
A GEO score benchmark isn’t a universal grade. It’s the reference point that tells you whether your AI-search readiness is actually improving.
A “good” GEO score only means something inside the methodology that produced it, against a comparison set that matches your pages. The raw number from any single checker is close to meaningless on its own.
What turns it into a decision is the benchmark frame: the score band, the competitor set, or the prior reading you measure against. This guide covers what the score measures, how it gets normalized, and the interpretation mistakes that make the exercise pointless.

Key Takeaways
- A GEO score is meaningless without a benchmark frame: a score band, a competitor set, or your own prior reading.
- Two sites can earn the identical score for opposite reasons, so the number alone never tells you what to fix.
- Scores from different tools are not comparable; pick one methodology and stay inside it.
- A high score means a page is ready to be cited, not that any engine has chosen to cite it.
- Page-level review beats the site-wide average, since a strong average can hide weak high-intent pages.
- Fix crawl and extraction blockers first, then validate against real AI search, before chasing a higher number.
What a GEO Score Benchmark Actually Is
A GEO score benchmark is the standard you compare a GEO score against to decide whether the number is good, average, or weak for your situation. The score is the measured result.
The checker or calculator is the tool that produces it. The benchmark is the frame that gives it meaning.
Most teams collapse these three things into one and treat the score as self-explanatory. It’s not. A 72 from one tool and a 72 from another can describe entirely different sites, because each tool weights its signals differently.
“Benchmark” here means a comparison frame, not a fixed industry pass mark. There’s no official line above which your AI-search readiness becomes “good.” A benchmark can be a score band the tool defines, your nearest competitors, your own past reading, or a peer group in your category.
Two sites can earn the identical score while having opposite strengths. One scores well because its pages are highly crawlable and fast.
Another hits the same number on the strength of clean structured data and tight entity signals, while its extractability lags. Same number, different stories, different fixes.
| Term | What it is | What it answers |
|---|---|---|
| GEO score | The measured result, usually 0 to 100 | How ready is this page or site, by this tool’s logic? |
| GEO checker | The tool that runs the checks | What signals are being assessed? |
| Benchmark range | The standard you read the score against | Is this number good, relative to what? |
The common practitioner mistake is treating a score as meaningful before asking how the tool weights its signals. A number with no weighting context is a vanity metric.
Ask what the tool measures and how it normalizes before you act on a single point of it. For a fuller view of what to track instead of vanity numbers, see how AI visibility differs from SEO metrics.
Why Benchmark Context Matters for AI-Search Readiness
A raw GEO score is too easy to misread, which is exactly why benchmark context is essential. AI-search visibility is volatile.
The same page can score differently from one week to the next because the model changed, the prompt set shifted, or crawl conditions varied. A score that moves doesn’t always mean your site moved.
This volatility is what makes a standalone number dangerous. A team sees a 70 and celebrates, then assumes citations will follow.
They often don’t. The score measures readiness signals, not whether ChatGPT, Perplexity, or Gemini actually names you in an answer.
Readiness and citation are related, not the same.
Benchmark context fixes this in three ways. It lets you prioritize fixes by showing which signal lags relative to a standard.
It lets you compare against relevant peers rather than an arbitrary threshold. And it lets you track real progress, because a 70 this month against a 62 last month, same pages and tool, is genuine movement.
For marketers reporting up to leadership, this matters even more. A bare readiness score sounds vague in a board deck. The same score framed against last quarter and against two named competitors becomes a business-ready comparison that a CMO can act on.
The practitioner reality: the same page can look “strong” in one tool and “average” in another, purely because the benchmarking frame changed. Neither tool is lying.
They’re answering different questions. Pick one frame, stay in it, and judge movement within it rather than chasing the highest number across tools.
How GEO Scores Are Measured and Normalized
A GEO score is built by running checks on your pages, weighting them, and normalizing the result onto a single scale, usually 0 to 100. Understanding the inputs tells you where the number comes from and why it moves.
Most GEO scoring systems assess some mix of these inputs:
- Technical accessibility: can AI crawlers reach and read the page?
- Structured data: is the page marked up so machines can parse it?
- Content extractability: is the content formatted so an answer engine can lift a clean passage?
- Entity clarity: is it obvious which brand and topic the page is about?
- Authority and trust signals: does the source look credible enough to cite?
