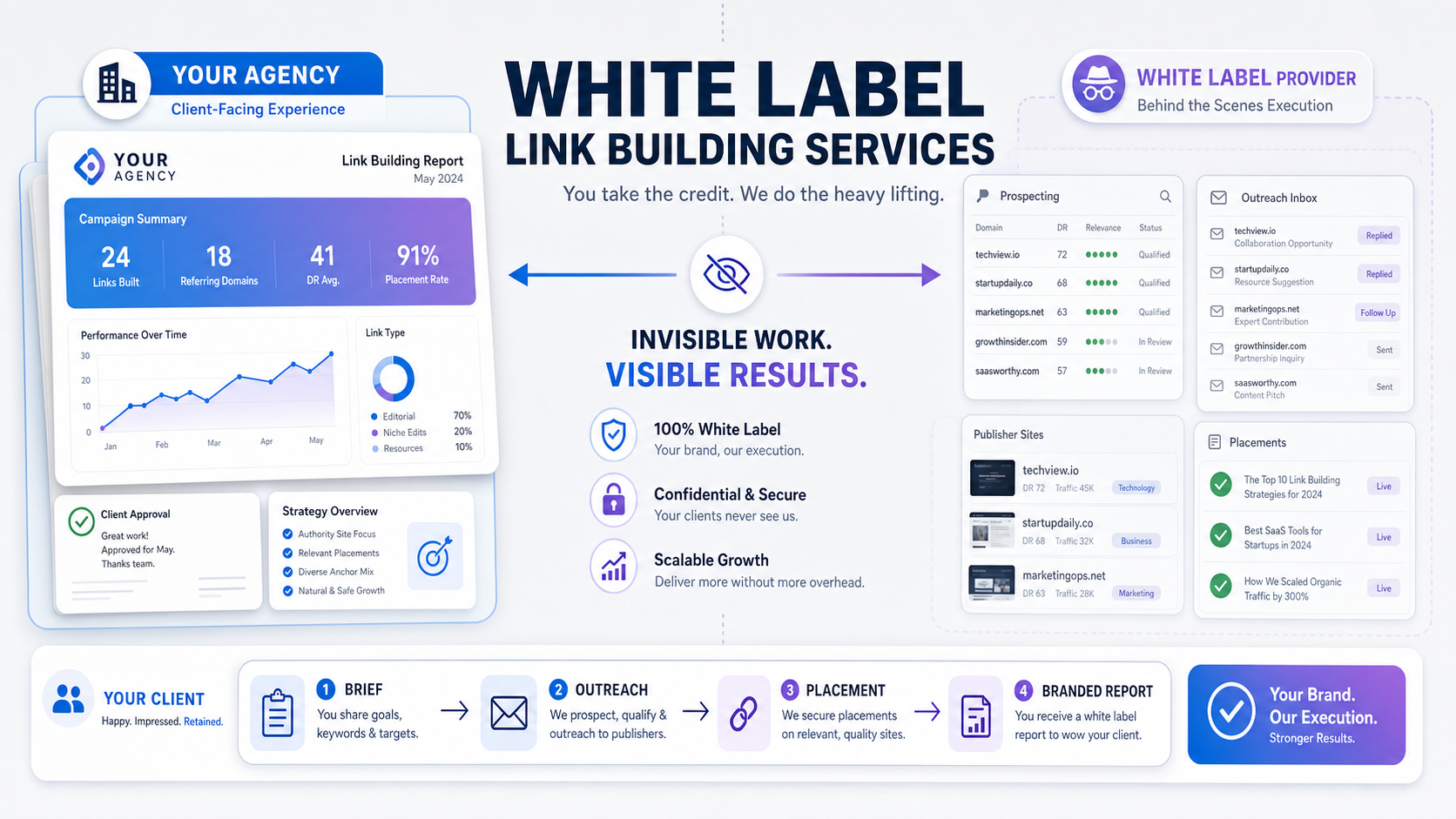
If your agency needs backlinks without building an in-house outreach team, white label link building services are one of the few workable fulfillment models. A third-party provider does the prospecting, outreach, and placement work, then hands you a branded report you pass to your client as your own. You keep the strategy and the relationship. The vendor stays invisible. That’s the whole arrangement, and whether it fits your agency depends on how you evaluate the provider, not on how cheap the links are.
This is an evaluation guide, not a pitch.
