
Tracking brand mentions in large language models is the only way to know whether AI tools like ChatGPT, Gemini, Perplexity, and Claude recommend your brand — or ignore it entirely. As of 2026, millions of B2B buyers ask AI assistants for product recommendations, vendor comparisons, and category research before ever visiting a website. If you aren’t systematically monitoring what these models say about you, you’re missing a discovery channel that shapes purchase decisions upstream of your pipeline.
This article breaks down a practical system for tracking brand mentions across major LLMs — without relying on guesswork or one-off manual checks. You’ll learn which metrics actually matter, how to build repeatable monitoring workflows, and how to turn tracking data into content and positioning decisions that strengthen your AI visibility over time.
What You’ll Learn
- Why traditional SEO rank tracking doesn’t capture how LLMs reference your brand
- The specific metrics — frequency, sentiment, accuracy, competitive proximity — that define LLM visibility in 2026
- How to build a prompt library that mirrors real buyer queries across ChatGPT, Gemini, Perplexity, and Claude
- A step-by-step workflow for establishing baselines, automating checks, and catching visibility shifts early
- How to connect tracking insights to content strategy that improves your positioning in AI-generated answers
- What leading tools offer — and what gaps still exist in the LLM monitoring landscape
Why LLM Brand Tracking Requires a Different Approach Than SEO Monitoring
SEO rank trackers measure where your pages appear in a list of blue links. LLM tracking measures whether your brand appears inside the answer itself — and how it’s described when it does.
That distinction matters because LLMs don’t retrieve and rank web pages the way Google’s organic index does. They synthesize information from training data, retrieval-augmented sources, and real-time web results into a single conversational response. Your brand either becomes part of that synthesized narrative or it doesn’t.
A 2025 Semrush analysis of one million non-branded queries across five LLMs found that AI models include brand mentions in 26% to 39% of responses. That means roughly one in three AI answers names specific companies — even when the user never asked about a brand by name.
For B2B marketers, this has direct pipeline implications. If a VP of Engineering asks Perplexity “What are the best observability platforms for microservices?” and your competitor appears while you don’t, you’ve lost influence before a sales conversation even begins.
Key differences between SEO tracking and LLM tracking
| Dimension | SEO Rank Tracking | LLM Brand Tracking |
|---|---|---|
| What you measure | Page position in a list of links | Brand presence, context, and accuracy inside a generated answer |
| Ranking signals | Backlinks, domain authority, keyword relevance | Citation quality, entity authority, source diversity, content structure |
| Stability | Relatively stable week-to-week | Probabilistic — the same prompt can yield different answers on different days |
| Competitive context | 10 competitors on page one | Typically 2–5 brands named in a single synthesized response |