- Freshness: is the content recent enough for queries where recency matters?
Here is the basic logic most tools follow to turn those checks into a single number.
Step 1: Run the Raw Checks
The tool inspects each page for the signals above and records a pass, fail, or graded result per signal.
Step 2: Apply Weighting
Some tools weight signals so extractability or accessibility counts more than freshness. Others use simple binary checks, and some blend both into a composite model.
Step 3: Normalize to a Scale
The weighted results get mapped onto a common scale, usually 0 to 100, so a messy set of checks becomes one comparable figure.
Step 4: Roll Up or Break Out
The tool either reports one site-wide average or shows per-page scores, and those two views often tell different stories.
The score is only as reliable as the page sample, prompt set, and weighting behind it. The most useful benchmark systems do more than grade the site.
They reveal which single signal is capping your performance, so you know where to push first. A diagnostic view beats a grade every time, which is the logic behind a structured AI visibility diagnostic framework.
What a “Good” GEO Score Looks Like
A good GEO score only means something relative to the tool’s methodology, the page type, and the comparison set you chose. There’s no universal threshold that makes a site “good” across every checker, because each tool defines its own scale and weighting.
Treat any absolute number with suspicion unless the tool that produced it explicitly defines its bands. A “70 is good, 85 is great” claim is true only inside that one product’s logic. Carry it to a different tool and it falls apart.
The bands below are illustrative and methodology-specific, not an industry standard. Use them to understand what each tier feels like, not as numbers to chase.
| Band | What it means in plain language |
|---|---|
| Weak | Important gaps remain. Crawlers may be blocked, structure is thin, or entity signals are unclear. |
| Average | The baseline is in place but not consistently competitive. The page works, but it does not stand out. |
| Strong | The site is structurally ready for AI search, but readiness still needs validation in real answers. |
| Elite | Benchmark signals are strong and the site is usually well-positioned, yet citations still need live testing. |

Even “elite” isn’t a finish line. Strong signals make a site likely to be surfaced, but they don’t guarantee an engine names you. The gap between a high score and an actual citation is where most readiness narratives quietly break.
One pattern shows up on nearly every team: they overvalue the site-wide average and miss the pages that actually win or lose AI citations. A site averaging 68 can hide a handful of 40s on exactly the high-intent pages you most need cited. Page-level review is almost always more useful for action than the headline average.
The Benchmark Types and Dimensions You Should Compare
There are five benchmark types worth knowing, and which one you use depends on whether you want relative positioning or internal tracking. Each answers a different question.
| Benchmark type | Best for | What it tells you |
|---|---|---|
| Absolute score range | Internal tracking over time | Whether your own readiness is rising or falling |
| Competitor benchmark | Relative positioning | Where rivals out-position you in AI answers |
| Industry benchmark | Category context | How your category typically scores |
| Page-level benchmark | Pinpointing weak pages | Which specific pages drag readiness down |
| Site-wide benchmark | Executive reporting | The headline readiness picture for leadership |
Competitor benchmarks are best when you want to know if you’re winning or losing relative to peers. Absolute ranges are best when you want a clean before-and-after on your own pages, free of competitor noise.
The dimensions you compare matter as much as the type. Each one carries a different job:
- Technical accessibility decides whether crawlers can reach the page at all.
- Structured data makes the page machine-readable.
- Content extractability lets an answer engine lift a clean, citable passage.
- Entity clarity helps the model understand which brand and topic the page covers.
- Authority and trust signals influence whether a source gets selected for citation.
- Freshness matters most for queries where recency carries weight.
Different query types value different dimensions. A product page, a comparison page, and a glossary entry won’t benchmark the same way, because the model weights extractability and freshness differently for each. The right markup helps here, which is why entity SEO and clean schema do real work for machine readability, alongside a clear llms.txt file for crawler access.
Once a site is already crawlable, extractability and entity clarity usually explain more benchmark movement than further technical fixes. Teams keep polishing speed and accessibility long after those signals are maxed out, while the real ceiling is content that an engine can’t cleanly extract.
Common Mistakes When Reading GEO Score Benchmarks
Most of the value lost in GEO scoring comes from a handful of interpretation errors. Each one turns a useful diagnostic into a misleading dashboard number.
