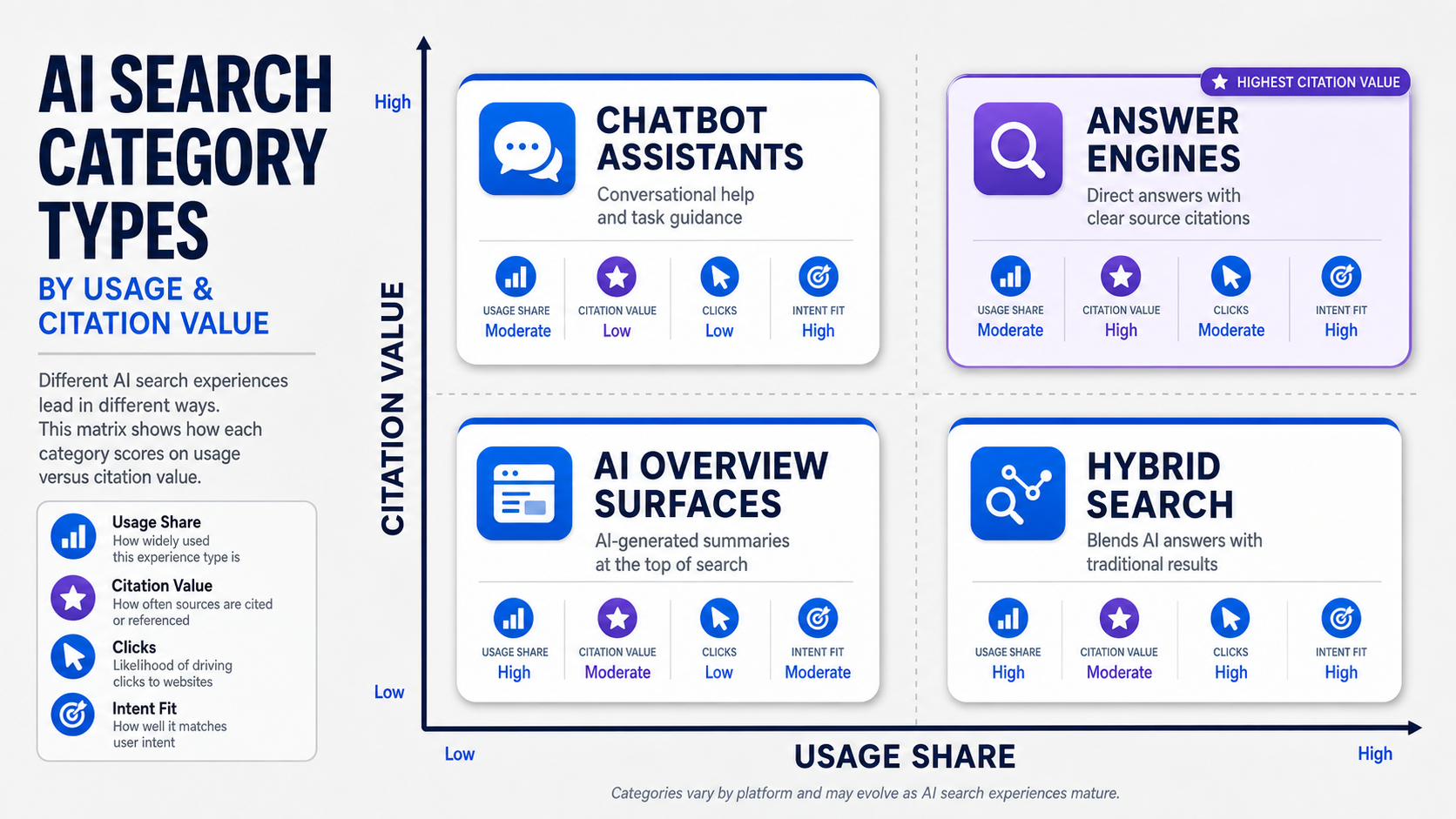
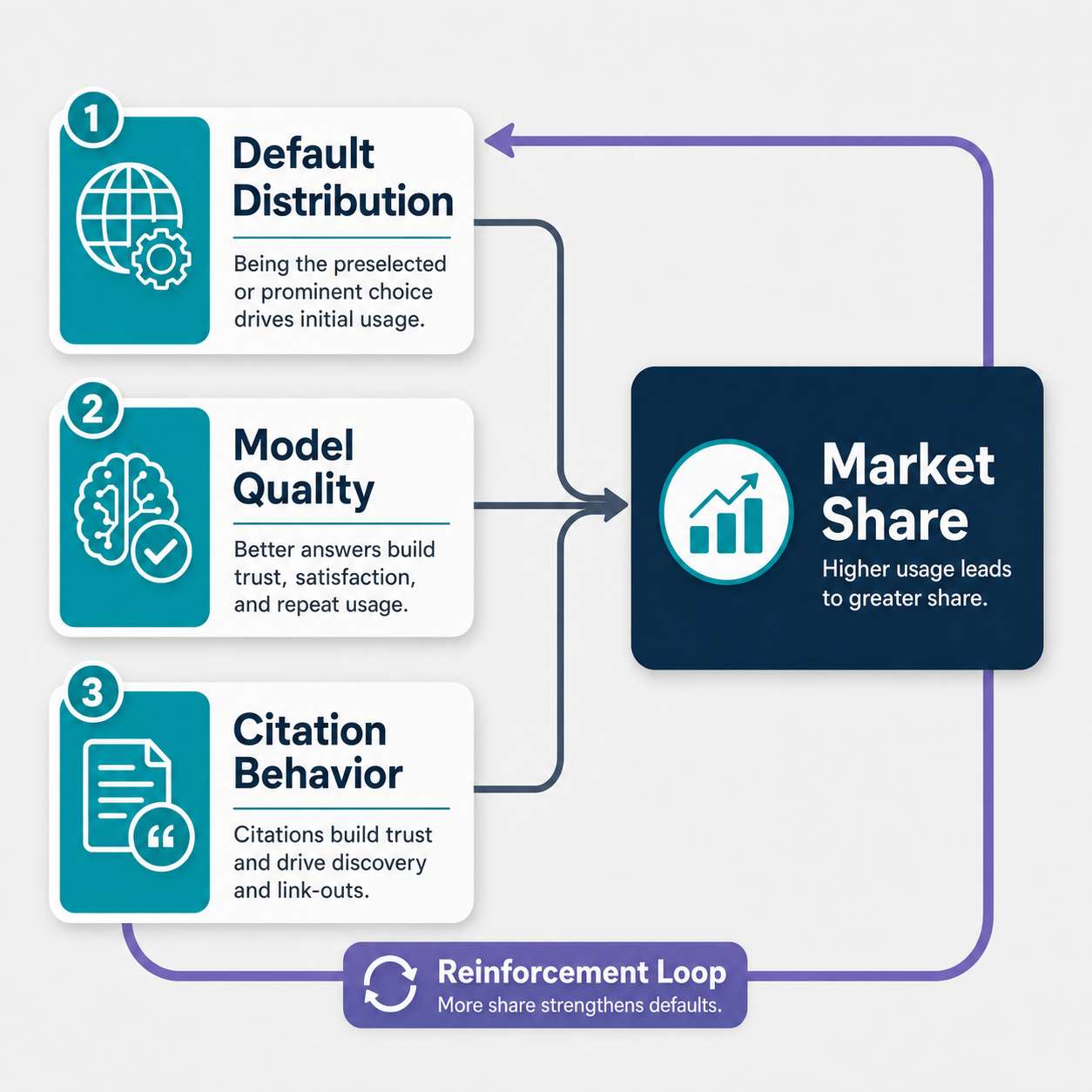
If you are searching for the best contextual link building services, the honest answer is that there is no single winner, because the right service is the one that proves topical relevance, editorial quality, and transparent reporting for your specific niche and budget. A ranked list of vendors is the wrong tool for this decision. The provider that suits a Series A SaaS team is rarely the one that suits a law firm or an agency reselling placements. This guide gives you the evaluation framework instead: the eight criteria that separate a defensible contextual link from a liability, the provider categories worth shortlisting, and the red flags that should end a sales call early.
Most buyers waste money here by optimizing for one metric, usually Domain Rating, while ignoring whether the link actually sits inside a topic-matched article. That single habit is the difference between links that compound and links that get devalued.
The Short Version
- The best contextual link building service is the one that shows you sample placements and reporting structure before you commit, not after.
- Relevance beats raw authority: a link inside a topic-matched article on a smaller site usually outperforms a high-DR placement on an unrelated page.
