
If you are wondering whether llms.txt replaces robots.txt, the answer is no. robots.txt remains the crawl-control file, and llms.txt is an optional AI guidance layer, so most sites should treat them as complementary, not interchangeable. They share a name pattern and a home at the site root, and that surface similarity causes most of the confusion. One manages what crawlers are allowed to touch. The other points AI systems toward the content you most want them to read. This article compares them on purpose, support, control, and practical use so you can decide what your site actually needs.
What llms.txt and robots.txt Are
robots.txt is the long-established crawler directives file at the root of a domain, and llms.txt is an emerging guidance file that points AI systems toward a site’s preferred content. robots.txt has shipped on the web for decades and is read by search crawlers before they fetch your pages. llms.txt is newer, proposed at llmstxt.org, and meant to give large language models a curated map of what matters most.
The split is simple once you say it plainly. robots.txt is about crawl control and exclusion. llms.txt is about curation and discovery. One sets boundaries. The other makes recommendations.
llms.txt does not block access, approve access, or replace any permissions control. It cannot lock a private folder or grant a crawler entry. If you want a page kept out of reach, that job belongs to robots.txt and your server, not to a guidance file.

In technical audits, robots.txt is the first file checked when crawl issues surface. llms.txt only comes up after the crawl and index basics are already clean, because a guidance file means nothing if bots cannot reach the pages it points to. If you are new to the format itself, our explainer on what llms.txt is covers the structure in depth.
What We’re Comparing and Why It Matters
You are really deciding one thing: do you use robots.txt only, both files, or neither. The naming similarity pushes people toward a false framing where llms.txt is the AI version of robots.txt. It is not. One file manages bot behavior. The other guides AI consumption of content you have already published.
To keep the comparison honest, the rest of this article judges both files through the same lens.
| Lens | What it asks |
|---|---|
| Primary function | What is the file actually for? |
| Who reads it | Which bots act on it today? |
| Access control | Can it allow or block a crawler? |
| Crawl and index impact | Does it change what gets fetched or indexed? |
| Support level | Is it established or emerging? |
| Best use case | When is it worth maintaining? |
Both files coexist without conflict when each does the job it was built for. This matters for visibility on two surfaces at once: classic search results, where crawl access decides what gets indexed, and AI answer engines, where content discovery shapes what gets surfaced and cited.
Evaluation Criteria for the Comparison
Six criteria decide how each file scores: primary function, who reads it, whether it controls access, its impact on crawl and citation behavior, current support, and best use case. Naming similarity and hype do not make the list, because in real SEO reviews, enforceability matters more than what a file is called.

Two of these criteria carry the most weight. Support tells you whether bots actually act on the file, and access control tells you whether the file can enforce anything at all. A file that no bot honors is a suggestion, not a directive.
Primary Purpose and Bot Behavior
robots.txt is widely respected by traditional search crawlers like Googlebot and Bingbot, which read it before fetching pages and obey its disallow rules. llms.txt is still emerging, and AI systems may read it, ignore it, or use only part of it depending on the platform. That gap in support is the single biggest practical difference between the two.
| Behavior | robots.txt | llms.txt |
|---|---|---|
| Read by search crawlers | Yes, consistently | Not its purpose |
| Acted on by AI crawlers | Increasingly, for access | Uneven, platform dependent |
| Enforces a rule | Yes, disallow is honored | No, guidance only |
| Primary role | Control layer | Guidance layer |
Reading a file and acting on its contents are two different things. A crawler can fetch your llms.txt without any guarantee that the pages it lists get indexed or cited. robots.txt enforces a boundary. llms.txt offers a recommendation that a model is free to follow or skip.