The goal is to help you judge providers on what actually predicts good outcomes: transparency, relevance, and repeatable quality.
What White Label Link Building Services Are
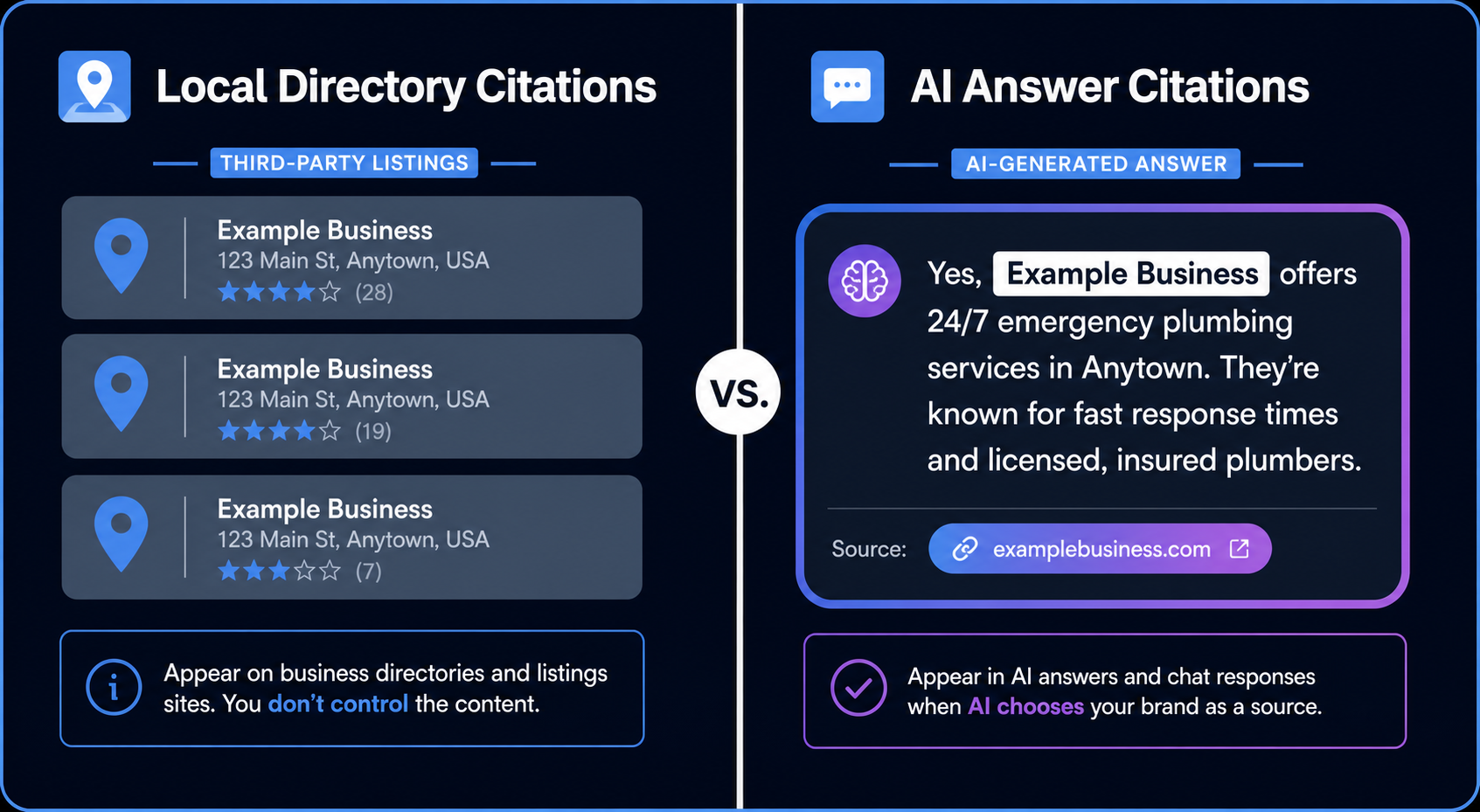
White label link building services are arrangements where a third-party provider builds backlinks for your clients, and your agency delivers that work under its own brand. The provider runs prospecting, outreach, content, and placement. You present the results as if your team did them. The client never sees the vendor.
“White label” means the fulfillment is invisible and the client-facing brand is yours.
Think of it like a private-label product on a grocery shelf. The store’s name is on the box. A different factory made what’s inside. The store still owns the relationship with the shopper.
