
Monitoring brand mentions in LLMs is the practice of systematically tracking how AI platforms like ChatGPT, Perplexity, Gemini, and Claude reference your brand when users ask questions relevant to your category. Unlike traditional brand monitoring, this discipline requires querying AI models directly — because LLM responses don’t appear in your Google Analytics, social listening dashboards, or rank trackers.
As of 2026, millions of B2B buyers use AI assistants to research vendors, compare solutions, and shortlist products before visiting a single website. If you don’t know what these models say about you, you’re missing the first impression that shapes your pipeline.
This article breaks down a practical system for monitoring brand mentions across major LLMs — covering what to track, which metrics matter, how to build a repeatable workflow, and how to turn monitoring data into content and positioning decisions that strengthen your AI visibility over time.
What You’ll Learn
- Why traditional brand monitoring tools miss LLM mentions entirely — and what to use instead
- The specific metrics that separate useful LLM monitoring from vanity tracking
- How to build a prompt library that mirrors real buyer behavior across AI platforms
- A step-by-step workflow for baselining, tracking, and acting on LLM mention data
- How to connect monitoring insights to content strategy and competitive positioning
- What’s changed in LLM monitoring since 2024–2025 and where the discipline is heading
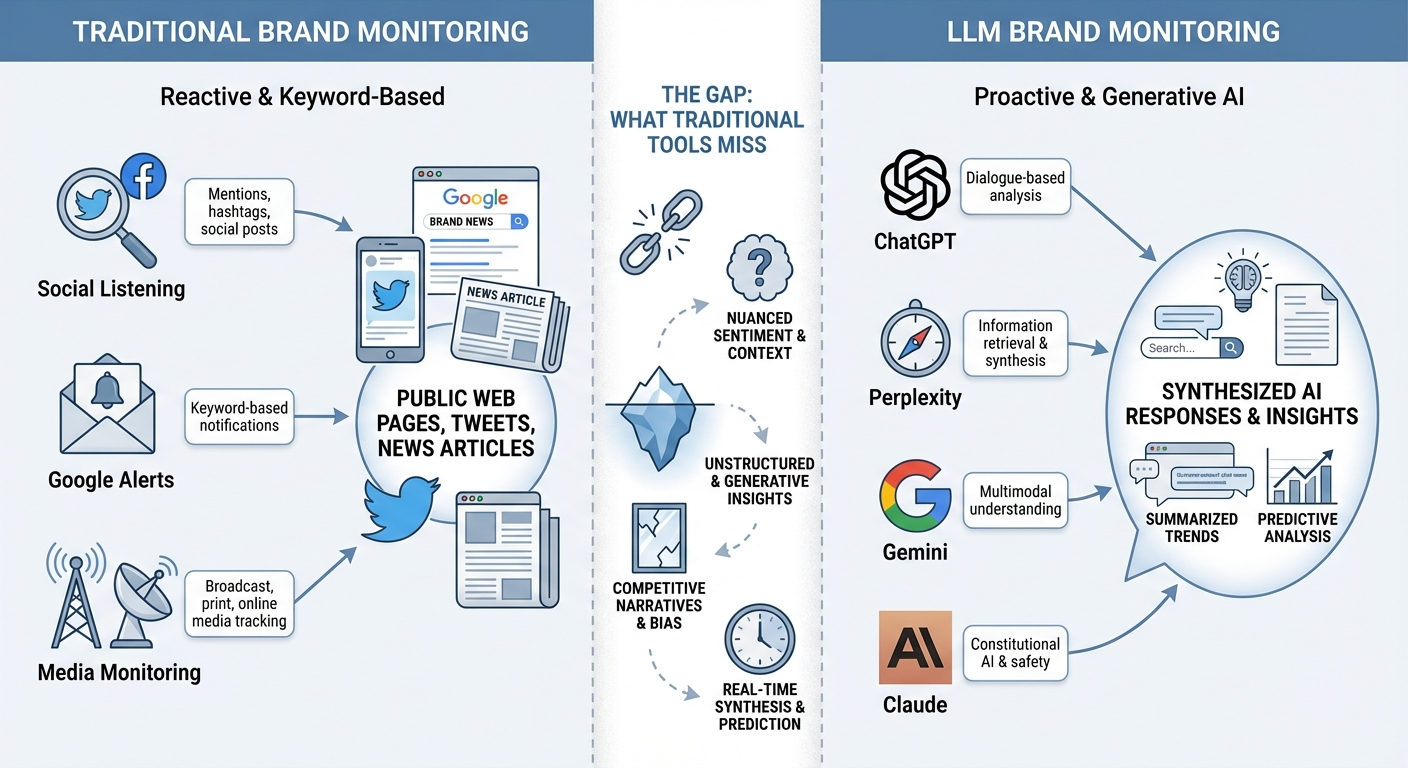
Why Traditional Brand Monitoring Doesn’t Cover LLMs
Most marketing teams already monitor brand mentions through social listening tools, media monitoring platforms, and Google Alerts. These tools scan public web pages, social feeds, news articles, and forums. They work well for those surfaces.