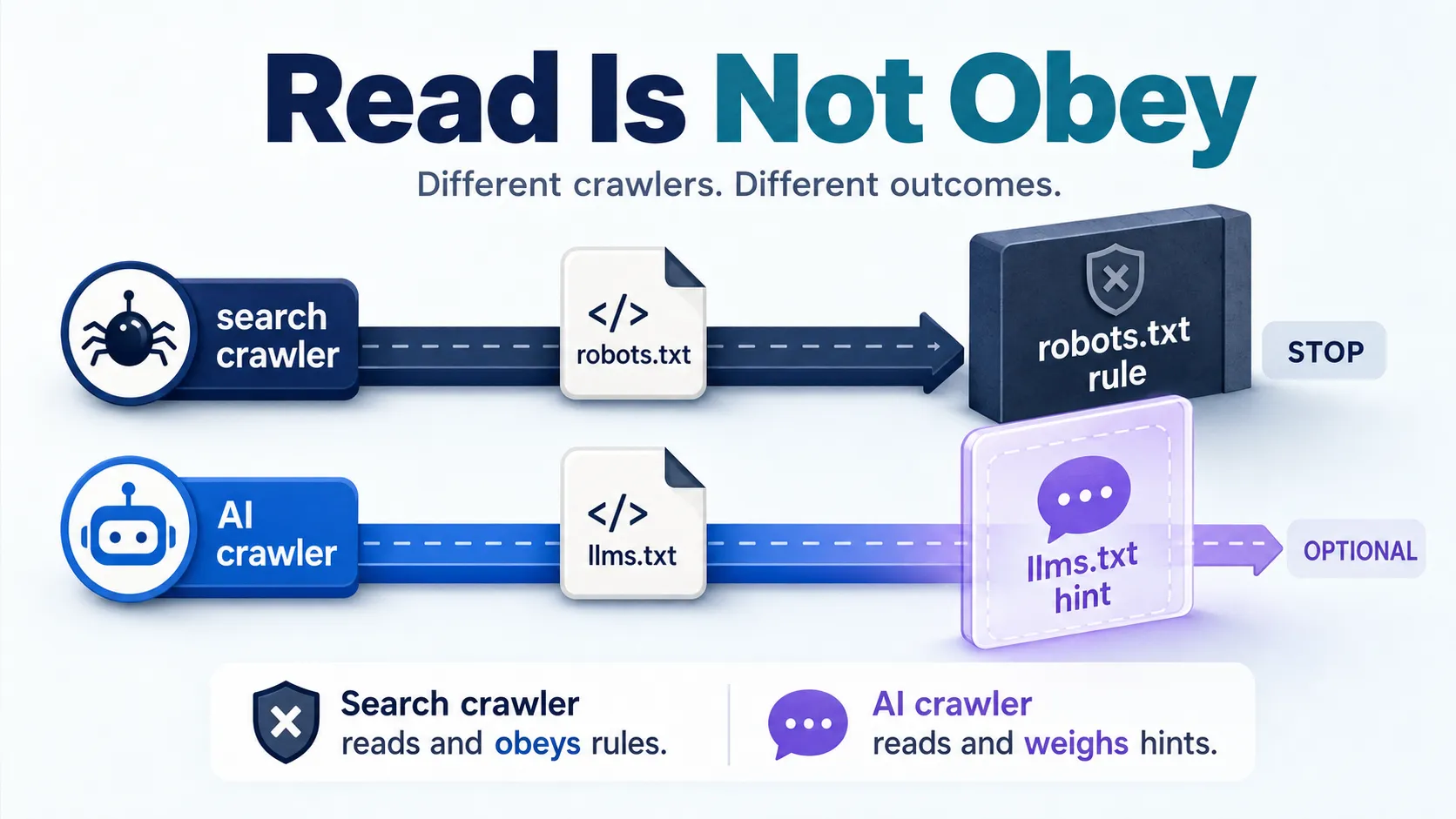
You can validate robots.txt fast. Change a disallow rule and server logs show the effect within a crawl cycle. llms.txt is harder to confirm, because platform support is uneven and few engines report whether they read it. If you want to see which bots actually visit, our guide on tracking AI bots on your site walks through the log analysis.
What Each File Can and Cannot Do
robots.txt can block crawl paths, reduce crawl waste, and steer where bots spend their attention. It cannot guarantee a page stays out of the index if that URL is discovered through links elsewhere, because disallow stops crawling, not indexing. For a true block from results, you need a noindex directive or authentication, not robots.txt alone.
llms.txt can point AI systems toward preferred docs, product pages, FAQs, and other high-value resources you want read first. It cannot block access, force a citation, or act as a permissions layer. Listing a page in llms.txt is an invitation, never a guarantee of inclusion.