How This Differs From Generic Outsourced Link Buying
Legitimate white label fulfillment is not the same as buying cheap links in bulk. The difference sits in the process and the standards behind each placement.
Cheap reselling moves volume. A vendor sells you 50 links for a flat fee, sourced from whatever sites accept payment, with no relevance check and no editorial review. That’s where the trouble starts.
Automated link schemes and private blog networks belong in the same risk bucket. They produce placements at speed, on sites that exist only to host links, and they expose your client to the exact patterns Google’s link spam systems flag.
A real white label provider earns placements on sites with genuine audiences, through outreach and editorial standards you can inspect. If you want the foundation on this, our guide to what link building is covers the mechanics before you layer the white label model on top.
What Your Agency Still Owns
Your agency keeps strategy, client communication, and positioning. The vendor handles acquisition and placement only.
In practice, the split looks like this across a real client account. You decide which pages need links and why. You set the narrative the client hears on the monthly call. The provider executes the prospecting and outreach in the background. We’ve watched agencies blur this line and regret it, because once the vendor starts talking strategy, the agency loses the part of the work it actually gets paid for.
Why Agencies Reach for This Model
Agencies use white label link building services to serve more clients without hiring outreach staff, editors, and placement managers. The model trades fixed payroll for variable fulfillment cost, which protects margin and makes capacity planning predictable.
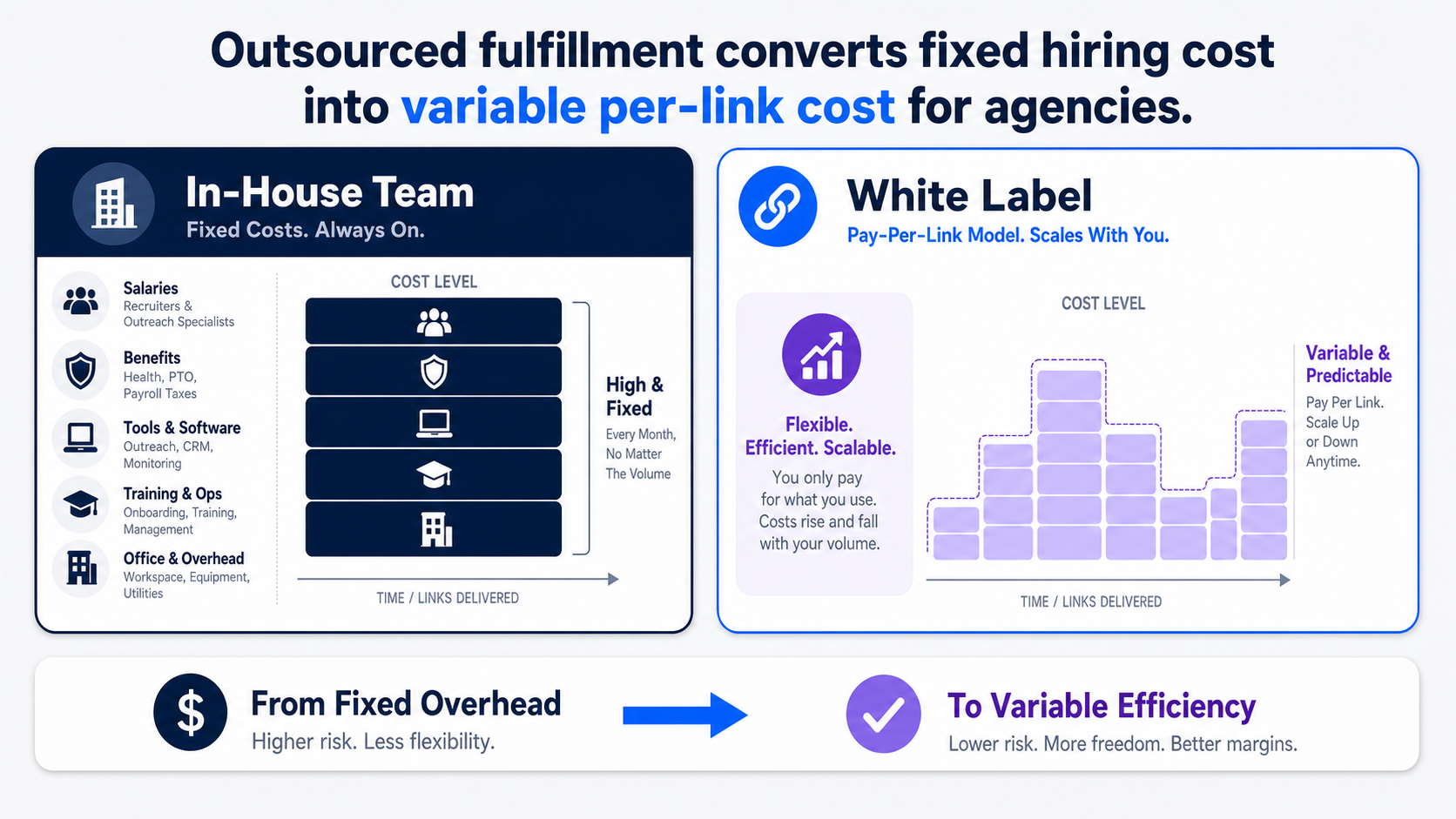
Here’s the business case in plain terms.