LLMs operate differently. When a user asks ChatGPT or Perplexity for a recommendation, the model synthesizes an answer from its training data and — in retrieval-augmented cases — from live web content. The response doesn’t link back to your site the way a blog post or tweet does. It constructs a narrative, and your brand either appears in that narrative or it doesn’t.
This creates three blind spots for teams relying on traditional monitoring:
- No crawlable output: AI-generated responses aren’t indexed web pages. Your social listening tool can’t find them.
- No referral trail: When an LLM mentions your brand, there’s no click, no referral URL, and no impression logged in Google Search Console.
- Dynamic and probabilistic responses: The same prompt can produce different answers depending on timing, model version, and context. A single check tells you very little.
This is why monitoring brand mentions in LLMs requires a dedicated approach — one that queries AI models directly with prompts that reflect how your buyers actually search for solutions.
What Has Changed Since 2024–2025
LLM monitoring was a niche concern in early 2024. By late 2025, it became a board-level topic for B2B companies competing in AI-influenced categories. Several shifts drove this acceleration:
- Retrieval-augmented generation (RAG) became standard. ChatGPT, Perplexity, and Gemini now pull live web content into responses, meaning your recent publications can influence what AI says about you within days — not just at the next training cycle.
- Google AI Overviews expanded globally. According to a 2025 Gartner forecast, traditional search engine volume is expected to decline 25% by 2027 as AI-powered answers replace link-based results. This means fewer clicks to your site from organic search and more brand exposure happening inside AI-generated summaries.
- AI responses became volatile. Research from Authoritas in 2025 found that significant portions of AI Overview rankings change within an 8-week window. A single audit no longer captures your actual visibility.
- Dedicated monitoring tools matured. Platforms like Semrush Enterprise AIO, Profound, and Peec AI now offer daily tracking, sentiment analysis, and competitive benchmarking specifically for LLM responses.
The practical implication: if your last AI visibility check was more than 60 days ago, your data is likely outdated. Monitoring needs to be continuous, not episodic.
Which Metrics Actually Matter for LLM Monitoring
Counting raw mentions tells you almost nothing. A brand mentioned once in a dismissive context is worse off than a brand mentioned zero times. The metrics below separate actionable monitoring from data noise.
Mention Frequency Across Models
Mention frequency measures how often your brand appears in AI-generated responses across different LLMs and query types. Track this separately for each platform — ChatGPT, Perplexity, Gemini, Claude — because visibility varies significantly between models.
A brand might appear in 70% of relevant Perplexity responses but only 30% of ChatGPT responses for the same category queries. That gap tells you where to focus your optimization efforts.
Share of Voice in AI Responses
Share of voice compares your mention frequency to competitors’ within a defined set of prompts. If you track 50 category-relevant queries and your brand appears in 15 while a competitor appears in 35, your share of voice is roughly 30% versus their 70%.
