
Claude is now a discovery channel, and if your brand is missing from its answers, you lose visibility before a buyer ever reaches Google. A brand mention in Claude is any time Anthropic’s assistant names your company, product, or category position inside an answer, whether it recommends you, lists you as an alternative, or describes what you do. To track it, you need three things before you start: your exact brand names and variants, a fixed competitor set, and a repeatable set of prompts you run the same way every time. From there the workflow is simple to describe and harder to keep honest: set a baseline, score what you see, compare Claude against other engines, and turn the gaps into content and authority work. This guide walks each step in order.
What You Need Before You Track Brand Mentions in Claude
Lock your measurement scope before you run a single prompt. The biggest tracking errors in real audits come from inconsistent naming and fuzzy mention definitions, not from Claude being unpredictable. If you change what counts as a mention halfway through, your trendline is noise.
Start by writing down everything you want to track, in fixed form:
- Your exact brand name, abbreviations, product names, and common misspellings
- A fixed competitor set, chosen once, so share of voice is measured against the same brands every scan
- Your category and use-case scope, such as “best project management tool” or “Claude for legal research”
- What counts as a mention: exact brand name, product mention, recommendation, competitor comparison, or cited source
Manual testing is fine for a first baseline. You can prompt Claude by hand and log the results in a sheet. A dedicated AI monitoring tool scales better once you move past a handful of prompts and want repeatable, scheduled runs across engines.
![]()
Set this scope as a small worksheet: one column for brand variants, one for competitor names, one for category terms, and one for your mention rules. You will reuse it on every scan, so the work compounds instead of restarting each month. Tracking across more than one engine follows the same discipline, which is why a single scope sheet should feed your whole AI search tracking workflow, not just Claude.
Build a Claude Prompt Library and Run Your Baseline Scan
A prompt library is a fixed set of questions you ask Claude every scan, written to mirror how real buyers ask. The point is stability: when the prompts stay the same, a change in results means Claude changed its answer, not that you changed the question. Small wording shifts can move Claude from naming a brand to omitting it, so prompt stability matters more than prompt volume.
Step 1: Write Prompts by Intent Type
Group your prompts into four buyer-intent types so the set reflects how people actually shop, not just one phrasing.
- Best-of queries: “best X for Y”
- Comparison queries: “X vs Y”
- Alternative queries: “alternatives to X”
- Problem-solving queries: “how do I solve problem Z”
Twenty to thirty prompts is enough to start. Spread them across the four types rather than stacking ten variations of the same best-of question.
Step 2: Keep the Phrasing Fixed
Lock the exact wording of every prompt and save it. Resist the urge to “improve” a prompt mid-cycle, because that resets your trendline. If a prompt is genuinely broken, retire it and note the date, so you know which results predate the change.
Step 3: Record Four Things From Every Response
For each prompt, capture the same four data points so your scans stay comparable: whether the brand appears at all, where it appears in the answer, whether Claude recommends it or merely lists it, and whether the information is current and accurate. Those four columns become the backbone of your scorecard.
Step 4: Run the First Scan as a Baseline
Run the full prompt set once and save the raw outputs, not just a summary. This snapshot is your benchmark run. Every later scan compares against it, so paste the actual answer text into your sheet or dashboard rather than relying on memory or a screenshot.

Score Claude Results With a Simple Visibility Framework
Raw answers are not a metric. To trend Claude over time, convert each scan into a small set of scores you can compare month to month. Teams usually over-weight sentiment and under-weight accuracy, even though a wrong answer about your product does more damage than a neutral one.
Track five things, then decide whether to roll them into one number.