Building an in-house outreach team means salaries, training, software, and management overhead before you place a single link. A white label partner converts that into a per-link or per-package cost you only pay when a client needs the work. You scale fulfillment up or down with demand instead of carrying a payroll line through slow months.
The SEO case is just as direct. Backlinks still help search engines judge a site’s authority, relevance, and trust. They remain one of the signals that move organic rankings, which is why clients keep asking for them. Our breakdown of the benefits of link building walks through what actually drives growth, if a client needs convincing.
The Real Value Is Repeatable Access, Not Volume
The value of a white label partner is repeatable access to relevant placements, not the raw number of links per month. A vendor that can deliver 100 irrelevant links is worth less than one that delivers 10 placements on sites your client’s audience actually reads.
Most agencies discover this when they move from founder-led outreach to delegated fulfillment. The founder built links by hand, on sites they personally vetted. The delegated version only works if the partner holds that same standard at scale. That consistency is what you’re really buying.
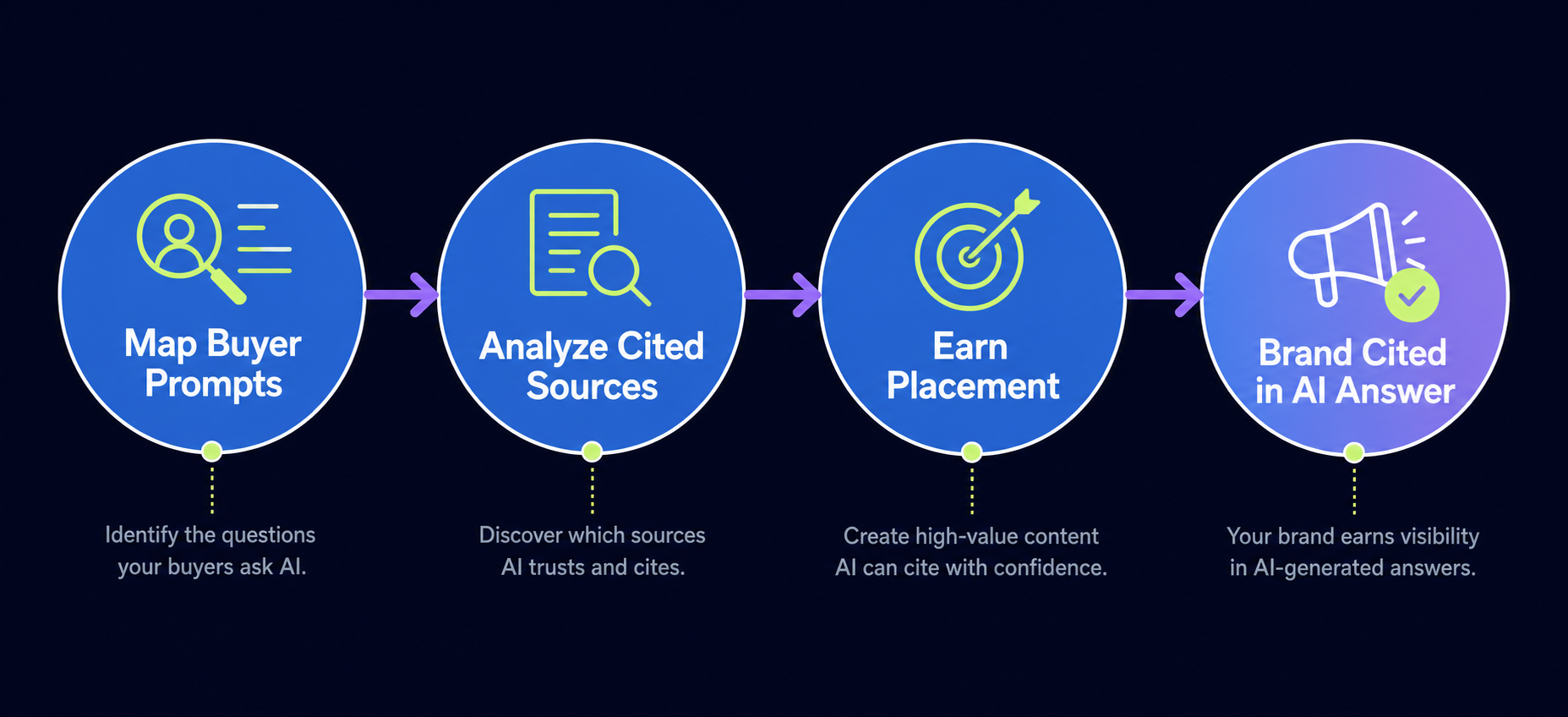
How White Label Link Building Works
The workflow runs from your brief to the provider’s outreach to a branded report. Most of the execution happens behind the scenes, while you keep the strategy and client-facing pieces.

Here is the standard sequence.
- You send the brief: target pages, niche, country, anchor preferences, and risk boundaries.