Mistake 1: Assuming a High Score Guarantees Citations
Wrong reading: “We hit 80, so AI will cite us.”
Correct reading: a high score means the page is ready to be cited, not that any engine has chosen to.
Mistake 2: Treating One Tool’s Score as an Industry Standard
Wrong reading: “70 is the bar everyone uses.”
Correct reading: that band is defined by one tool’s logic and does not transfer.
Mistake 3: Comparing Scores Across Tools With Different Logic
Wrong reading: “Our 72 here beats their 68 there.”
Correct reading: two scores from two methodologies are not comparable at all.
Mistake 4: Ignoring Category, Query, and Model Differences
Wrong reading: “One score covers all our pages.”
Correct reading: a glossary page and a comparison page benchmark differently, and so does ChatGPT versus Gemini.
Mistake 5: Trusting the Score Over Real AI-Search Tests
Wrong reading: “The dashboard says we are ready.”
Correct reading: the only proof is running your buying queries through ChatGPT, Perplexity, Gemini, Claude, and AI Overviews and seeing whether you appear.
The recurring team failure mode is optimizing for the dashboard score instead of the actual answer engines. A benchmark should guide action, never replace live verification.
The score points you at the problem. The engines tell you whether you solved it.
How to Use Your GEO Benchmark to Prioritize Fixes
A benchmark becomes useful the moment you turn it into a workflow. The goal is AI-search readiness that shows up in real answers, not a prettier number. Follow these steps in order.
Step 1: Set a Clean Baseline
Take your first reading from one methodology, on a fixed set of pages, against one comparison set. Mixing tools or page sets now makes every later comparison noise.
Step 2: Fix the Highest-Impact Blockers First
Clear technical accessibility before content polish. A page no crawler can reach scores poorly for a reason that no amount of writing fixes. Understanding which generative engine optimization tools surface these blockers speeds this step up.
Step 3: Re-test in the Same Frame
Run the same tool, same pages, same benchmark after your changes. Progress is only readable when the frame holds constant.
Step 4: Validate Against Real AI Search
Check the actual engines for your priority queries. If the score rose but you’re still not named, the fix was cosmetic. Trust the answer, not the dial.
Step 5: Track on a Cadence
Treat the benchmark as a monthly or biweekly signal, not a one-time audit. AI-search readiness drifts, so a single snapshot ages fast. An AI Overview optimization checklist works well as the recurring review against which you re-score.
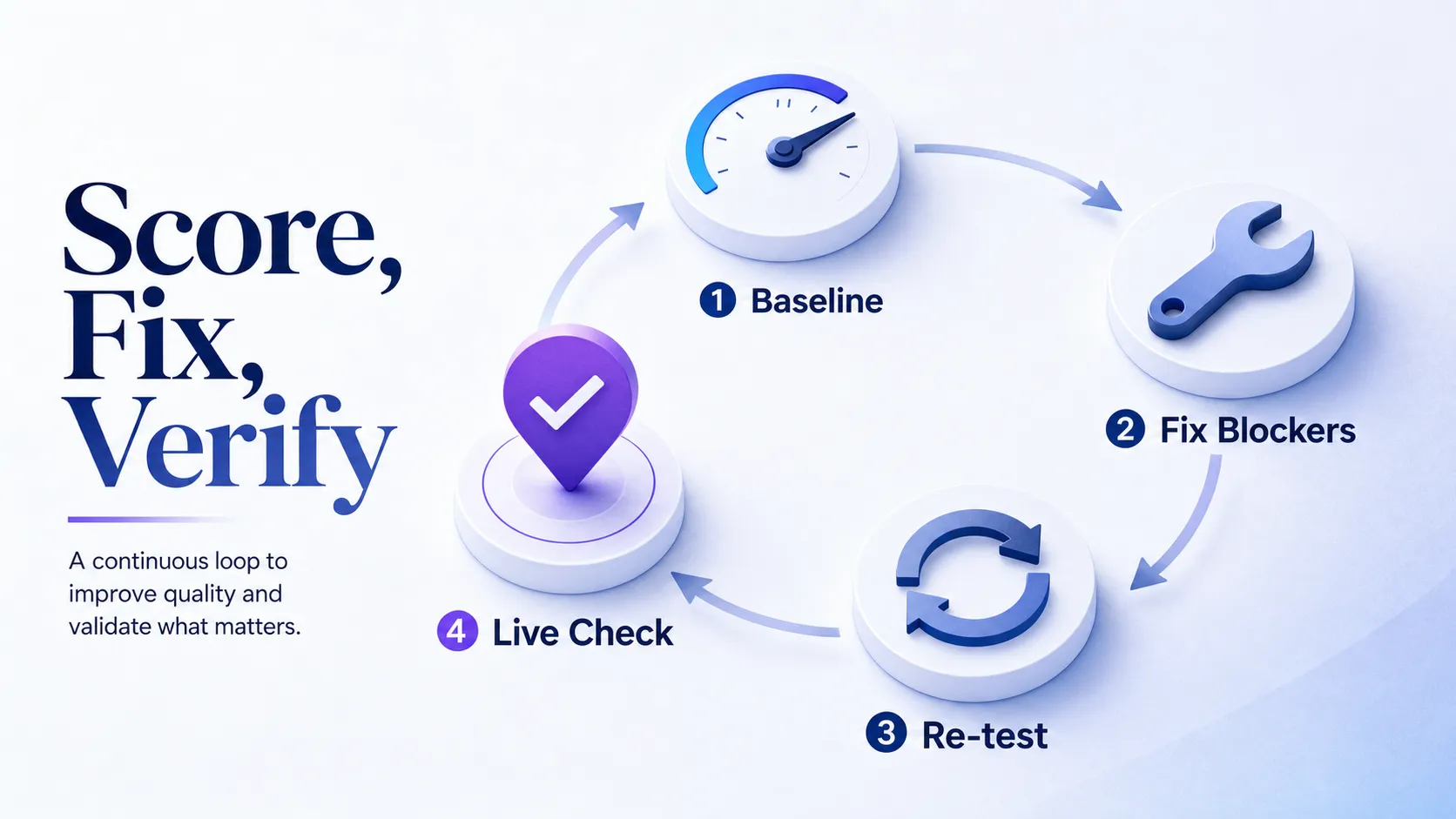