- Match the provider type to your stage: managed services for hands-off delivery, marketplace models for scale and comparison, boutique outreach agencies for niche-sensitive campaigns.
- Walk away from anyone selling on DR alone, refusing sample URLs, or promising guaranteed rankings.
For the underlying mechanics of how these placements work, our explainer on contextual link building services covers the definition and tactics. This article assumes you already know what a contextual link is and focuses entirely on how to buy one well.
Why a Ranked Vendor List Is the Wrong Way to Choose
The roundup pages dominating this search term share one structural flaw: they rank providers as if “best” were a fixed property of the vendor rather than a function of your campaign.
It is not.
A contextual link earns its value from three things at once: the topical match between the linking page and your target page, the editorial standard of the publisher, and the way the link is placed inside genuine content. None of those are captured by a numbered list that crowns a single champion.
The same provider can deliver an excellent placement for one client and a weak one for another, depending entirely on whether their publisher pool overlaps with your niche. That is why this guide teaches you to evaluate, not to copy someone else’s ranking.
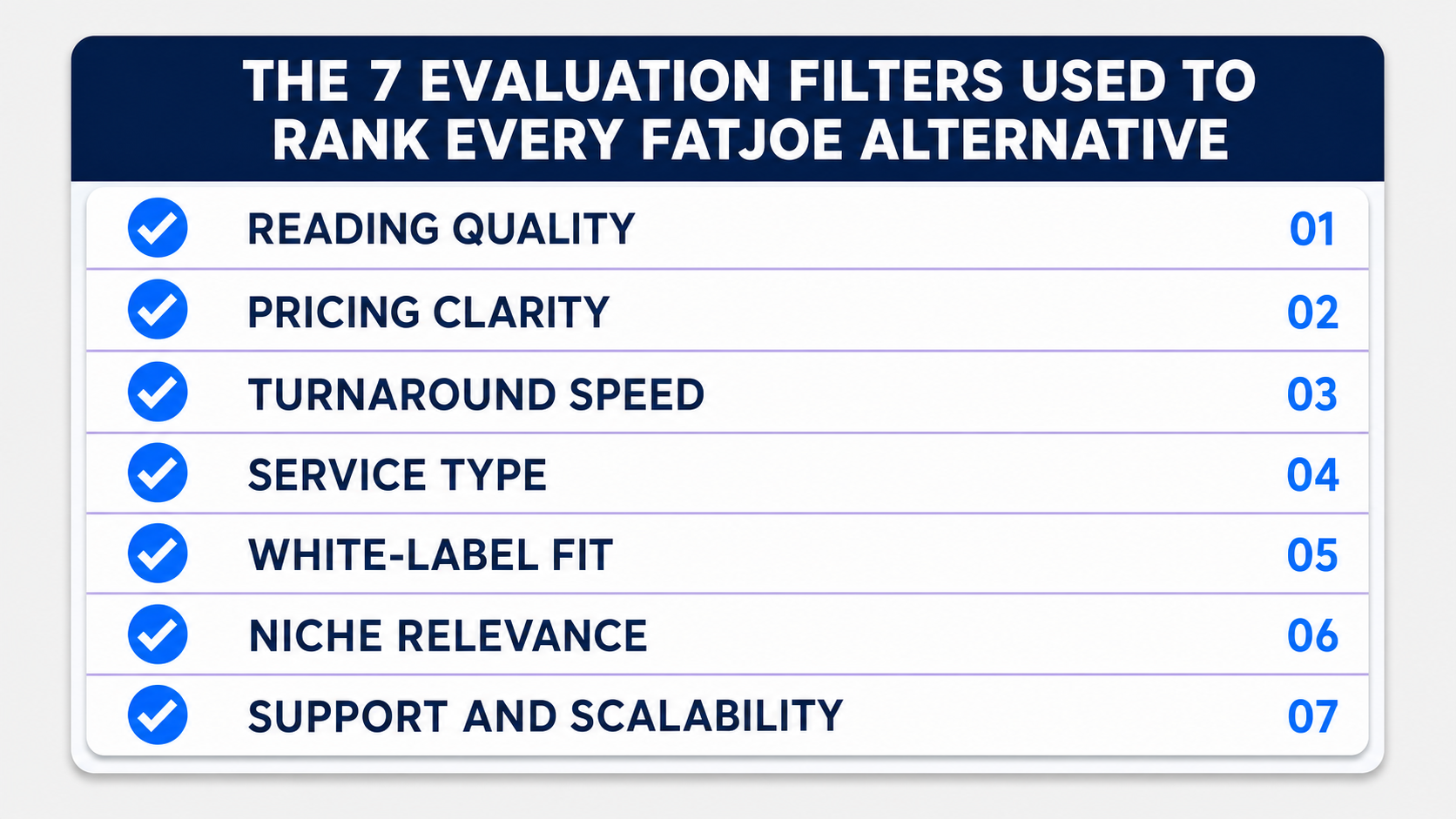
The 8 Criteria That Separate Strong Services From Risky Ones
Score every provider you consider against these eight criteria before you compare price. The first four carry the most weight, because they predict whether the links survive future algorithm updates.