- The provider builds a prospect list of relevant sites.
- The provider runs outreach and negotiation with publishers.
- An editor reviews the placement content for quality and relevance.
- The link goes live and the provider confirms placement.
- You receive a branded report with live URLs, anchors, and target pages.
What Stays Client-Side
Strategy, approvals, and goal-setting stay with your agency. The vendor never touches the client relationship.
You decide which pages get links and what the anchor mix should look like. You set expectations with the client and report progress against their goals. The provider works from your brief and reports back to you, not to the client.
The Checkpoint Good Providers Don’t Skip
Strong providers pre-approve domains or placements before any outreach goes live. This is the operational checkpoint that separates serious partners from order-takers.
You see the target sites first. You can reject anything off-brand, off-niche, or risky for that client. We treat this as non-negotiable, because a provider that won’t show you domains before placement is asking you to trust links you’ve never seen, on a client account you’re responsible for. Process quality matters as much as link quality here. Opaque workflows create reporting problems and trust problems that surface on the worst possible client call.
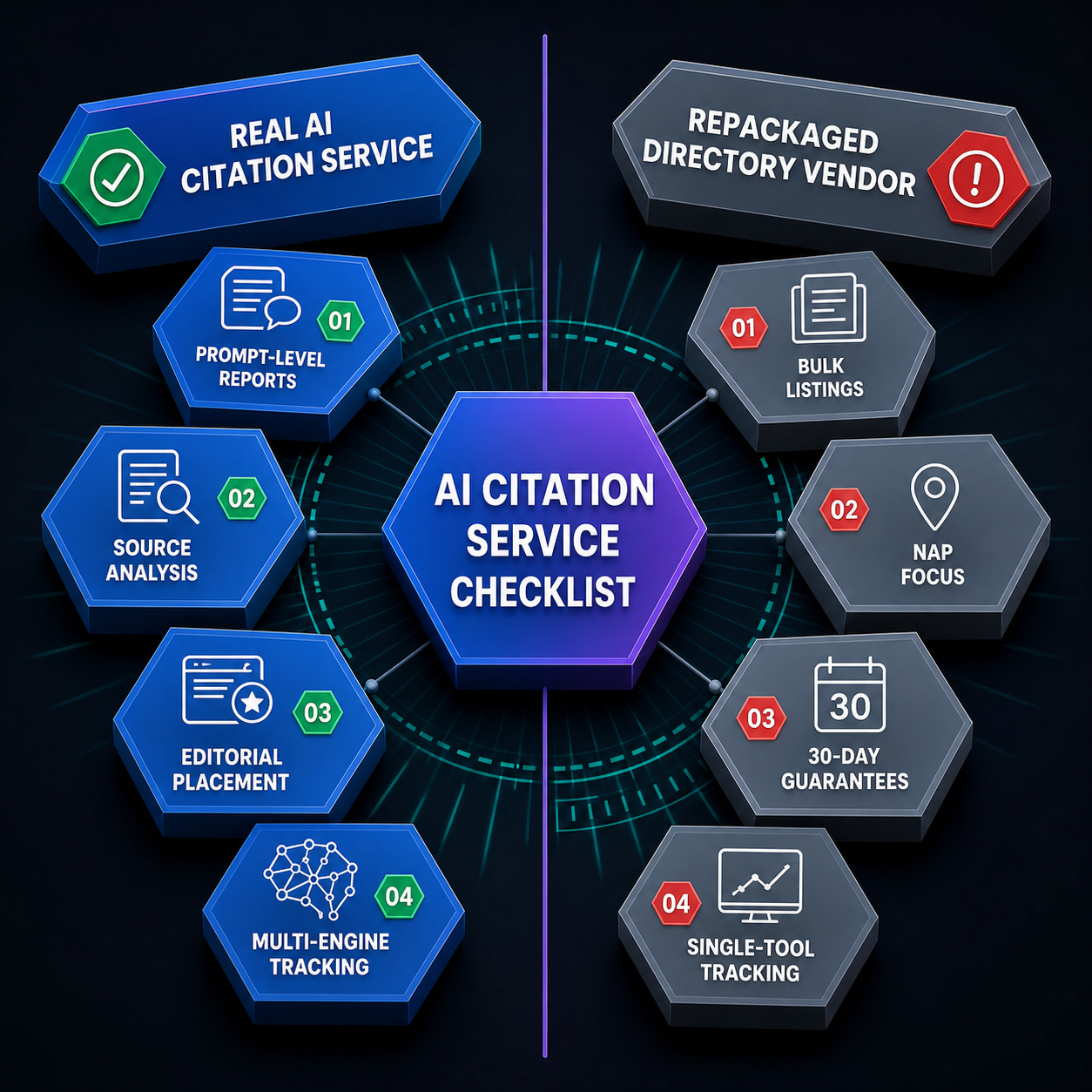
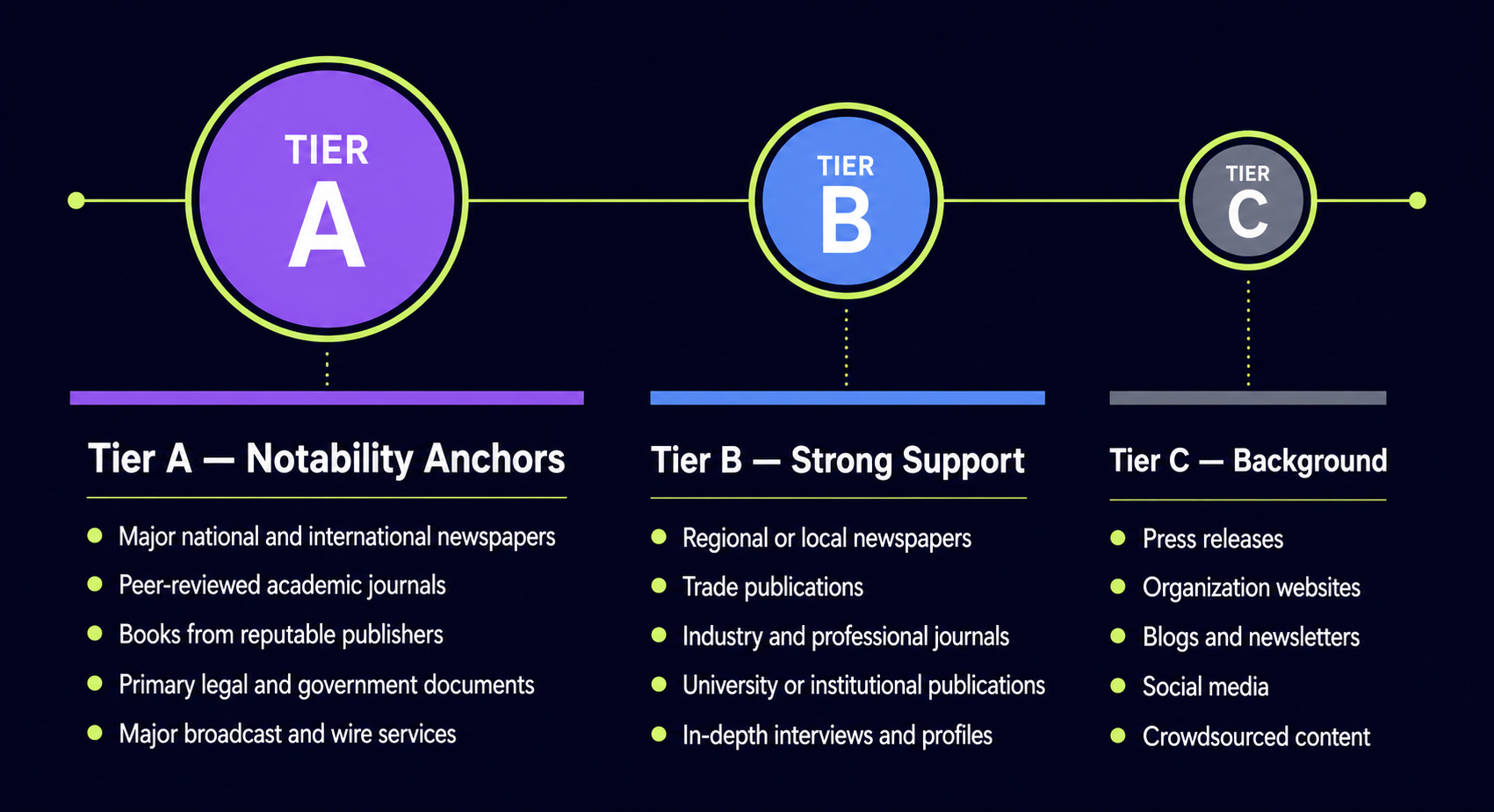
Key Components Agencies Should Evaluate
Evaluate a white label provider on outreach method, content standards, publisher quality, reporting, and service type fit. These five inputs predict whether the placements will hold up under client scrutiny.
