
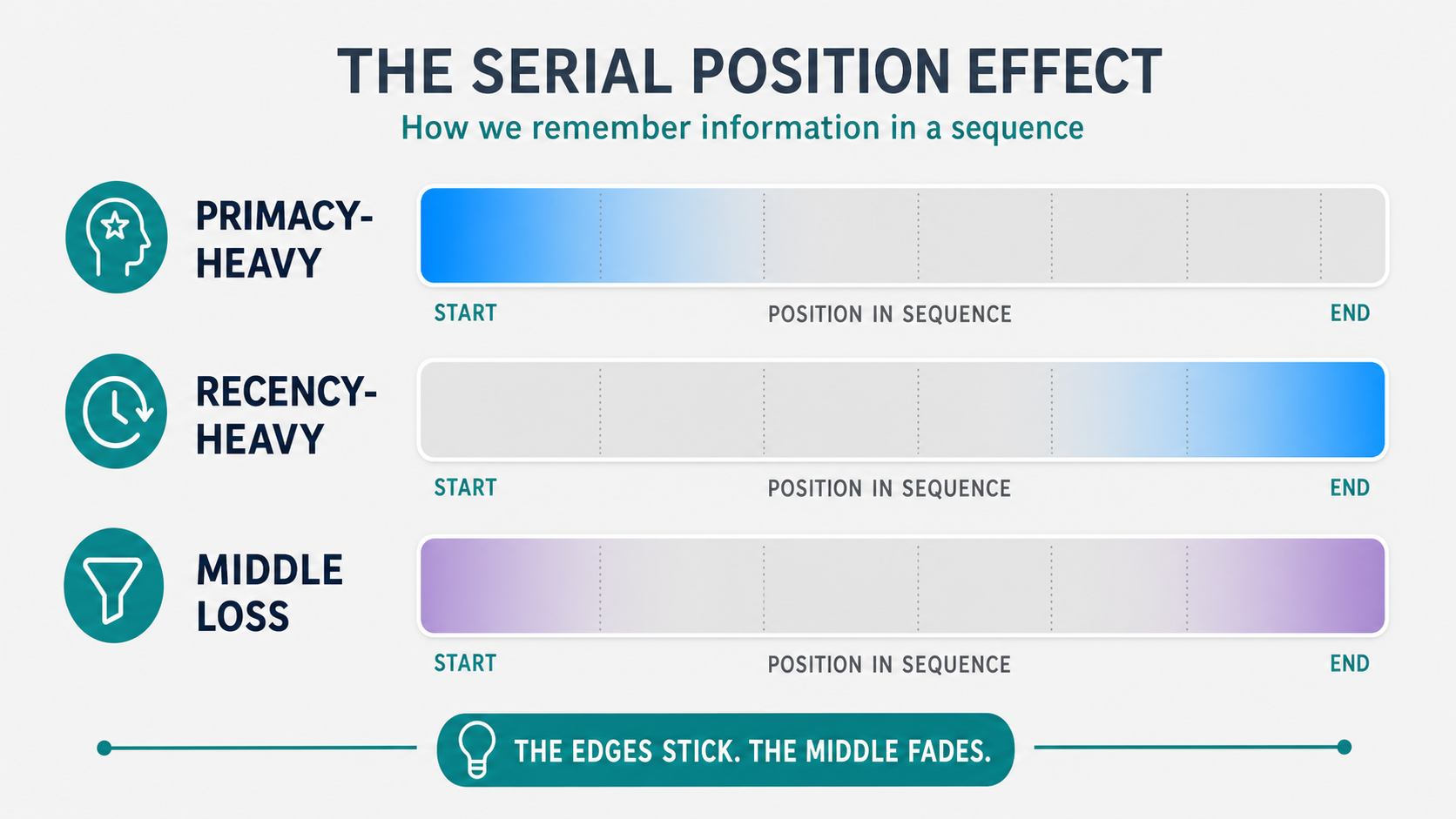
The LLM content recency primacy effect is why the first and last parts of a prompt or page often shape the answer more than the middle. Large language models do not weight every token in a context window equally. Information at the start and the end tends to carry more pull than the material buried in between.
This is a positional weighting tendency, not a universal law, and it can influence both prompt results and how often your content gets surfaced in AI-generated answers. The effect borrows its name from a psychology concept, but the mechanism inside a model is about attention and token position, not memory.
You will see it most clearly when a critical instruction sits in the middle of a long prompt and the model quietly ignores it. Move that same instruction to the first or last line, and it survives. That single observation is the practical heart of this article.