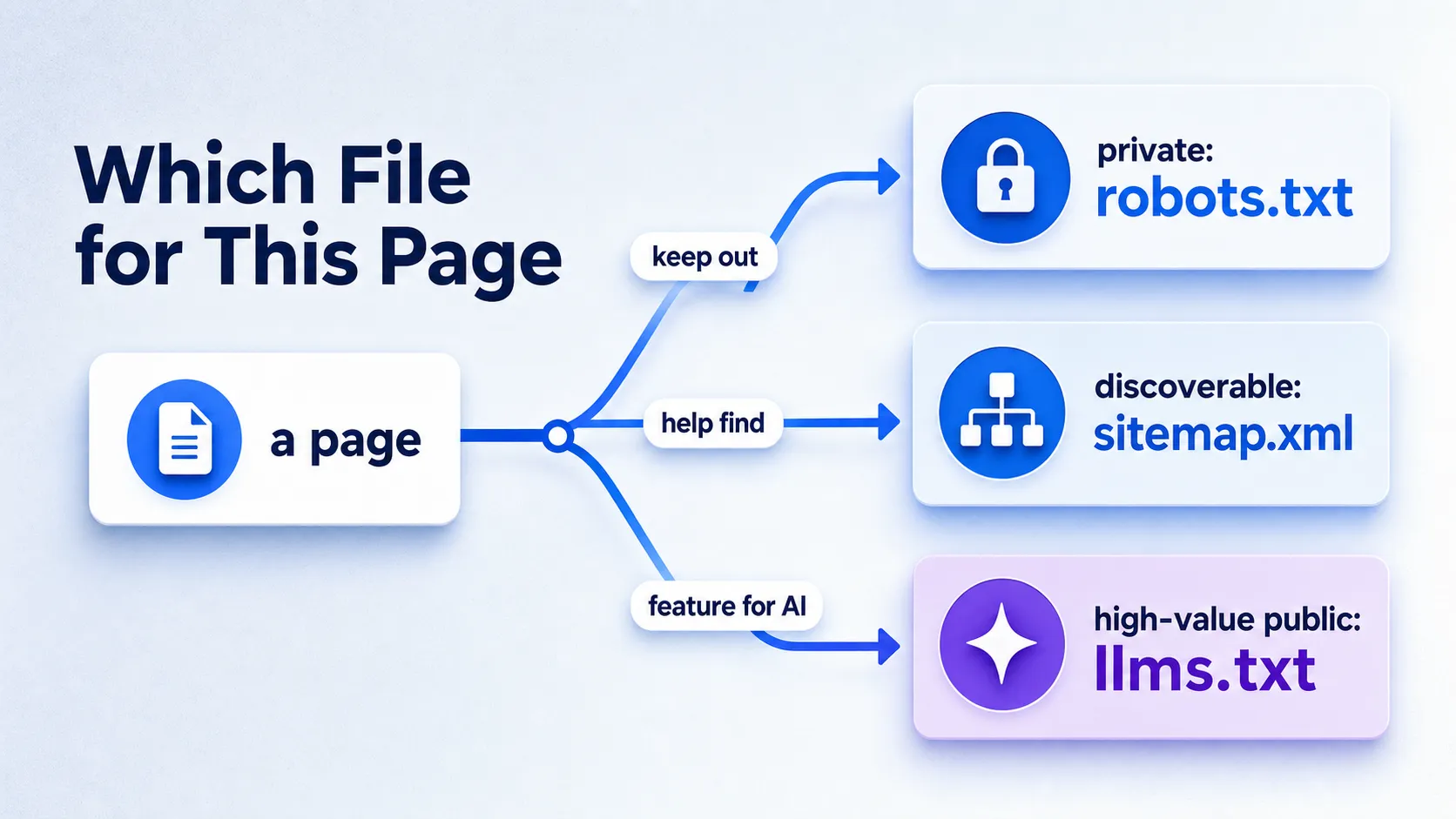
| Capability | robots.txt | llms.txt | sitemap.xml |
|---|---|---|---|
| Block a crawler | Yes | No | No |
| Steer crawl budget | Yes | No | Partly |
| Help search discovery | No | No | Yes |
| Guide AI to key content | No | Yes, when honored | No |
| Guarantee indexing or citation | No | No | No |
The third file in that table trips up most teams. sitemap.xml is the XML sitemap that lists URLs for search engines to discover, and it is a discovery tool, not a control or AI-guidance file. Confusing discoverability with control is the core mistake here. robots.txt restricts the bot. sitemap.xml helps search engines find URLs. llms.txt nudges AI toward your best pages. Three jobs, three files.