This metric is especially useful for B2B SaaS brands competing in defined categories where buyers ask LLMs direct comparison questions.
Mention Context and Positioning
Where your brand appears within the response matters as much as whether it appears. Track these positioning signals:
- Primary recommendation: Your brand is the first or featured suggestion.
- List inclusion: Your brand appears in a list of options, but not as the top choice.
- Comparative mention: Your brand is referenced in a comparison, either favorably or unfavorably.
- Passing reference: Your brand is mentioned as context or background, not as a recommendation.
A brand that consistently appears as a primary recommendation in decision-stage queries holds a much stronger position than one that appears only in passing references during educational queries.
Accuracy of Brand Descriptions
LLMs sometimes describe brands using outdated information, incorrect feature lists, wrong pricing tiers, or inaccurate positioning. Accuracy monitoring flags these misrepresentations before they influence buyer perception.
Check whether AI responses reflect your current product capabilities, target audience, and competitive differentiation. If a model describes your enterprise platform as a “startup tool” or cites features you deprecated two years ago, that’s an accuracy gap worth addressing.
Sentiment and Tone
Sentiment analysis evaluates whether LLM responses present your brand positively, neutrally, or negatively. Track sentiment trends over time — a gradual shift from positive to neutral might indicate that competitor content is reshaping how models perceive your category position.
Automated sentiment scoring provides a useful baseline, but manual review of high-priority prompts catches nuances that automated tools miss, such as damning-with-faint-praise language or outdated criticisms presented as current facts.
Citation Sources
When LLMs cite sources — as Perplexity and Google AI Overviews consistently do — track which URLs are referenced alongside your brand mention. This reveals:
- Which of your pages AI models consider authoritative enough to cite
- Which third-party sources (review sites, news outlets, industry publications) influence your AI narrative
- Content gaps where competitors’ sources are cited but yours are not
Citation source tracking connects your LLM monitoring directly to your content strategy. If a specific competitor’s comparison page is cited every time your brand comes up, you know exactly what content to create or improve.