| User behavior | User clicks a link and visits your site | User may act on the AI’s recommendation without clicking any link |
The takeaway: if your monitoring stack only tracks SERP positions, you have a blind spot in the fastest-growing discovery channel for B2B buyers.
Which Metrics Define LLM Brand Visibility in 2026?
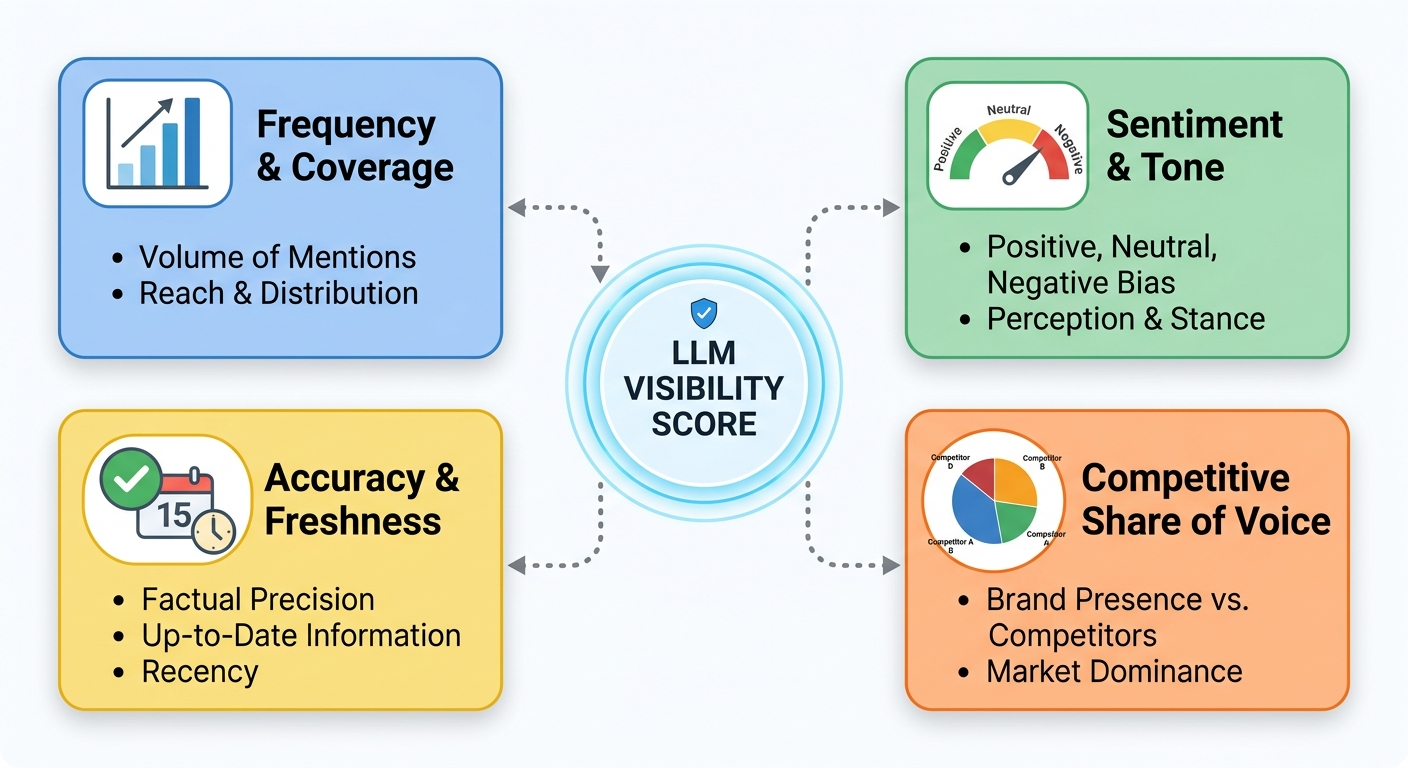
Counting how many times your name appears in AI responses is a start — but it’s not enough. The brands building durable AI visibility track four distinct metric categories.
1. Mention frequency and model coverage
Mention frequency measures how often your brand appears across a defined set of prompts. Model coverage reveals whether that visibility is concentrated in a single LLM or spread across ChatGPT, Gemini, Perplexity, Claude, and Copilot.
This matters because each model has different training data, retrieval preferences, and update cycles. A brand might appear in 40% of ChatGPT responses for a given category but be completely absent from Claude for the same prompts. Tracking coverage across models exposes blind spots that single-platform monitoring misses.
2. Sentiment and tone
Sentiment classifies whether your brand is described positively, neutrally, or negatively in AI responses. Beyond simple positive/negative scoring, look for tone signals: is the model recommending you with confidence (“widely regarded as a strong choice”) or hedging (“might be worth considering”)?
Hedging language often signals weak entity authority — the model isn’t confident enough in your brand’s association with the topic to recommend you outright. Tracking sentiment trends over time helps you identify whether content and PR efforts are shifting the narrative in your favor.
3. Accuracy and freshness
Accuracy measures whether LLMs describe your brand correctly. Do they reference current product capabilities, or outdated features you deprecated two years ago? Do they place you in the right category, or conflate you with a different type of solution?
According to research cited by Meltwater in early 2026, 35% of brands report that AI hallucinations or inaccuracies have harmed their reputation. Accuracy monitoring catches these issues before they compound across millions of AI conversations.
4. Competitive proximity and share of voice
Competitive proximity identifies which brands appear alongside yours — or instead of yours — in AI answers. Share of voice calculates your brand’s percentage of mentions relative to total brand mentions for a set of target queries.
Together, these metrics reveal how LLMs frame your market position. If the model consistently names three competitors before you, or groups you with a category you’ve moved away from, you have a positioning problem that content alone won’t fix without strategic AI brand mention building.
How to Build a Prompt Library That Mirrors Real Buyer Queries
The foundation of any LLM tracking system is the set of prompts you test. Poor prompts produce misleading data. Strong prompts mirror the exact questions your buyers type into AI assistants during research and evaluation.
Categorize prompts by buyer intent
Organize your prompt library into four categories:
- Category discovery: “What are the best [category] tools for [use case]?” — These broad queries reveal whether LLMs associate your brand with your market.