Setup, Format, Maintenance, and Practical Use Cases
robots.txt is a mature technical SEO asset with well-understood placement and maintenance habits. It sits at the root, uses a plain user-agent and disallow syntax, and rarely needs touching once it is clean. llms.txt is a curated convention written in Markdown, and it needs ongoing page selection as your content priorities shift. Both live at the site root and should stay readable and easy to update.
Use robots.txt when you need to manage access and crawl efficiency.
- Block private sections like ****SECRET_REDACTED**** or account areas.
- Control crawl budget on large sites with many low-value paths.
- Keep duplicate or faceted URLs out of crawl rotation.
- Hide staging or utility pages from crawlers.
Use llms.txt when you have a small, stable set of pages that genuinely deserve AI attention.
- Documentation hubs and developer references.
- Core product pages and pricing.
- Knowledge bases and support FAQs.
- Evergreen educational content and structured resources.
On larger content sites, llms.txt only works when it highlights a small, stable set of URLs that truly deserve attention. Dumping every page into it defeats the point, since the value is curation. When you build the file, our walkthrough on how to write llms.txt covers structure and page selection. To understand which signals AI engines weigh once they read your pages, see how AI crawlers pick sources.
Verdict by Use Case: robots.txt Only, llms.txt Only, or Both?
The honest answer is scenario-based, so match the file to your actual need rather than the trend.
| Your situation | What to do |
|---|---|
| You need crawl control and basic technical SEO hygiene | Use robots.txt. This is non-negotiable for any site. |
| You have high-value pages you want AI to find first | Add llms.txt on top of a clean robots.txt. |
| You run most public sites with both search and AI visibility goals | Use both. They solve different problems and never replace each other. |
| You run a small, thin, or low-priority site with no AI focus | Skip llms.txt for now and keep robots.txt tidy. |
The recommendation hierarchy is control first, guidance second. Get robots.txt right, confirm your pages are crawlable and indexed, then layer llms.txt as an optional boost. The most common winning pattern is not replacing robots.txt. It is adding llms.txt on top of a setup that already works. For a wider view of what to measure once both are live, compare AI visibility against SEO metrics.
Frequently Asked Questions
Is llms.txt a replacement for robots.txt?
No. They do different jobs and one cannot stand in for the other. robots.txt controls crawler access and exclusion, while llms.txt only suggests which content AI systems should prioritize. Removing robots.txt and relying on llms.txt would leave your crawl control with no enforcement at all.
Do AI crawlers actually respect llms.txt?
Support is uneven and platform dependent right now. Some AI systems read llms.txt and some ignore it, and no major provider treats it as a hard directive. Treat it as guidance that may help, not a setting you can rely on. This is why control and validation still run through robots.txt and server logs.
Should I block AI crawlers in robots.txt?
Only if you have a clear reason to keep your content out of AI training or answer surfaces. Blocking AI crawlers in robots.txt is a valid choice for sensitive or licensed content, but it also removes your chance of being cited in AI answers. Most brands chasing visibility want the opposite: to be read and surfaced, not excluded.
Do I need both llms.txt and robots.txt on my site?
Most public sites benefit from both because they cover separate needs. robots.txt manages access and crawl efficiency, which every site needs, and llms.txt guides AI toward your best pages, which matters if AI visibility is a priority. A small site with no AI focus can run robots.txt alone without missing much.
What is the difference between llms.txt and sitemap.xml?
sitemap.xml lists URLs for search engines to discover, while llms.txt curates a short set of pages for AI systems to read. The sitemap aims for completeness and feeds traditional search indexing. llms.txt aims for selectivity and feeds AI content discovery. They serve different audiences and rarely overlap in practice.
The Practical Read on Both Files
robots.txt is the standard control layer your site cannot do without, and llms.txt is an optional guidance layer worth adding once your crawl setup is clean. They are complementary, not interchangeable, and treating one as a substitute for the other is where most sites go wrong. Start by confirming your robots.txt does its job, then decide whether a curated llms.txt earns its place. Want to know how AI engines actually see your site today? Get a free AI visibility audit and find out where you stand.