- Primacy means the beginning of a prompt or context window gets extra weight. Recency means the end does.
- The middle is the weak zone, a pattern researchers call “lost in the middle.”
- The effect is a tendency that varies by model, task, and prompt structure. It is not a fixed rule.
- Placement can shape which facts a model uses and which content sections AI systems surface, but it does not guarantee accuracy or control.
What the LLM Content Recency Primacy Effect Is
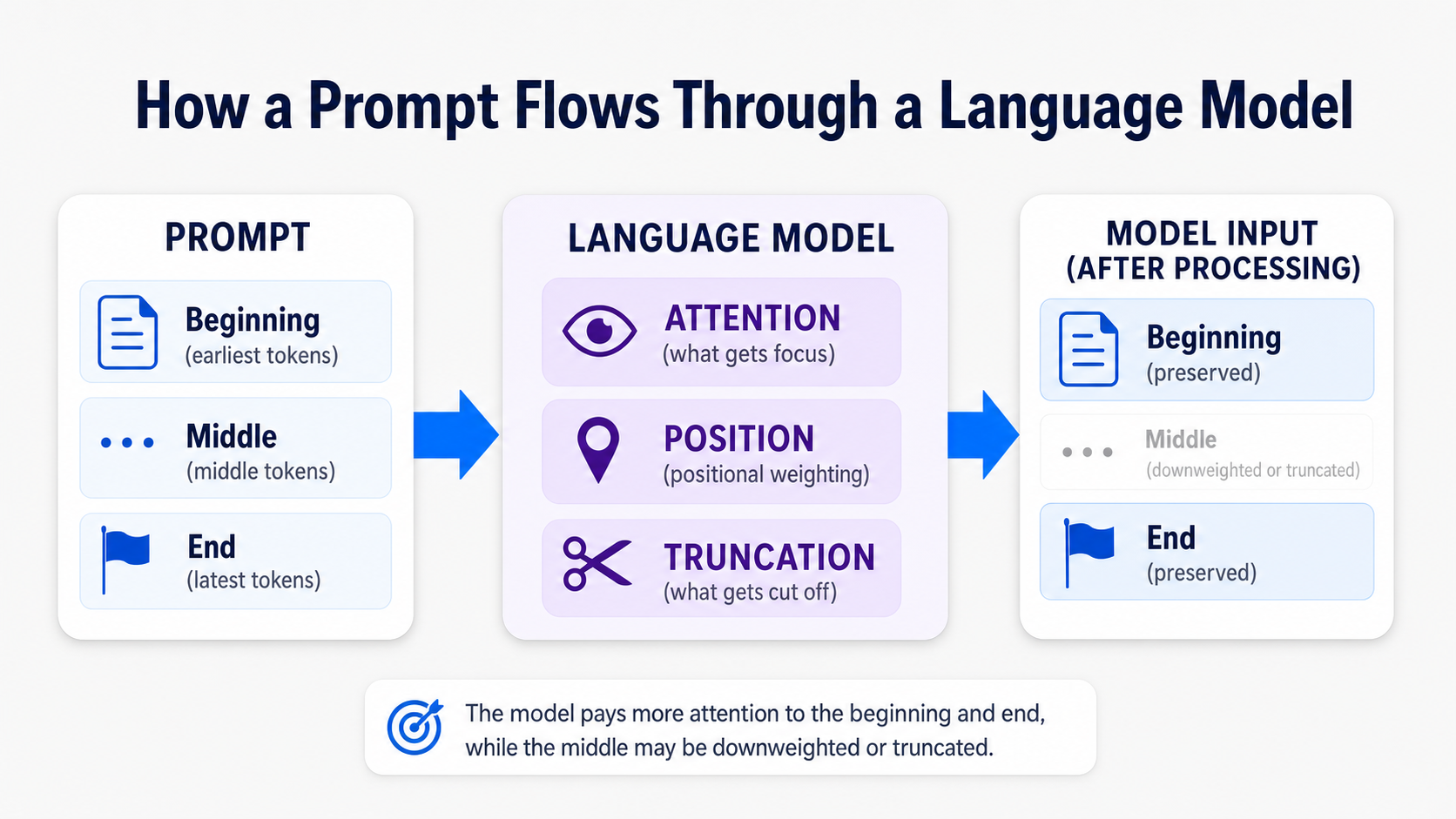
The LLM content recency primacy effect describes the way language models give extra weight to information at the beginning and the end of an input while underweighting the middle.