- Comparison and evaluation: “[Your brand] vs. [competitor] for [specific need]” — These show how models position you head-to-head.
- Problem-solving: “How do I [solve a problem your product addresses]?” — These uncover whether your brand appears in educational, solution-oriented contexts.
- Trust and reputation: “Is [your brand] reliable for [enterprise/regulated/high-stakes use case]?” — These reveal sentiment and confidence signals.
Start with 15–25 prompts spread across all four categories. Prioritize the queries your sales team hears most often from prospects.
Include non-branded queries — they matter most
A common mistake is testing only branded prompts like “What is [Your Brand]?” These tell you whether the model knows you exist, but they don’t reveal whether it recommends you to people who haven’t heard of you yet.
Non-branded, category-level prompts — “best project management software for remote teams” or “top compliance platforms for fintech startups” — are where real competitive visibility is won or lost. Aim for at least 60% of your prompt library to be non-branded.
Account for prompt phrasing variation
LLM responses can shift significantly based on how a question is worded. “What’s the best CRM?” may produce different results than “Recommend a CRM for a 50-person B2B sales team.” Test multiple phrasing variations for your highest-priority topics to avoid basing decisions on a single prompt’s output.
Some AI rank tracking platforms now offer automatic “fan-out” — generating prompt variations from a single seed query to capture this natural variability.
A Step-by-Step Workflow for Tracking Brand Mentions Across LLMs
With your metrics defined and prompt library built, here’s how to implement a repeatable tracking system that scales beyond manual spot-checking.
Step 1: Establish your baseline
Run every prompt in your library across at least three major LLMs — ChatGPT, Gemini, and Perplexity cover the broadest audience segments as of 2026. For each response, document:
- Whether your brand appears
- Where in the response it appears (top recommendation, mid-list, footnote, or absent)
- How it’s described — is the positioning accurate and current?
- Which competitors are named alongside or instead of you
- Whether the model cites or links to any of your pages
Record this in a shared spreadsheet or monitoring tool. This baseline is your reference point for every future measurement.
Step 2: Set a testing cadence
High-priority prompts — those tied to purchase intent or representing significant audience volume — deserve weekly or biweekly testing. Mid-priority prompts can be checked monthly. Low-priority terms might be reviewed quarterly.
Consistency matters more than frequency. A monthly cadence executed reliably produces better insights than sporadic daily checks that stop after two weeks.
Step 3: Automate where possible
Manual testing works for initial baselines and quick audits, but it doesn’t scale once your prompt library exceeds 30–40 queries across multiple models. Dedicated LLM monitoring tools programmatically run prompts, capture responses, and flag changes — eliminating hours of repetitive work each week.
If budget is limited, even a simple script that queries LLM APIs on a schedule and logs responses to a Google Sheet gets you 80% of the way there. The goal is removing human effort from data collection so your team can focus on analysis and action.