How to Build a Prompt Library That Mirrors Buyer Behavior
The quality of your monitoring depends entirely on the prompts you test. Generic prompts produce generic insights. Prompts that mirror how real buyers ask questions reveal the visibility gaps that actually affect your pipeline.
Start with Your Sales Team’s Most Common Questions
Your sales team hears buyer questions every day. Those questions are the closest proxy for what buyers type into AI assistants. Collect the 20–30 most frequent questions from sales calls, demo requests, and support tickets.
Examples for a B2B analytics platform:
- “What are the best analytics platforms for mid-market SaaS companies?”
- “How does [Your Brand] compare to [Competitor] for product analytics?”
- “What tools do growth teams use to measure feature adoption?”
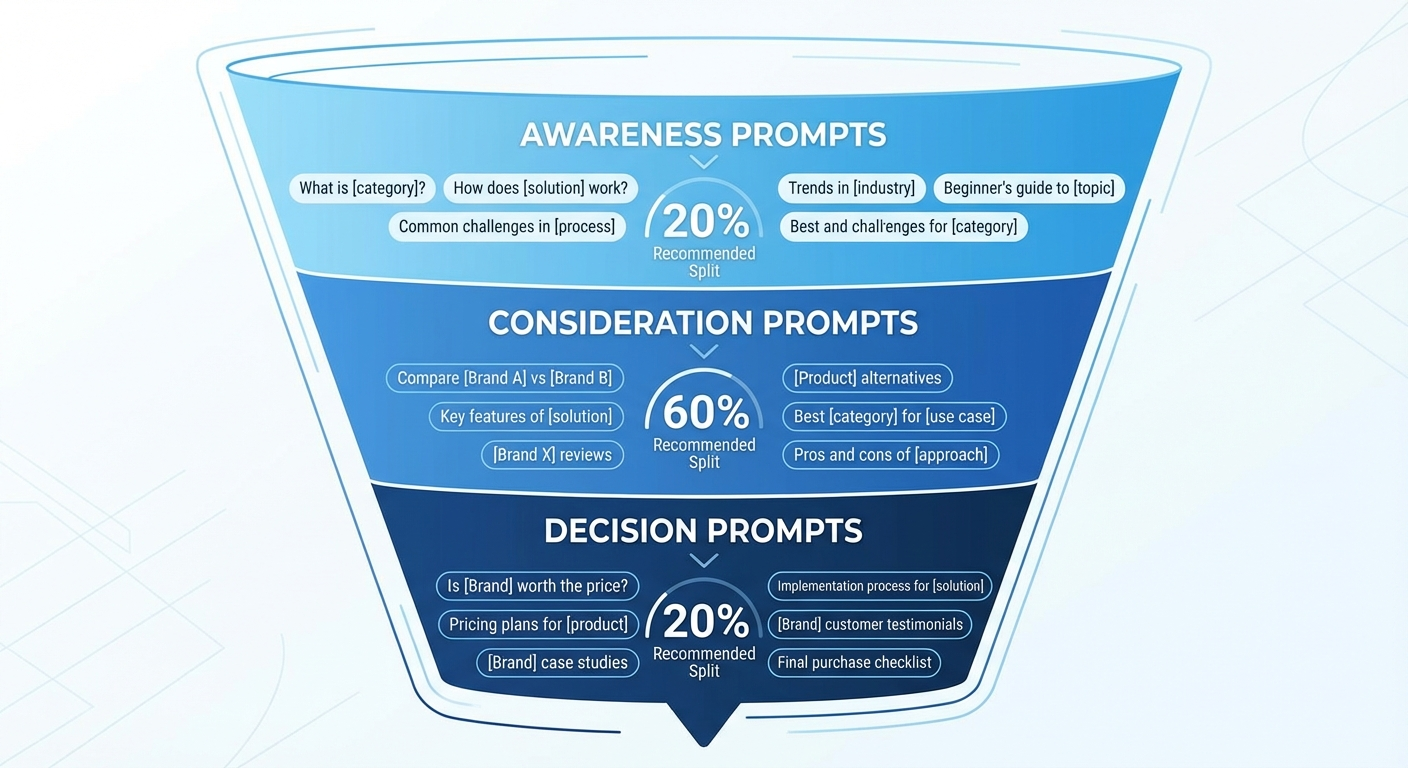
Organize Prompts by Buyer Journey Stage
Structure your prompt library into categories that map to the buyer’s decision process:
- Awareness prompts: Broad category questions — “What is product analytics?” or “How do SaaS companies track user behavior?”
- Consideration prompts: Comparison and evaluation questions — “Compare [Brand A] vs [Brand B]” or “Best product analytics tools for [specific use case]”
- Decision prompts: Purchase-intent questions — “Is [Your Brand] worth the price?” or “What do customers say about [Your Brand]?”
This structure helps you see where in the buyer journey your brand appears and where it drops off. Many brands show up in awareness-stage queries but disappear entirely at the decision stage — the exact moment when visibility matters most.
Include Non-Branded Category Queries
Monitoring only branded queries (“What is [Your Brand]?”) creates a false sense of security. Your brand might be perfectly described when someone asks about you directly, but completely absent when a buyer asks a neutral category question.
Non-branded queries are where competitive displacement happens. A buyer asking “best CRM for healthcare companies” doesn’t mention any brand — and the LLM’s answer shapes their shortlist before they visit your website.
Allocate at least 60% of your prompt library to non-branded queries. These reveal your actual competitive position in AI-generated brand recommendations.
A Step-by-Step Monitoring Workflow
A monitoring system that runs once and sits in a slide deck is worthless. The workflow below is designed to be repeatable, lightweight, and connected to decisions your team actually makes.