1. Link Relevance
Relevance means the link sits inside an article on the same topic as your target page, not just on a high-authority domain. A finance link on a finance article beats a finance link buried in a generic lifestyle blog, every time. Ask the provider how they match publisher topics to client pages, and require examples.
2. Editorial Quality
Editorial quality covers human review, real content standards, and the absence of obvious link farms or thin pages. Read a sample article end to end. If it reads like filler written only to host links, the placement carries little durable value.
3. Transparency
Transparency means you see sample URLs, placement examples, and reporting format before the campaign starts. Providers confident in their work show it early. Our piece on editorial link building that earns real authority explains why editorial proof matters more than promises.
4. Niche Fit
Niche fit is whether the provider has genuine reach in your industry. A service strong in ecommerce may have almost no relevant publishers in cybersecurity or fintech. Ask directly which verticals their network covers best.
5. Pricing Clarity
Pricing clarity means you understand what you pay per placement or per month and what that includes. Some services use custom quotes, others run marketplace pricing, and others sell fixed packages. None of these models is inherently better, but vague pricing is a warning sign.
6. Turnaround
Turnaround is how long placements take from order to live link. Honest providers quote ranges in weeks, not instant delivery. Anyone promising same-day live editorial links is usually selling something other than editorial links.
7. Reporting
Reporting should show you live URLs, anchor text, publisher metrics, and placement dates in a format you can audit. If reporting is a screenshot or a vague summary, you cannot verify what you bought.
8. Risk Profile
Risk profile is the provider’s stance on link schemes, anchor over-optimization, and link velocity. A service that talks openly about pacing and natural anchor distribution is managing your risk. One that ignores it is creating it.

Provider Categories Worth Shortlisting
Rather than naming a winner, sort the market into the categories that actually map to buyer needs. Most services fall cleanly into one of these, and knowing the category tells you what tradeoffs to expect.
Managed Done-for-You Services
These handle prospecting, outreach, content, and placement for you. They suit teams that want relevance and editorial screening without running outreach internally. Expect higher per-link cost in exchange for less operational work, and confirm reporting depth before ordering.
Marketplace-Style Platforms
Marketplace models give you a wide publisher pool and let you compare placements across sites. They favor buyers who want scale and the ability to vet inventory directly. The tradeoff is that quality varies across the marketplace, so sample-URL vetting matters more, not less.
Boutique Outreach Agencies
Boutique agencies run custom, niche-sensitive campaigns with tighter targeting and fewer one-size-fits-all deliverables. They fit SaaS, B2B, and specialized industries where topical match is hard. Custom work takes longer and needs a clear brief from you. Our guide on hiring a link building consultant who delivers covers how to brief this kind of partner.
Enterprise and Digital PR Services
These pursue authority-style links through linkable content and earned media rather than packaged placements. They suit larger budgets and teams that want link building integrated with broader SEO and brand strategy. They reward patience over instant volume.
White-Label Providers for Agencies
If you resell links to clients, white-label delivery, consistency, and clean reporting matter more than brand recognition. Our overview of white label link building services for agencies walks through what to demand from a reseller partner.
How to Choose by Budget, Niche, and Risk
Use this decision path to route yourself from your situation to the right provider category.
If budget is tight, prioritize any provider that shows real sample placements and clear reporting before you pay, regardless of category. A cheaper service with verifiable samples beats an expensive one selling on reputation alone.