It combines three related ideas into one working concept.
Primacy is the tendency for content at the start of a prompt or context window to receive more weight. Early instructions, early facts, and early examples often shape the response more than they should on a purely neutral reading.
Recency is the mirror image. Content at the end of the prompt or context window gets the strongest recent pull, which is why the last instruction you give frequently wins when two instructions conflict.
The serial position effect is the umbrella term. It comes from cognitive psychology, where people recall the first and last items in a list better than the items in the middle. Researchers borrowed the label because the curve looks similar when you chart LLM behavior across token positions.
One clarification matters more than any other here. An LLM does not “remember” the way a person does. There is no working memory holding the last few items. What you are seeing is a product of attention distribution, positional encoding, and patterns baked in during training. The output looks human-like, but the cause is mechanical.
That distinction keeps you from overreaching. You are not appealing to a model’s short-term recall. You are working with how the architecture distributes weight across positions, and that weight shifts with the task in front of it.
Why It Matters for Prompts, Answers, and AI Visibility
Position changes which facts a model reaches for when it builds an answer.
When you write a long prompt, the order of your instructions is not cosmetic. It influences instruction following, answer selection, and in retrieval-grounded systems, which passages get used. A constraint placed at the end often survives better than the same constraint dropped into the middle of a wall of text.
This carries straight into content strategy. AI search systems read your pages and decide which parts to pull into an answer. The opening summary of a page and a clean closing recap are structurally easier for a model to reuse than dense supporting detail sitting halfway down. If you want a claim to be quotable, it should not be buried.
The pattern shows up across long-form content, retrieval-augmented generation workflows, and AI-generated summaries. In each case, the model is sampling from a sequence, and the edges of that sequence get a structural advantage.
One honest caveat keeps this useful. Placement influences output. It does not guarantee output. A well-placed instruction can still be ignored, and a well-placed claim can still go uncited. Treat position as a lever that shifts probabilities, not a switch that forces a result.
| Use case | What position affects | Practical consequence |
|---|---|---|
| Multi-instruction prompt | Which constraints the model follows | End and start instructions survive; middle ones slip |
| Long content page | Which sections get pulled into AI answers | Intro summaries and closing recaps get reused more |
| RAG retrieval set | Which passages the model actually reads | Mid-context documents can be underused even when relevant |
If you want the mechanics behind how systems choose what to cite, our guide on how AI crawlers actually pick sources pairs well with this section.
How It Works Inside LLM Context Windows
The effect comes from how a model processes a sequence, not from any single setting you can toggle.
Here are the mechanisms that drive it, in plain language.
1. Attention Distribution
The model assigns more salience to some tokens than others, and position influences that salience depending on the task.
2. Positional Encoding
Models tag each token with a position signal, so order is part of the information the model reads, not just the words themselves.
3. Instruction Placement
Where you put a directive changes whether the model treats it as top-priority guidance or background noise.
4. Training Data Ordering
Patterns in how examples were ordered during training and fine-tuning can shape positional tendencies in the finished model.
5. Context Truncation and Retrieval Limits
When input exceeds the window or a retriever caps how much it passes through, middle content is the first to get squeezed or dropped.
Task type tips the balance. Multiple-choice and classification work tends to lean primacy-heavy, with the model favoring earlier options. Summarization and some open generation tasks tend to lean recency-heavy, leaning on what came last. The same model can show different biases depending on what you ask it to do.
A real-world pattern makes this concrete. When a single task carries 8 to 12 constraints, the ones near the end of the prompt survive more reliably than the ones embedded in the middle. If three rules truly cannot be missed, you do not stack all three in the center and hope.
The Four Main Forms to Know
The broad concept splits into four forms you will actually meet in practice.