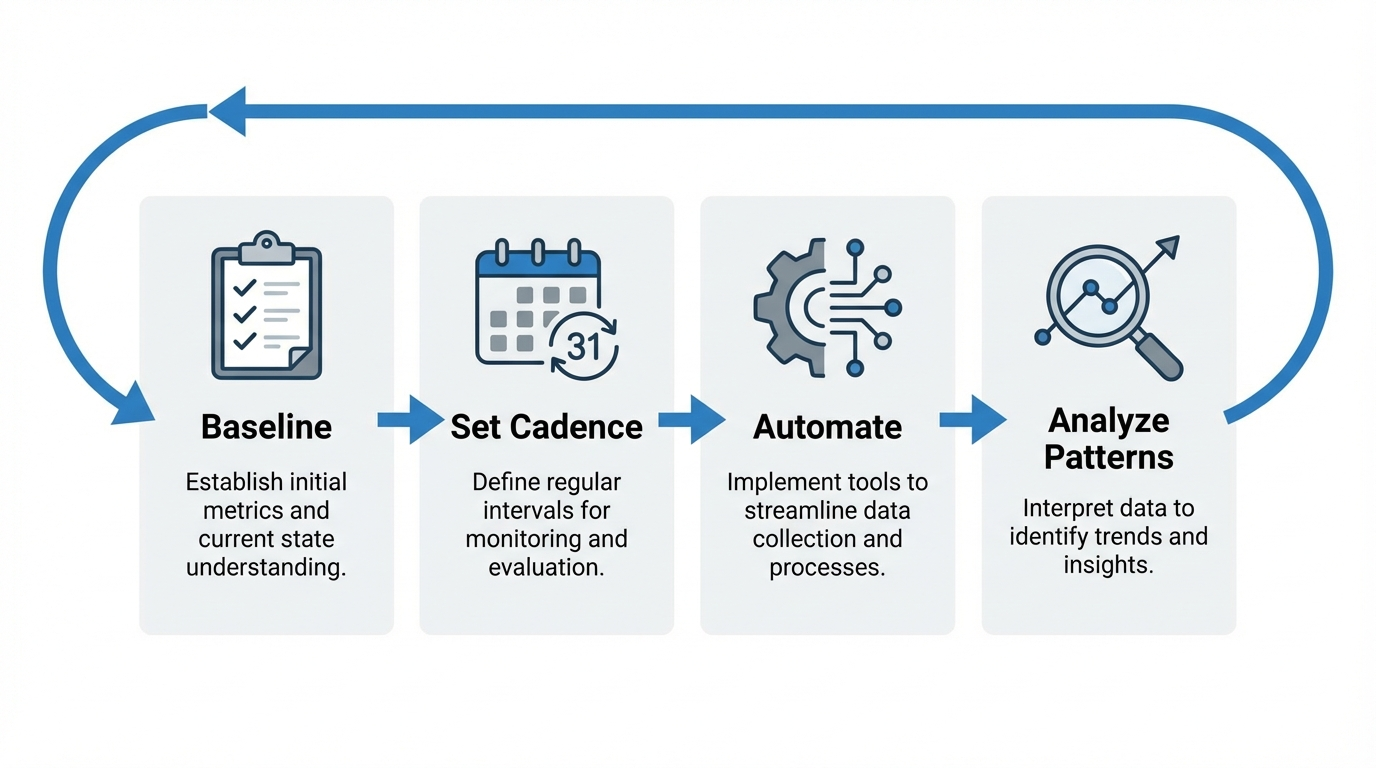
Step 1: Baseline Your Current Visibility
Before you can measure progress, you need a snapshot of where you stand today. Run your full prompt library across ChatGPT, Perplexity, Gemini, and Claude. For each prompt, document:
- Whether your brand appears in the response
- Your position within the response (primary recommendation, list mention, passing reference)
- Which competitors are mentioned alongside you or instead of you
- Whether the description of your brand is accurate
- Which sources the model cites (for platforms that provide citations)
This baseline becomes your reference point. Without it, you cannot measure whether your optimization efforts are working.
Tip: Run each high-priority prompt at least three times per model during your baseline. LLM responses are probabilistic — a single run might show your brand, but a second run of the same prompt might not. Three runs give you a more reliable picture.