Outreach Method
The outreach method tells you how placements are actually earned. Manual outreach, real publisher relationships, editorial pitching, and digital PR all produce links a human agreed to publish. Automated blasts and pay-to-publish networks do not.
Ask the provider to describe their process in detail. A real one can. A reseller will hedge.
Content Standards
Content standards determine whether the placement reads as natural editorial or as an obvious paid insert. Find out who writes the copy, whether it’s unique, and how much editorial control the publisher keeps.
Unique, human-written content placed in relevant context survives editorial review on real sites. Spun or templated content gets you placements on sites that don’t care, which tells you what those sites are worth.
Publisher Quality Signals
Publisher quality comes down to niche relevance, real audience fit, and natural placement context. A site with a genuine readership in your client’s space is worth more than a high-metric site with no topical connection.
This is where agencies most often misread quality, and it’s covered in the mistakes section below.
Reporting Expectations
Good reporting includes live URLs, anchor text, the target page, the publication date, and a branded summary. You should be able to drop the report straight into your client deliverable.
If a provider can’t show you a sample report before you sign, that’s a signal.
Common Service Types and What Each Fits
White label providers offer several link types, and each fits a different job.
| Service type | Best use case | Quality signal to check |
|---|---|---|
| Guest posts | New content placements that build topical relevance on a target page | Site has real traffic and an editorial standard, not a “write for us” link farm |
| Editorial links | Earning a mention inside existing high-authority content | The link sits in genuinely relevant context, not a forced insert |
| Digital PR placements | Authority and brand lift from earned media coverage | Coverage is driven by a real story or data, not a paid slot |
| Niche edits | Adding a contextual link to a published, indexed article | The host article is relevant and the link reads naturally in the body |
| Contextual links | In-content links surrounded by topically aligned text | The surrounding content matches the linked page’s subject |
Each of these has its own depth. Our pieces on editorial link building and contextual link building services go further on the two that agencies use most.
Where Metrics Fit
Domain Rating and Domain Authority are useful inputs, but they never replace relevance and process review. A high Domain Rating on a site with no audience in your client’s niche buys you very little.
Use the metrics to filter, then judge the site on relevance and placement context. That order matters.
The Mistakes That Cost Agencies the Most
The most expensive errors in choosing a provider come from misreading what makes a link good. Here are the five that show up most often.
- Treating low price as a win. A suspiciously cheap link usually means no outreach, no editorial review, and a site that exists to sell links. Price that low is a warning, not a bargain.
- Trusting high Domain Rating on its own. A high authority score means nothing if the site has no real audience and no topical connection to your client.