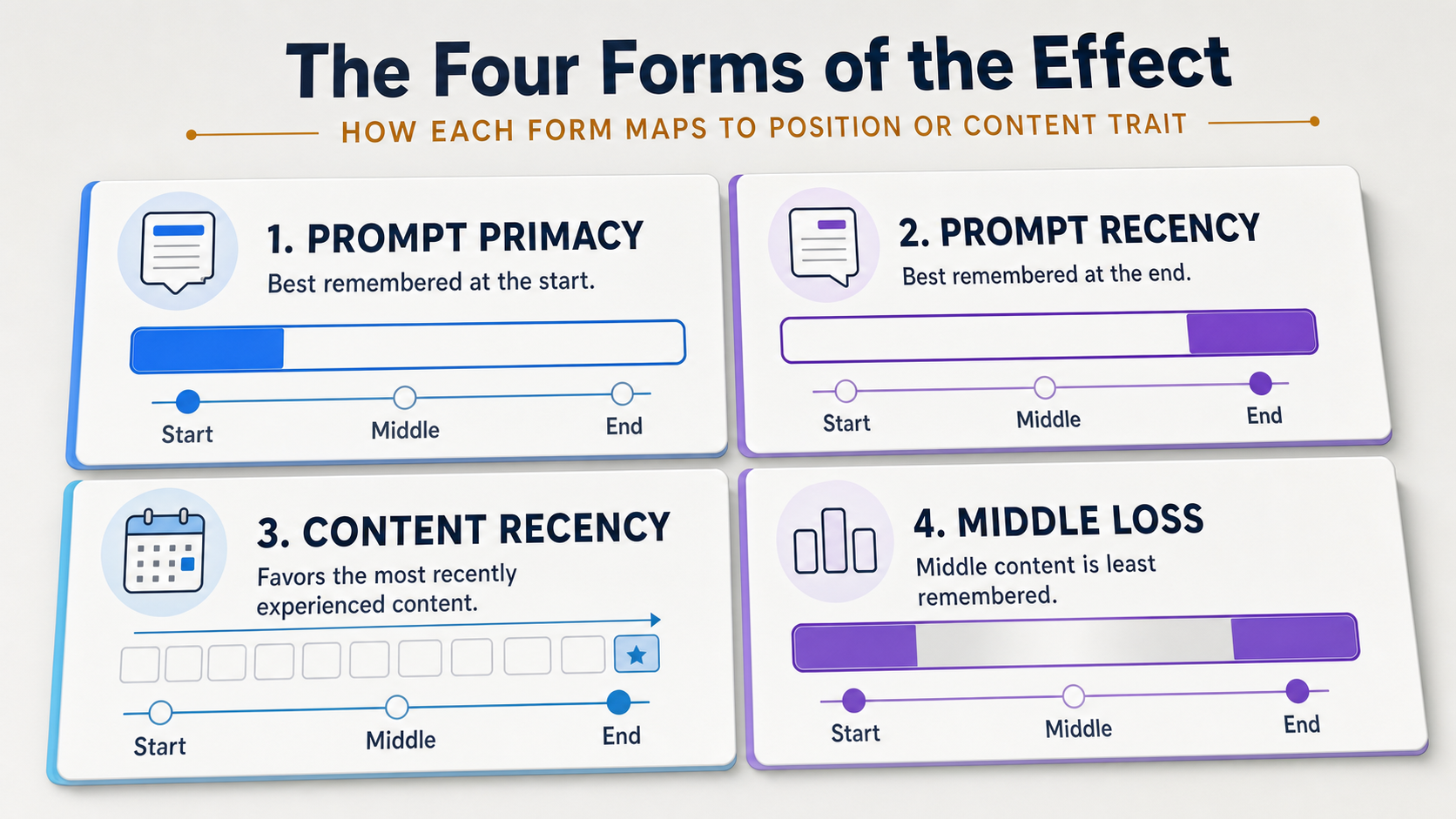
They are related, but they are not identical, and different systems show different combinations of them.
| Form | Where it shows up | What it means in practice |
|---|---|---|
| Prompt primacy | Early instructions and facts in a prompt | Opening directives and first examples get overweighted |
| Prompt recency | The latest instruction or example you give | The final instruction often wins when rules conflict |
| Content recency in AI citations | Fresher or recently updated pages | Some AI systems lean toward newer content when surfacing sources |
| Long-context middle loss | Information placed mid-window in long inputs | Relevant detail in the middle is easier for the model to overlook |
Prompt primacy and prompt recency are the two ends of the same curve, and you control both by deciding what to place first and last. Content recency is a different animal: it is about content age rather than position within a single input, and it interacts with authority and topic, not just freshness. Middle loss is the failure mode that connects them, because it explains why everything that is not at an edge becomes vulnerable.
Teams running prompt audits and content audits often assume freshness is the only variable that moves citations. In practice, placement and structure shape what gets reused at least as much as publish date does.
What Research Shows Across Tasks and Models
The research points to a consistent direction without promising a fixed magnitude.
Studies on serial position effects in language models report that primacy and recency biases appear across multiple model families, with primacy showing up especially often in classification and multiple-choice settings. One analysis of serial position effects found primacy in a clear majority of the instances it tested across open and closed models (Guo and Vosoughi, 2024, arxiv.org).