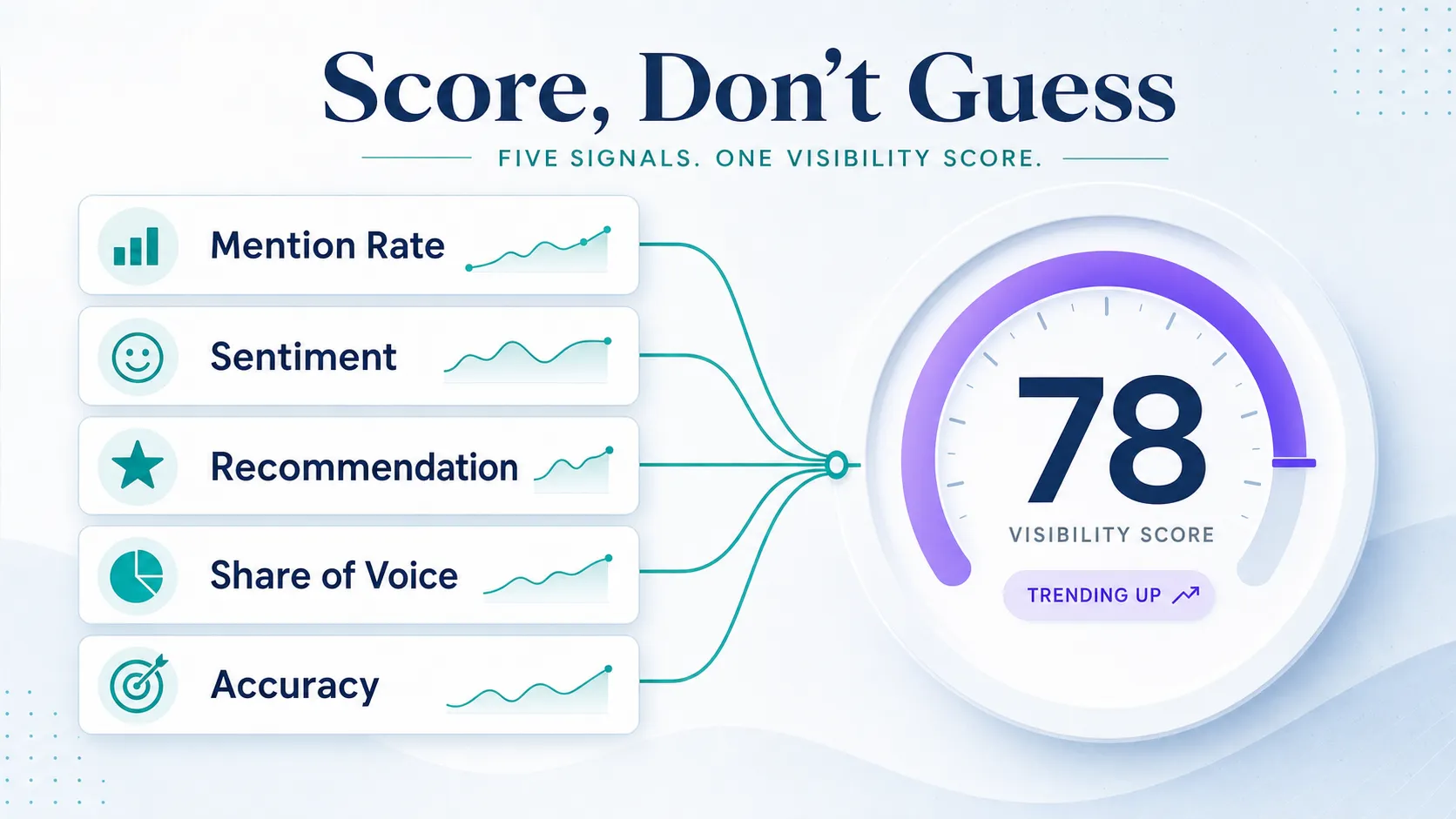
| Metric | What it measures | Action threshold |
|---|---|---|
| Mention rate | How often your brand appears across the full prompt set | Investigate any drop versus baseline |
| Sentiment | Positive, neutral, or negative framing of the mention | Flag any new negative framing |
| Recommendation quality | Whether Claude actively recommends you or just lists you | Prioritize prompts where rivals are recommended and you are not |
| Competitor share of voice | How often rivals appear versus your brand | Act when a competitor pulls clearly ahead |
| Factual accuracy | Whether the description is current and correct | Escalate any wrong claim immediately |
You can combine these into a single visibility score if leadership wants one number, but show the sub-scores alongside it so the score stays auditable. A weighting of roughly half on mention rate and the rest split across sentiment, recommendation quality, and accuracy works as a starting point. The number matters less than keeping the formula fixed, the same way you keep prompts fixed. If you want a wider view of which metrics actually predict pipeline, the difference between AI visibility and SEO metrics is worth reading before you set thresholds.
Compare Claude Against Competitors and Other AI Tools
Claude visibility only makes sense in context. A brand can dominate one AI system and nearly disappear in Claude when source authority or phrasing does not match Claude’s response pattern. Run the same prompt set in Claude and at least one or two other engines so you can tell whether the problem is Claude, the category, or your brand’s broader AI footprint.

Comparing across engines surfaces three outcomes, each pointing at a different fix.
| What you see | What it usually means |
|---|---|
| Brand missing in Claude, present elsewhere | Claude lacks the authoritative sources it trusts for your category |
| Brand underrepresented versus competitors | Rivals have more third-party corroboration Claude can lean on |
| Brand described differently than in other models | Your positioning is unclear or outdated in the sources Claude reads |
Compare recommendation patterns, not just raw mentions. Claude may name your brand without endorsing it, while a competitor gets the actual recommendation. When that happens, look at the sources: rivals often benefit from reviews, listicles, and category pages your brand lacks. The comparison tells you whether the real gap is entity authority, content positioning, or third-party corroboration. If your mentions look stable in one engine but vanish in another over time, that is often citation drift in action, not a one-off.