If your brand is SaaS or B2B, prioritize niche fit and editorial context over raw Domain Rating. A boutique outreach agency with reach in your vertical usually outperforms a generalist marketplace. Our breakdown of the best link building agencies for B2B shows what specialized fit looks like in practice.
If you operate in an enterprise or high-risk space such as fintech, healthcare, or legal, prioritize transparency, content standards, and campaign control above speed. Enterprise and digital PR services manage that risk better than fast-turnaround marketplaces.
If you are an agency or reseller, prioritize white-label options, delivery consistency, and reporting clarity so you can stand behind the links to your own clients.
Red Flags That Should End the Conversation
Treat any one of these as a reason to walk away, no matter how polished the pitch.

- No sample URLs offered, or samples shown only after you sign.
- Selling on Domain Rating or Domain Authority alone, with no talk of topical relevance.
- Vague turnaround like “fast delivery” with no week range.
- No placement examples from your specific industry.
- Reporting limited to screenshots rather than auditable live URLs.
- Any promise of guaranteed rankings, which no honest provider can make.
The presence of strong metrics does not cancel out these flags. A provider can show DR 70 inventory and still place your link in a thin, irrelevant article that ages badly.
What to Ask in the First Sales Call
Bring these questions to any provider before you discuss price. The quality of the answers tells you more than any case study.
Ask how they match publisher topics to client target pages, and request two live examples from your niche.
Ask what their content standards are and who reviews placements before they go live.
Ask how they handle anchor text distribution and link velocity across a campaign.
Ask exactly what their report shows and how often you receive it.
Ask what happens if a link is removed or the publisher takes the page down.
Provider Categories Compared
| Category | Best for | Pricing model | Relevance control | Turnaround | Choose if |
|---|---|---|---|---|---|
| Managed done-for-you | Hands-off teams | Per link or retainer | Medium to high | Weeks | You want delivery without running outreach |
| Marketplace platform | Scale and comparison | Pay per placement | Variable, buyer-vetted | Days to weeks | You can vet inventory yourself |
| Boutique outreach agency | SaaS, B2B, niche fields | Custom quote | High | Several weeks | Topical match is hard in your niche |
| Enterprise and digital PR | Large budgets | Retainer | High, earned | Longer campaigns | You want links tied to brand and SEO strategy |
| White-label provider | Agencies and resellers | Wholesale per link | Medium to high | Weeks | You resell to your own clients |
Frequently Asked Questions
What are contextual link building services?
Contextual link building services place links to your site inside relevant, in-content sections of editorial articles on other websites. The defining feature is that the link sits within topic-matched content rather than in a footer, sidebar, author bio, or directory listing, which is what gives it durable SEO value.
How much do contextual link building services cost?
Pricing varies widely by publisher authority, niche difficulty, and service model, ranging from roughly USD 100 to over USD 1,500 per link based on figures reported across the link building market. Marketplace placements sit at the lower end, while managed and digital PR campaigns command retainers. Treat unusually cheap pricing as a quality warning rather than a bargain.
Are contextual backlinks safe for SEO?
Contextual backlinks are among the safer link types when they are genuinely editorial, topically relevant, and acquired without manipulative anchor over-optimization. Risk rises sharply when links are placed in thin content, follow unnatural velocity, or use exact-match anchors at scale. The safety comes from the quality of execution, not the label.
What is the difference between contextual links and guest posts?
A guest post is a full article you contribute to a publisher, which usually contains a contextual link back to your site. A contextual link is the link itself, which can come from a guest post, a niche edit inside an existing article, or a digital PR placement. Guest posts are one delivery method; contextual links are the outcome.
How do I choose the best contextual link building service?
Score providers against the eight criteria in this guide, with relevance, editorial quality, transparency, and niche fit weighted highest. Request sample placements from your industry, confirm the reporting format, and match the provider category to your stage and risk tolerance before you compare price.
The Honest Take
The best contextual link building service is not the one with the biggest metric claims or the top spot on someone else’s roundup. It is the one that proves relevance first, shows you real samples, and reports in a format you can audit.
Shortlist two or three providers across the categories that fit your stage. Request sample placements from your exact niche, run them against the eight criteria, and choose the partner that demonstrates topical fit and transparency before you pay. If a service cannot prove relevance up front, no price is low enough to justify the risk. For how a structured program ties links to broader visibility, see how our brand mention programme works.