Step 2: Set a Recurring Testing Cadence
Consistency matters more than frequency. Choose a cadence your team can sustain:
- High-priority prompts (decision-stage, high buyer intent): Test weekly
- Mid-priority prompts (consideration-stage comparisons): Test biweekly
- Lower-priority prompts (awareness-stage category questions): Test monthly
Assign ownership. Someone on your team — whether in content, growth, or product marketing — should be responsible for running tests, logging results, and flagging significant changes.
Step 3: Automate Where Possible
Manual testing is the right starting point. It gives you hands-on familiarity with how each model responds. But as your prompt library grows past 30–40 queries across four platforms, manual testing becomes unsustainable.
Dedicated AI rank trackers for brand mentions automate this process by querying models programmatically, logging responses, and surfacing changes. Look for tools that support:
- Multi-model coverage (at minimum ChatGPT, Perplexity, Gemini)
- Daily or weekly refresh rates
- Historical trend tracking
- Competitive benchmarking
- Alert notifications for significant visibility changes
Step 4: Analyze Patterns, Not Individual Responses
A single AI response is a data point. A pattern across 50 responses is an insight. When reviewing your monitoring data, look for:
- Consistent gaps: Prompts where competitors appear and you don’t, across multiple models and test dates
- Accuracy drift: Descriptions that become less accurate over time, often because your product has evolved but your indexed content hasn’t
- Platform-specific patterns: Visibility that’s strong on Perplexity but weak on ChatGPT, or vice versa — this often reflects differences in which sources each model prioritizes
- Competitive displacement: A competitor that didn’t appear three months ago but now consistently outranks you in AI responses
Step 5: Connect Monitoring to Action
Monitoring data is only valuable when it drives decisions. Build a clear action protocol for what you find:
- If you discover a consistent gap: Create or improve content that directly addresses the query where you’re missing. Structure it with clear entity definitions, specific claims, and authoritative sourcing — the patterns LLMs favor when selecting content to reference.
- If you find inaccurate descriptions: Update your product pages, FAQ content, and “About” page with clear, current information. Publish authoritative explainers that correct the record. Models that use RAG will eventually reflect these updates.
- If competitors are displacing you: Analyze what content they have that you don’t. Often, the displacement comes from a specific comparison page, a detailed use-case guide, or third-party coverage on publications that models cite frequently.
- If sentiment is declining: Trace it back to the sources models are referencing. Negative sentiment often originates from outdated reviews, unresolved complaints on public forums, or competitor content that positions you unfavorably.
Every monthly monitoring cycle should produce 3–5 specific content or positioning actions. If it doesn’t, your prompt library may need refinement.
Which AI Platforms to Monitor and Why
Not every LLM matters equally for your brand. Your monitoring resources should match where your buyers actually go for AI-assisted research.
ChatGPT
ChatGPT has the largest general user base among AI assistants as of 2026. It’s the default for broad buyer research, product discovery, and general category questions. Monitor ChatGPT if your buyers are likely to ask open-ended questions like “What are the best options for [category]?”
Perplexity
Perplexity functions as a research-oriented answer engine with strong citation behavior. It explicitly links to sources, making citation tracking in Perplexity especially actionable. Monitor Perplexity if your audience includes analysts, researchers, or buyers who conduct deep evaluations before purchasing.
Google AI Overviews
Google AI Overviews appear directly in search results for a growing percentage of queries. Because they integrate with traditional search, they influence buyers who haven’t yet adopted standalone AI assistants. Monitor AI Overviews if organic search is a significant channel for your brand.
Gemini and Claude
Gemini powers Google’s AI ecosystem and reaches users through Google Workspace integrations. Claude attracts technical and enterprise users who prefer Anthropic’s approach to safety and long-context reasoning. Monitor these platforms based on your audience’s technical profile and platform preferences.