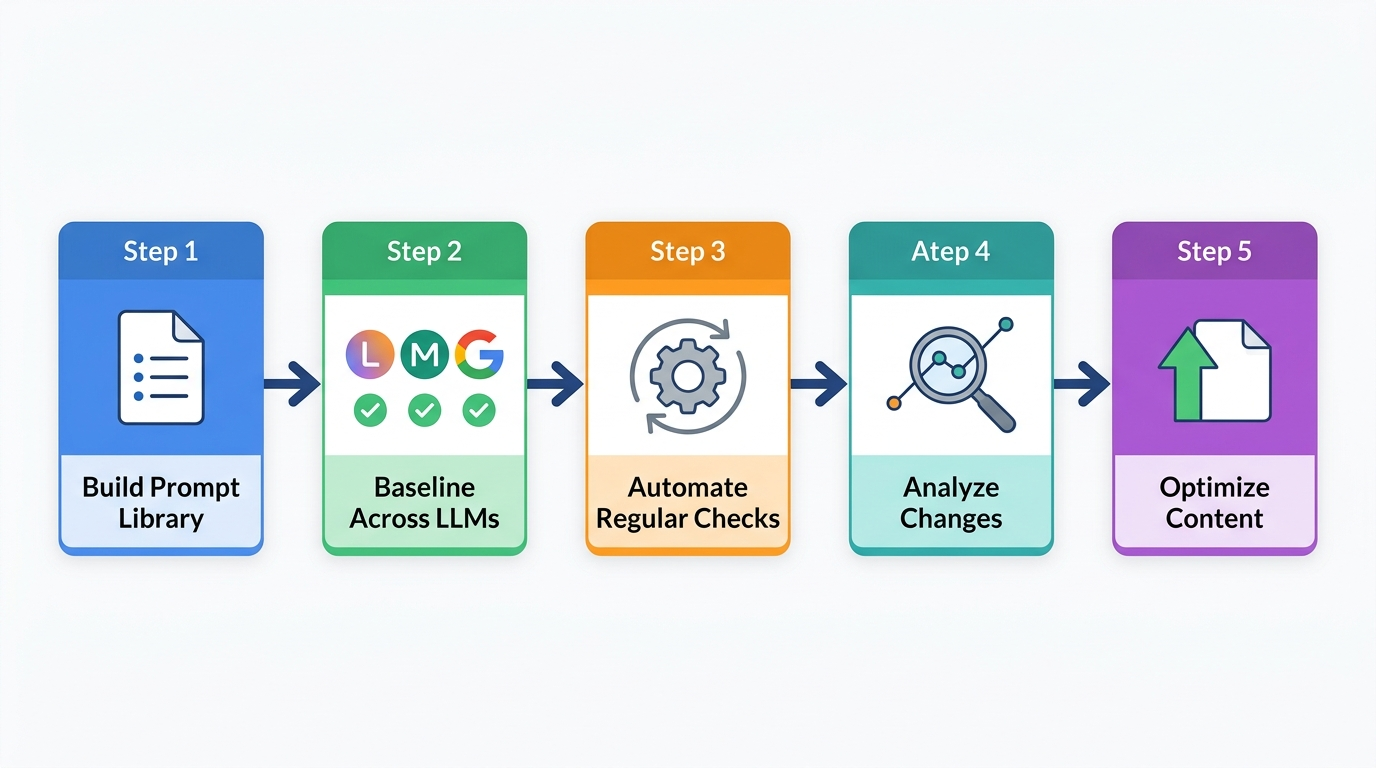
Step 4: Flag meaningful shifts — not noise
Because LLMs are probabilistic, some variability in responses is normal. The same prompt can produce slightly different answers on different days. Don’t overreact to minor fluctuations.
Focus your attention on:
- Disappearances: Your brand was consistently mentioned for a prompt and suddenly isn’t.
- New competitor entries: A brand you didn’t track starts appearing in your core category prompts.
- Sentiment shifts: Descriptions of your brand move from confident recommendations to hedging or negative associations.
- Accuracy degradation: The model starts citing outdated features, wrong pricing tiers, or discontinued products.
Set alert thresholds — for example, investigate if your share of voice drops more than 15% in a two-week window, or if a negative sentiment flag appears across two or more models simultaneously.
Step 5: Connect tracking data to content decisions
The highest-value output of LLM tracking isn’t a dashboard — it’s the content roadmap it informs.
When your monitoring reveals a gap (competitors appear for “best compliance automation tools” but you don’t), that gap becomes a content brief. When accuracy issues surface (the model describes your product using a two-year-old feature set), your product marketing team has a clear mandate to publish updated, model-friendly pages.
This feedback loop — monitor → identify gaps → create or update content → re-monitor — is what turns tracking from a reporting exercise into a strategic system for improving AI visibility.
Evaluating LLM Monitoring Tools: What to Look For
The market for LLM brand tracking tools has expanded significantly since 2024. Choosing the right platform depends on your budget, team size, and how deeply you need to analyze AI responses.
Core capabilities to prioritize
- Multi-model coverage: At minimum, the tool should track ChatGPT, Gemini, and Perplexity. Broader coverage including Claude and Copilot is increasingly important as model usage fragments across buyer segments.
- Custom prompt libraries: You need to test the specific queries your buyers use — not a generic industry template. Look for tools that let you define and manage your own prompts.
- Historical tracking: Snapshots are useful; trend lines are essential. The tool should store past responses so you can visualize visibility changes over weeks and months.
- Competitive benchmarking: Knowing your own visibility score means little without context. Tools that automatically track competitors in the same responses give you actionable share-of-voice data.
- Sentiment analysis: Automated classification of positive, neutral, or negative mentions saves manual review time and enables trend tracking at scale.
What most tools still get wrong
As of 2026, even the best LLM tracking platforms have limitations worth understanding:
- Response variability: Running a prompt once captures a single data point. Because LLMs are probabilistic, the same prompt can yield different brands on different runs. Tools using “multi-sampling” — running each prompt several times to establish reliable averages — produce more trustworthy data.