The order matters more than the speed. Teams that win at AI-search readiness fix what blocks crawling, then what blocks extraction, then validate live, and only then chase a higher number. Run the steps in reverse and you polish a score that no engine ever reads.
Frequently Asked Questions
What is a GEO score benchmark?
A GEO score benchmark is the standard you compare a GEO score against to judge whether it’s good, average, or weak. The score measures AI-search readiness on a scale like 0 to 100. The benchmark is the frame, a score band, a competitor set, or a prior reading, that turns that number into a decision.
What is a good GEO score?
A good GEO score is one that is strong relative to the tool’s own bands, your page type, and your comparison set. There’s no universal “good” number across tools, because each checker defines its own scale and weighting. A 75 in one tool and a 75 in another can describe very different sites, so judge the score inside one consistent frame rather than against a borrowed threshold.
How is a GEO score calculated?
A GEO score is calculated by running checks on signals like technical accessibility, structured data, content extractability, entity clarity, authority, and freshness. Those checks get weighted and normalized onto a single scale. Some tools weight signals, others use binary checks, and many blend both. The score is only as reliable as the page sample and weighting behind it.
Can you compare GEO scores across different tools?
No, comparing GEO scores across tools is not reliable. Each tool uses its own signals, weighting, and normalization, so a 72 from one checker isn’t equivalent to a 72 from another. If you need to compare, pick one tool and stay inside its frame. Use the same methodology, the same pages, and the same comparison set every time you re-score.
Does a higher GEO score guarantee citations in AI search?
No. A higher GEO score means a page is more ready to be cited, not that any engine has chosen to name it. Readiness signals and actual citations are related but separate. The only proof is running your priority queries through engines like ChatGPT, Perplexity, Gemini, Claude, and AI Overviews and checking whether your brand appears in the answer.
Read the Score, Then Read the Engines
A GEO score benchmark is a compass, not a destination. It points you at the signal holding your AI-search readiness back and gives you a frame to measure progress in.
What it can’t do is tell you whether an engine actually names your brand. That answer lives in the engines, not the dashboard.
Set a clean baseline, fix the highest-impact blockers, re-score in the same frame, then validate against real AI search before you trust the number.
Want to know where you stand before you start fixing? Get a free AI visibility audit and see what AI search says about your brand and your competitors today.