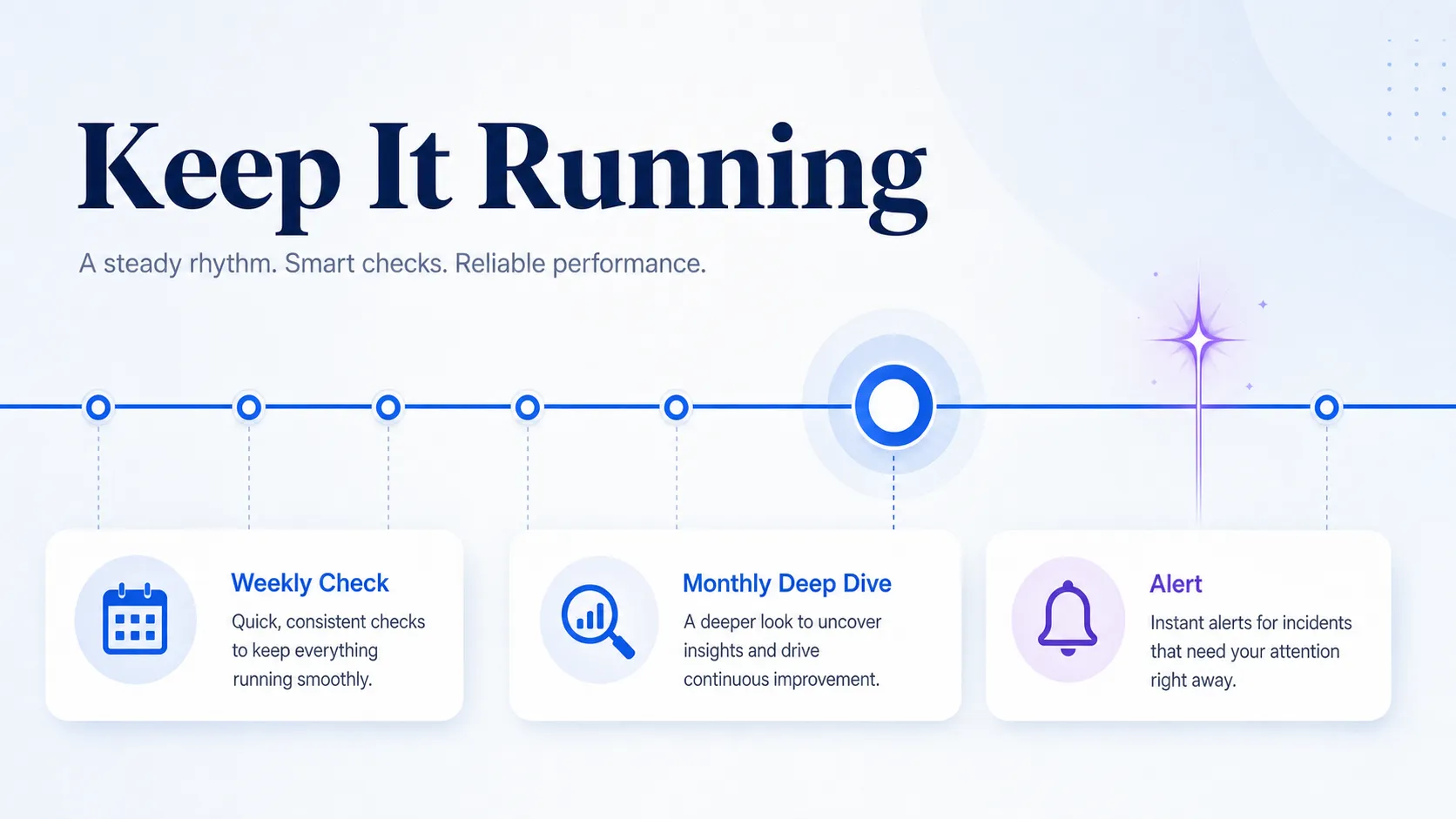
Set Your Monitoring Cadence, Alerts, and Review Workflow
Tracking only works if it keeps running after the first audit. Most teams fail here because nobody owns the cadence, not because the data is hard to collect. Build the schedule and the ownership before you celebrate your baseline.
Run Weekly Checks on the Core Set
Test your core prompt set weekly so meaningful shifts surface early. A weekly cadence catches a sudden mention-rate drop or a new negative framing while you can still react, rather than discovering it a month later.
Run a Monthly Deep Dive
Once a month, go deeper than the weekly count. Review sentiment trends, competitor movement, and accuracy issues across the full set, and check whether any new prompts should join the library or any broken ones should retire.