- Ignoring niche relevance. In most agency campaigns, a relevant link from a modest site beats a generic link from an authoritative one. Relevance is the signal, authority is the filter.
- Treating all links as equal. A link in mismatched context, on a site whose audience has nothing to do with your client, carries little value and can read as manipulation.
- Confusing a fulfillment partner with a thin reseller. A serious partner shows you domains, explains placement logic, and stands behind the work. A reseller hands you a spreadsheet and disappears.
One pattern repeats across agencies that picked the wrong vendor: they bought metrics and never asked to see the placement logic. The links looked fine on a report. They moved nothing for the client, because no one checked whether the sites were relevant or real.
“White label” does not mean anonymous and low-accountability. The fulfillment is invisible to the client, not to you. A provider that hides its process from the agency it works for is hiding something.
When an Agency Should Use This Model
White label link building fits best when your client load is growing, your internal outreach capacity is limited, or you need niche coverage your team doesn’t have. The strongest use case is consistent fulfillment, not one-off emergencies.
The decision comes down to three variables: volume needs, margin goals, and how much quality control you require.
When It’s the Right Call
Reach for a white label partner when demand is outpacing your team. If you’re turning down link work or burning your strategists on outreach, delegated fulfillment frees them for the work clients pay a premium for. The same applies when a client needs placements in a niche your team has no relationships in.
When In-House Still Wins
Keep link building in-house for highly specialized campaigns, very sensitive verticals, or when you already run a mature outreach team. If your agency’s edge is deep relationships in a specific industry, outsourcing that strength rarely makes sense. A firm with a working outreach engine usually shouldn’t replace it with a vendor.
If you’re weighing whether to hire instead of outsource, our guide to working with a link building consultant covers the middle path between in-house and full white label.
Judging a Provider Before You Commit
The best white label providers make it easy to understand what’s being built, why it fits, and how it gets reported. That clarity is the standard. Judge providers on how they operate, not on how much volume they promise.
Walk through the three things that predict good outcomes. Transparency: do they show you domains before placement and share a real sample report? Relevance: do they prioritize topical fit over raw metrics? Repeatable quality: can they hold their standard across dozens of placements, month after month?
A partner who answers all three clearly is worth more than one quoting a lower price per link. Process quality is as important as link metrics, because the process is what produces the metrics in the first place. For the broader execution context, our practitioner guide on how to do link building in 2026 sets the bar your provider should clear.
Frequently Asked Questions
What are white label link building services?
White label link building services are arrangements where a third-party provider builds backlinks for your clients and your agency delivers the work under its own brand. The provider handles prospecting, outreach, content, and placement. You keep the strategy and the client relationship, and the client never sees the vendor. It lets you offer link building without hiring an in-house outreach team.
Are white label link building services safe for SEO agencies?
They’re safe when the provider earns placements through manual outreach and editorial standards, on sites with real audiences. The risk comes from providers using private blog networks, automated schemes, or irrelevant pay-to-publish sites, which expose your client to Google’s link spam systems. Vet the provider’s process, insist on pre-approving domains, and review placement relevance before you commit a client account.
How do white label backlinks work behind the scenes?
You send a brief covering target pages, niche, anchors, and risk boundaries. The provider builds a prospect list, runs outreach and negotiation, has an editor review the content, and confirms the placement once it’s live. You receive a branded report with live URLs, anchor text, target pages, and publication dates. The client sees only your branded deliverable, not the vendor’s involvement.
What should agencies look for in a white label link building provider?
Look for a clear outreach method, unique human-written content, relevant publishers with real audiences, transparent reporting, and a willingness to pre-approve domains before placement. The provider should explain how each link is earned and show you a sample report before you sign. Treat low price and high Domain Rating as filters, not proof of quality. Relevance and process matter more than raw metrics.
Is white label link building better than hiring in-house?
It depends on your client load, margin goals, and niche needs. White label fulfillment wins when demand is growing faster than your team and you need flexible capacity without fixed payroll. In-house wins when you run specialized campaigns, serve sensitive verticals, or already have a mature outreach team with strong publisher relationships. Many agencies blend both, keeping core verticals in-house and outsourcing overflow.
Before you sign with any white label provider, run them through one test: ask to see the domains and the sample report before money changes hands. The ones who say yes are the ones who operate the way you’d want your own team to. Evaluate providers on transparency, relevance, and reporting, and the volume promises sort themselves out.