- Platform-specific quirks: ChatGPT, Perplexity, Gemini, and Claude each have different source preferences and citation behaviors. According to a Profound crawler study published in late 2024, AI bots exhibit fundamentally different crawling and citation patterns than traditional search crawlers. A tool that treats all models identically may miss these nuances.
- Attribution gaps: Connecting an AI mention to actual revenue remains difficult. Most tools can show visibility trends but struggle to tie mentions directly to pipeline or closed deals. Workarounds include tracking AI-referred traffic through UTM parameters and correlating visibility improvements with demand metrics over time.
No tool replaces strategic interpretation. The best monitoring setup combines automated data collection with human analysis — a team member who understands your market, competitive landscape, and content strategy reviews the data and decides what to act on.
Platform-by-Platform: How Each Major LLM Handles Brand Mentions Differently
Treating all LLMs as interchangeable leads to inaccurate tracking and misallocated effort. Each model has distinct behaviors that shape when and how your brand appears.
ChatGPT (OpenAI)
ChatGPT has the largest general-purpose user base as of 2026. Its responses draw from both training data and, when using search mode, real-time web retrieval. Analysis of 30 million citations by Profound found that ChatGPT’s source preferences lean heavily toward Wikipedia (47.9%), Reddit (11.3%), and major publications like Forbes (6.8%).
For brand tracking, this means your presence on Wikipedia, in Reddit discussions, and on major media outlets disproportionately influences whether ChatGPT mentions you. Monitoring your brand in ChatGPT specifically is a high-priority task for most B2B brands.
Perplexity
Perplexity functions as a research-oriented answer engine that emphasizes citations and source transparency. The same Profound citation analysis showed Perplexity draws heavily from Reddit (46.7%), YouTube (13.9%), and analyst sources like Gartner (7.0%).
Perplexity tends to mention more brands per average answer than other models, making it a platform where competitive proximity matters — you may appear, but so do several alternatives. Tracking your positioning within the list (first mentioned vs. last mentioned) provides useful signal.
Gemini (Google)
Gemini powers Google’s AI Overviews and standalone Gemini responses. Its citation patterns show the highest brand diversity among major models, with significant sourcing from Reddit (21.0%), YouTube (18.8%), and Quora (14.3%).
Because Gemini is integrated into Google Search, your visibility here directly affects how millions of users encounter your brand through Google AI Overviews — a surface that appeared on over 13% of search results pages as of early 2025, according to Semrush research.

Claude (Anthropic)
Claude attracts a technical and professional user segment. Its responses tend to be longer and more nuanced, with particular attention to safety and accuracy. Claude’s brand mention patterns are less well-documented publicly than ChatGPT or Perplexity, which makes direct testing even more important.
For B2B brands serving developers, data teams, or technical buyers, Claude visibility can influence decisions that never show up in traditional web analytics.
Practical implication for tracking
Test the same prompts across all four platforms. Your visibility profile will likely be uneven — strong on one model, weak on another. These platform-specific gaps inform where to focus content and citation-building efforts. A brand invisible on Perplexity but well-represented in ChatGPT needs a different strategy than one that’s absent everywhere.
Turning Tracking Insights Into Visibility Gains
Data without action is just overhead. The brands building measurable AI visibility treat tracking insights as the starting point for a content and positioning feedback loop.
Close gap prompts with authoritative content
When monitoring reveals prompts where competitors appear and you don’t, create content specifically designed to address that query. This means publishing comprehensive, well-structured resources that directly answer the question the prompt represents.
For example, if your brand doesn’t appear when users ask “What are the best [category] tools for mid-market teams?” — and three competitors do — you have a clear content brief. Create a resource that positions your brand as a strong answer to that exact question, with specificity about the mid-market use case.
Correct accuracy issues at the source
If LLMs describe your brand using outdated product names, wrong pricing, or deprecated features, the fix isn’t to “correct the AI.” It’s to update the authoritative content that AI models draw from: your website, your product pages, your help documentation, and the third-party sources that reference you.
Ensure your “About” page, product overview pages, and FAQs contain current, clearly structured information. LLMs parse structured, unambiguous content more effectively than marketing copy filled with qualifiers and brand voice flourishes.
Build citations on sources that LLMs trust
Each LLM has preferred sources it cites most frequently. If ChatGPT draws heavily from Wikipedia and Forbes, securing accurate representation on those platforms influences ChatGPT responses. If Perplexity leans on Reddit and Gartner, your presence in relevant Reddit discussions and analyst reports matters for Perplexity visibility.