Pro Insight: Start with two platforms — typically ChatGPT and one other that matches your buyer profile. Expand coverage as your monitoring process matures. Trying to monitor five platforms from day one without automation usually leads to inconsistent data and team burnout.
Common Monitoring Mistakes That Waste Time
Teams new to LLM monitoring often fall into patterns that produce impressive-looking data with little strategic value. Avoid these:
Checking Only Branded Queries
As covered earlier, branded queries (“Tell me about [Your Brand]”) test whether the model knows you exist — not whether it recommends you. The prompts that influence pipeline are non-branded category queries where a buyer hasn’t yet formed a preference.
Running a One-Time Audit and Stopping
AI responses shift as models update, as new content enters the web, and as competitors publish new material. A one-time audit captures a single moment. Trends require continuous measurement. According to Authoritas’s 2025 research, AI citations can fluctuate significantly within an 8-week period. Your monitoring cadence should account for this volatility.
Tracking Mentions Without Evaluating Accuracy
A mention that misrepresents your pricing, positioning, or capabilities can do more harm than no mention at all. Every monitoring cycle should include an accuracy check on high-priority prompts. If a model consistently describes you with outdated information, that’s a higher priority fix than chasing new mentions.
Ignoring Citation Sources
When Perplexity or Google AI Overviews cite a source alongside your brand mention, that source is shaping your AI narrative. If the cited page is a three-year-old review or a competitor’s comparison post, you now know exactly what content to create or improve. Ignoring citation data means ignoring the root cause of how AI perceives your brand.
How Monitoring Feeds Back into Content Strategy
The strongest monitoring programs don’t just report on visibility — they drive the content decisions that improve it. Here’s how to close the loop between monitoring insights and content execution.
Use Gap Queries to Prioritize Content Creation
Your monitoring data will reveal a list of prompts where competitors appear and you don’t. Rank these gaps by buyer intent and business value. A gap in “best [category] for enterprise teams” matters more than a gap in “what is [category] history.”
For each high-priority gap, create content that directly and comprehensively addresses the query. Structure it with clear headings, specific claims, and the kind of authoritative depth that AI models tend to reference.
Strengthen Pages That AI Already Cites
If your monitoring shows that AI models consistently cite a specific page from your site, that page is working. Strengthen it: update it with current data, add more specific detail, and ensure it accurately reflects your latest positioning. Pages that already earn AI citations are your highest-leverage assets for maintaining and expanding visibility.
Address Third-Party Sources That Shape Your Narrative
When models cite third-party sources alongside your brand — review sites, industry publications, analyst reports — those sources are influencing your AI narrative. If the cited content is favorable and accurate, consider amplifying it. If it’s outdated or negative, prioritize publishing content that offers a more current and authoritative alternative.
Agencies like BrandMentions approach this systematically by placing contextual brand mentions across 140+ high-authority publications that AI models actively learn from. This builds the kind of consistent, editorial-quality entity signals that influence how models describe and recommend a brand over time.
Building an Internal Reporting Structure
Monitoring data that lives in one person’s spreadsheet doesn’t drive organizational action. Build a reporting cadence that matches how your team makes decisions.
Weekly Reports for Execution Teams
Content, SEO, and product marketing teams need weekly visibility into prompt-level changes. Keep these reports focused: which prompts showed visibility gains or losses, which competitors gained ground, and which content actions are queued for the coming week.
Monthly Reports for Leadership
Marketing leadership and executives care about trends, not individual prompts. Monthly reports should focus on share of voice changes, sentiment trends, competitive positioning shifts, and the connection between monitoring findings and content investments.
Visualize trends over time. A chart showing your share of voice rising from 22% to 38% across 50 tracked prompts over three months tells a clearer story than a table of raw mention counts.
Escalation Paths for Reputation Risks
Not every finding can wait for the weekly report. Define clear criteria for immediate escalation:
- Factual errors about your product that could influence purchase decisions
- Sudden disappearance from high-value prompts where you previously appeared
- Negative sentiment spikes tied to specific events or source content
Assign escalation owners so urgent issues reach the right people within hours, not days.