The “lost in the middle” finding is the cleanest demonstration of the weak zone. When researchers moved an answer-bearing passage to the middle of a long context, question-answering accuracy dropped toward the level of a model working with no context at all, while start and end placements held up far better (Liu et al., Stanford, 2023, cs.stanford.edu).
On the content side, applied analysis of AI bot behavior suggests freshness correlates with visibility, though the relationship varies by industry and is not deterministic (Seer Interactive, seerinteractive.com). Treat that as a correlation worth acting on, not a guarantee.
| Study type | Task | Observed bias | Takeaway |
|---|---|---|---|
| Serial position analysis | Classification, multiple-choice | Primacy dominant | Early options get favored across model families |
| Long-context QA | Multi-document retrieval | Middle loss | Mid-context answers fall toward no-context accuracy |
| Summarization studies | Generation | Recency more common | Models lean on later content when condensing |
| Applied content analysis | AI citation behavior | Recency in citations | Fresh content correlates with visibility, varies by vertical |
The practical lesson sits in the variation. Model family, architecture, instruction tuning, and task format all change the size and even the direction of the bias. A prompt structure that works beautifully on one model is not a reliable rule on the next. “It worked once” is not “it works.”
Common Mistakes and Misconceptions
Most errors here come from treating a tendency as a law.
Assuming All LLMs Behave the Same
Bias direction and strength differ across model families and versions, so test rather than transfer assumptions.
Assuming Recency Always Wins
Primacy dominates many classification and multiple-choice tasks, so the last item does not automatically take precedence.
Assuming Freshness Alone Drives Citations
Authority, relevance, and topic stability matter alongside content age, and freshness without substance rarely earns a citation.
Treating the Effect as a Fixed Law
It is a probabilistic tendency that shifts with task and model, not a constant you can rely on.
Believing Prompt Ordering Guarantees Accuracy
Good placement raises the odds that important content is used; it does not force correctness or control.
Forgetting That Placement Coexists With Other Failures
A well-positioned instruction can still meet hallucination, refusal, or weak reasoning.
The trap that catches teams most often is overfitting to a single prompt win and generalizing it across models. That is how a tactic that looked reliable in testing produces inconsistent results in production.
If you are building a repeatable process around this, our framework for diagnosing visibility and the AI overview optimization checklist give you a structured way to test placement assumptions instead of trusting one result.
Conclusion: Use Ordering as a Tendency, Not a Rule
The LLM content recency primacy effect is an ordering bias that shapes how models process, recall, and surface information.
Primacy and recency are useful mental models for where to place what matters, but they are not guarantees. Structure influences outcomes, and so do relevance, authority, and the specific behavior of the model you are working with. Think in probabilities, not absolutes.
If something must be noticed, do not bury it where the model is most likely to lose it. Put it where the weight already sits.
Frequently Asked Questions
Do LLMs have a primacy bias?
Yes, many do. Research on serial position effects reports primacy appearing across multiple model families, and it shows up especially often in classification and multiple-choice tasks where the model tends to favor earlier options. The strength varies by model and task, so treat it as a documented tendency rather than a guarantee.
Does recency bias always beat primacy bias in ChatGPT?
No. Recency tends to appear more in summarization and some generation tasks, while primacy often dominates multiple-choice and classification work. Which one shows up depends on the task format, the model version, and how the prompt is structured, so neither bias automatically wins.
Why do LLMs miss information in the middle of long prompts?
The middle of a long context gets less positional weight than the edges, a pattern researchers call “lost in the middle.” When an answer-bearing passage sits in the center of a long input, accuracy can fall toward the level of a model working with no relevant context at all, while start and end placements hold up much better.
Is the serial position effect the same as the recency primacy effect?
They describe the same underlying pattern. The serial position effect is the umbrella term for the start-and-end advantage, and primacy and recency are its two halves. In an LLM context, the cause is attention and positional weighting rather than human memory, even though the curve looks similar.
Does putting important text at the start improve AI citations?
It can raise the odds. Opening summaries and clear early statements are structurally easier for AI systems to surface and reuse than detail buried mid-page. It does not guarantee a citation, because authority, relevance, and content freshness also influence whether your content gets pulled into an answer.
For more research-backed context on how language models find and cite sources, explore our AI Visibility Resources. You can also see how this plays out in monitoring with our guide on tracking brand mentions in large language models.