This is where strategic brand mentions in generative AI become a deliberate discipline. Agencies like BrandMentions approach this by placing contextual brand mentions across 140+ high-authority publications that AI models actively reference during response generation — creating durable signals that influence how models associate brands with categories and use cases.
Measure impact and iterate
After publishing new content or securing mentions on high-authority sources, re-run the same prompts within 4–8 weeks to measure impact. Did your brand start appearing? Did your position improve? Did accuracy issues resolve?
This cycle — monitor, identify gaps, create content, build citations, re-monitor — compounds over time. In campaigns across 67+ B2B companies, the BrandMentions team observed that brands with consistent editorial mentions achieved AI recommendation rates significantly higher than those relying solely on traditional SEO.
Pro Insight: Don’t expect overnight results. LLM training data updates and retrieval index refreshes happen on different timelines for each model. A realistic measurement window for visibility improvement is 6–12 weeks after content publication or citation placement.
Common Mistakes That Undermine LLM Tracking Programs
Even teams that commit to monitoring often make avoidable errors that weaken their data quality and slow their progress.
Testing only branded queries
If your prompt library is dominated by “What is [Your Brand]?” and “[Your Brand] review,” you’ll get a misleading picture of your visibility. Most buying journeys start with category-level questions — and that’s where competitive displacement happens. Weight your library toward non-branded, intent-driven prompts.
Running a single baseline and never updating
LLMs update their training data, retrieval systems, and response-ranking logic regularly. A baseline captured in January is stale by March. Treat baselines as living data that needs regular refreshes.
Monitoring one LLM and assuming it represents all of them
ChatGPT is the most visible AI assistant, but it’s not the only one shaping buyer decisions. Your audience may prefer Perplexity for research, Claude for technical evaluation, or Gemini through Google search. Monitoring brand mentions across all major LLMs prevents single-platform blind spots.
Treating tracking as a standalone project instead of a system
One-time audits generate a snapshot. Systems generate compounding improvements. Connect your tracking program to content planning, product marketing, and PR so that every insight has a clear path to action.
Frequently Asked Questions
How often should you track brand mentions in large language models?
For high-priority prompts tied to purchase intent, weekly or biweekly tracking provides the best balance of signal quality and effort. Mid-priority terms can be checked monthly. The key is consistency — irregular testing makes it difficult to distinguish meaningful shifts from normal LLM response variability.
Can you influence what LLMs say about your brand?
You cannot directly edit LLM responses. You can influence them indirectly by publishing accurate, well-structured content on your own site, securing brand mentions on authoritative third-party publications, maintaining consistent messaging across all digital properties, and correcting outdated information wherever it exists. LLMs learn from this content ecosystem over time through training updates and real-time retrieval.
Do brand mentions in AI responses actually affect revenue?
Direct attribution is still difficult as of 2026, but the evidence is growing. AI search is projected to drive more web traffic than traditional search by 2028, according to a 2025 Semrush study. When an LLM recommends your brand to a buyer actively researching solutions, the influence on pipeline is real — even if it’s harder to track than a Google Ads click.
Is it worth tracking brand mentions if you’re a small or emerging brand?
Yes — arguably more so. Larger brands benefit from existing entity authority that makes LLM inclusion more likely. Smaller brands need to understand exactly where they’re invisible so they can focus limited resources on the highest-impact content and citation opportunities. Startup-focused visibility strategies often start with this kind of targeted tracking.
What’s the difference between an AI brand mention and an AI citation?
A brand mention is any reference to your company name within an AI-generated response. A citation is a reference to a specific source URL used to generate that response. A single AI answer can include mentions without citations (the model names your brand but doesn’t link to a source) or citations without prominent mentions (the model links to your page but doesn’t highlight your brand name in the answer text). Both are valuable to track.
Building a System That Compounds
Tracking brand mentions in large language models isn’t a one-time project — it’s an ongoing discipline that produces better results the longer you maintain it. Each monitoring cycle generates data that sharpens your prompt library, refines your content strategy, and clarifies where your brand stands in the AI-driven discovery landscape.
Start this week with a focused set of 15–20 prompts across two or three LLMs. Capture your baseline. Identify the gaps that matter most to your pipeline. Create one piece of content or secure one high-authority placement targeting your biggest gap. Then measure again.
That cycle — track, analyze, optimize, re-track — is what separates brands that show up in AI recommendations from those that don’t.
If you want to see where your brand currently stands across ChatGPT, Gemini, Perplexity, and Claude — and where competitors are getting mentioned instead of you — request a free AI visibility audit from the BrandMentions team.