What’s Ahead for LLM Monitoring in 2026 and Beyond
LLM monitoring is maturing rapidly, but the discipline is still early. Several trends are shaping where it’s headed:
- Agentic AI and autonomous research: AI agents that independently research, compare, and recommend products on behalf of users are moving from prototype to production. Monitoring will need to extend beyond chat interfaces to agent-driven workflows.
- Deeper integration with traditional analytics: As of 2026, most monitoring tools operate as standalone dashboards. Expect tighter integration with Google Analytics, CRM platforms, and marketing automation tools so teams can correlate AI visibility with pipeline and revenue metrics.
- Real-time monitoring at scale: Current tools typically offer daily or weekly refresh rates. As API access to LLMs becomes more reliable and cost-effective, real-time monitoring will become standard for enterprise brands.
- Cross-model entity consistency tracking: Tools will increasingly help brands ensure that their entity — name, description, positioning, and factual attributes — is represented consistently across all major models, not just present in some and absent or inaccurate in others.
The organizations building monitoring habits now will have years of trend data, refined prompt libraries, and established workflows when these capabilities mature. That head start compounds.
Frequently Asked Questions
How is monitoring brand mentions in LLMs different from social listening?
Social listening scans public web pages, social media posts, and forums for brand name mentions. LLM monitoring queries AI models directly with prompts that mirror buyer questions and analyzes the generated responses. The two surfaces are fundamentally different — social listening tracks what humans publish, while LLM monitoring tracks what AI models synthesize and recommend to users.
How often should I monitor my brand mentions across AI platforms?
High-priority decision-stage prompts deserve weekly monitoring. Consideration-stage queries can be checked biweekly. Lower-priority awareness queries work on a monthly cadence. The key is consistency — sporadic testing won’t reveal trends. If you’re just starting, begin with monthly monitoring of 15–20 prompts and increase frequency as your process matures.
Can I influence what LLMs say about my brand?
You can’t edit LLM responses directly. However, you can influence future responses by publishing clear, authoritative, well-structured content on your site and earning editorial brand mentions on high-authority publications. Models that use retrieval-augmented generation incorporate recent web content into their answers, so strategic content updates can shift how AI describes your brand over weeks to months.
Do I need a paid tool to start monitoring LLM mentions?
No. You can start manually by running 15–20 prompts across two AI platforms and logging the results in a spreadsheet. This manual approach works for establishing a baseline and understanding the landscape. As your prompt library grows past 30–40 queries, dedicated tools become necessary for consistent, scalable tracking.
Which LLM platform matters most for B2B brands?
ChatGPT has the broadest user base, making it essential for most brands. Perplexity is increasingly important for B2B because its citation-heavy format and research-oriented user base closely match how B2B buyers evaluate solutions. Start with these two, then expand to Gemini and Claude based on your audience’s platform preferences.
What should I do if an LLM describes my brand inaccurately?
First, document the inaccuracy and identify the likely source — check which URLs the model cites (on platforms like Perplexity) or search for outdated content about your brand that may be in the model’s training data. Then update your authoritative pages with clear, current information. Publish new content that directly addresses the inaccuracy with specific, factual claims. Monitor the relevant prompts weekly to track whether the correction takes effect.
Start Monitoring This Week
You don’t need a perfect system to start. You need 15 prompts, two AI platforms, and 30 minutes.
Write down the 15 questions your buyers most commonly ask when evaluating solutions in your category. Run them in ChatGPT and Perplexity. Document whether your brand appears, how it’s described, and who else shows up. That exercise alone will reveal gaps and opportunities you didn’t know existed.
From there, build the cadence, expand the prompt library, and layer in automation as the data proves its value. The brands that monitor consistently — not just once — are the ones that shape how AI describes their category.
If you want to see where your brand stands across major AI platforms right now, BrandMentions offers a free AI visibility audit that baselines your presence and identifies the highest-impact opportunities for improving how LLMs recommend you.