Set Alerts for Specific Events
Define the events that should trigger action: a sharp mention-rate drop, a clear competitor gain, or a factual error that could harm trust. Tie each alert to a response, so the signal leads to work rather than a notification nobody reads. A predictive alert setup can flag drops before they show up in your monthly review.
Assign a Clear Owner
One person owns the scan, the scorecard, and the escalation path. When results change, everyone should know who runs the next check and who decides what to do about it. Shared ownership usually means no ownership.
Revalidate After Major Claude Updates
Recheck the prompt library after any major Claude update or obvious prompt drift. Model changes can shift how Claude answers your exact prompts, so confirm the set still reflects real buyer questions before you trust the next trendline.
Turn Claude Findings Into Optimization Actions
Tracking earns its keep only when the gaps become work. The fastest gains usually come from clearer entity coverage and stronger third-party corroboration, not from publishing more generic blog posts. Map each tracked problem to a specific fix.
When Claude Misses Your Brand Entirely
Strengthen your entity authority first. Entity authority is the strength of your brand’s presence across the sources an engine trusts, including your own clearly structured category and product pages and consistent naming everywhere you appear. If Claude has no clean signal for what you are and who you serve, it cannot name you. Tighten the owned assets, then earn outside reinforcement.
When Competitors Appear More Often
Publish the content Claude is already answering with. Comparison pages, alternatives content, and clear FAQ blocks that address the same buyer questions give Claude something concrete to cite when a rival currently fills that gap. Match your content to the exact prompts where competitors win.
When Claude Gives Inaccurate or Outdated Information
Build a clear correction page and reinforce it with authoritative third-party references. A wrong product description or stale positioning is more damaging than a neutral mention, so treat accuracy fixes as the top priority. Keep a monitoring dashboard running so you catch the next inaccuracy before it spreads.
When You Lack Third-Party Corroboration
Earn more external mentions through reviews, listicles, expert quotes, and industry coverage that Claude can treat as supporting evidence. Claude leans on authoritative outside sources, so earned coverage often moves the needle more than another owned page. This is the slow, compounding work, and it is usually what separates a brand Claude recommends from one it merely mentions.
Avoid the Mistakes That Break Tracking
The common failures are predictable: changing prompts too often, relying on one-off screenshots, testing too few queries, and treating Claude like a normal search results page. Each one quietly corrupts your trendline. Success is not a perfect score; it is a stable baseline, a repeatable system, and a prioritized backlog of content and authority fixes. For the broader playbook beyond Claude alone, the work to increase brand mentions in AI search follows the same logic across every engine.
![]()
Frequently Asked Questions
How do I track brand mentions in Claude AI?
Lock a fixed set of brand names and competitors, build a stable prompt library of 20 to 30 buyer-intent questions, run them as a baseline scan, and record whether your brand appears, where, whether it is recommended, and whether the answer is accurate. Repeat the same prompts on a schedule and trend the results. Manual testing covers a first baseline; a dedicated AI monitoring tool scales the ongoing work.
Can I influence what Claude says about my brand?
Yes, indirectly. You cannot edit Claude’s answers, but you shape what it knows by strengthening entity authority, publishing clear category and comparison content, and earning third-party mentions Claude can treat as evidence. Imagine Claude is asked “best tool for X” and pulls from reviews and listicles. If your brand is well covered in those sources, it appears. If it is not, it does not.
What metrics should I track besides mention rate?
Track sentiment, recommendation quality, competitor share of voice, and factual accuracy alongside mention rate. Mention rate tells you whether you appear, but recommendation quality tells you whether Claude actually endorses you, and accuracy catches the wrong claims that quietly cost trust.
How often should I check Claude brand mentions?
Run weekly checks on your core prompt set and a deeper monthly review of sentiment, competitors, and accuracy. Add event-based alerts for sharp mention drops or factual errors so you react fast. Revalidate the prompt library after major Claude updates.
Is manual testing enough, or do I need an AI monitoring tool?
Manual testing is enough to set a baseline and learn how Claude treats your brand. Once you move past a handful of prompts and want scheduled, repeatable runs across multiple engines, a dedicated AI monitoring tool saves time and reduces human error.
Start With a Baseline, Then Keep It Running
Claude mention tracking is an ongoing system, not a one-time audit. The teams that win here are not the ones with the fanciest tool; they are the ones who fix their prompts, fix their definitions, and actually check every week. Start small: lock your scope, build 20 to 30 prompts, run one honest baseline, and score it. Then make someone own the weekly check. Want to see where your brand stands in Claude and the other engines right now? Get a free AI visibility audit and start from a real baseline.
