
Brand mentions in Claude shape how Anthropic’s AI assistant recommends, describes, and positions your company when enterprise buyers ask for advice. As of 2026, Claude holds roughly 40% of the enterprise LLM API market, and 70% of Fortune 100 companies use it internally, according to Menlo Ventures’ 2025 AI market analysis. If Claude doesn’t mention your brand — or mentions it with outdated information — you’re invisible to a fast-growing segment of high-intent decision-makers.
This article breaks down how Claude decides which brands to reference, what influences mention quality and frequency, and the specific steps you can take to strengthen your brand’s presence in Claude’s responses. Whether you’re a B2B SaaS founder or a VP of Marketing managing AI visibility for the first time, you’ll find a practical system here — not theory.
What You’ll Learn
- How Claude sources brand information differently from ChatGPT, Perplexity, and Gemini
- Why traditional SEO rankings don’t predict Claude visibility
- The three information channels Claude uses to decide which brands to mention
- A step-by-step process for auditing your current brand presence in Claude
- Specific content and entity strategies that increase Claude mention rate and sentiment
- How to measure progress with metrics built for AI visibility — not search engine rankings
How Claude Decides Which Brands to Mention
A brand mention in Claude is any instance where Claude names your company, product, or service within its conversational response to a user query. Unlike traditional search results, Claude doesn’t generate ranked links. It synthesizes information and produces prose — recommending, comparing, or describing brands based on what it considers reliable and relevant.
Claude draws brand information from three distinct channels, each influencing which brands appear and how they’re described.
Training Data: Claude’s Baseline Knowledge
Anthropic trains Claude on a large corpus of web content, books, research papers, and documents. Brands with consistent, authoritative information across multiple high-trust sources appear more reliably in Claude’s baseline responses. This training data reflects a knowledge cutoff — Claude’s foundational knowledge doesn’t update in real time.
If your brand launched after the training cutoff, or if your web presence is thin and inconsistent, Claude may not recognize you at all during training-data-only responses.
Web Search: Real-Time Information Retrieval
When users or integrations enable search capabilities, Claude retrieves current web content to supplement its base knowledge. A critical difference from other AI platforms: Claude’s live web search uses Brave Search as its backend — not Google, not Bing. This means your content must be indexed by Brave to appear in Claude’s real-time answers.
Brands with strong, recently updated content on Brave-indexed pages benefit from web search retrieval. Brands that only optimize for Google’s index may find themselves absent from Claude’s live answers.
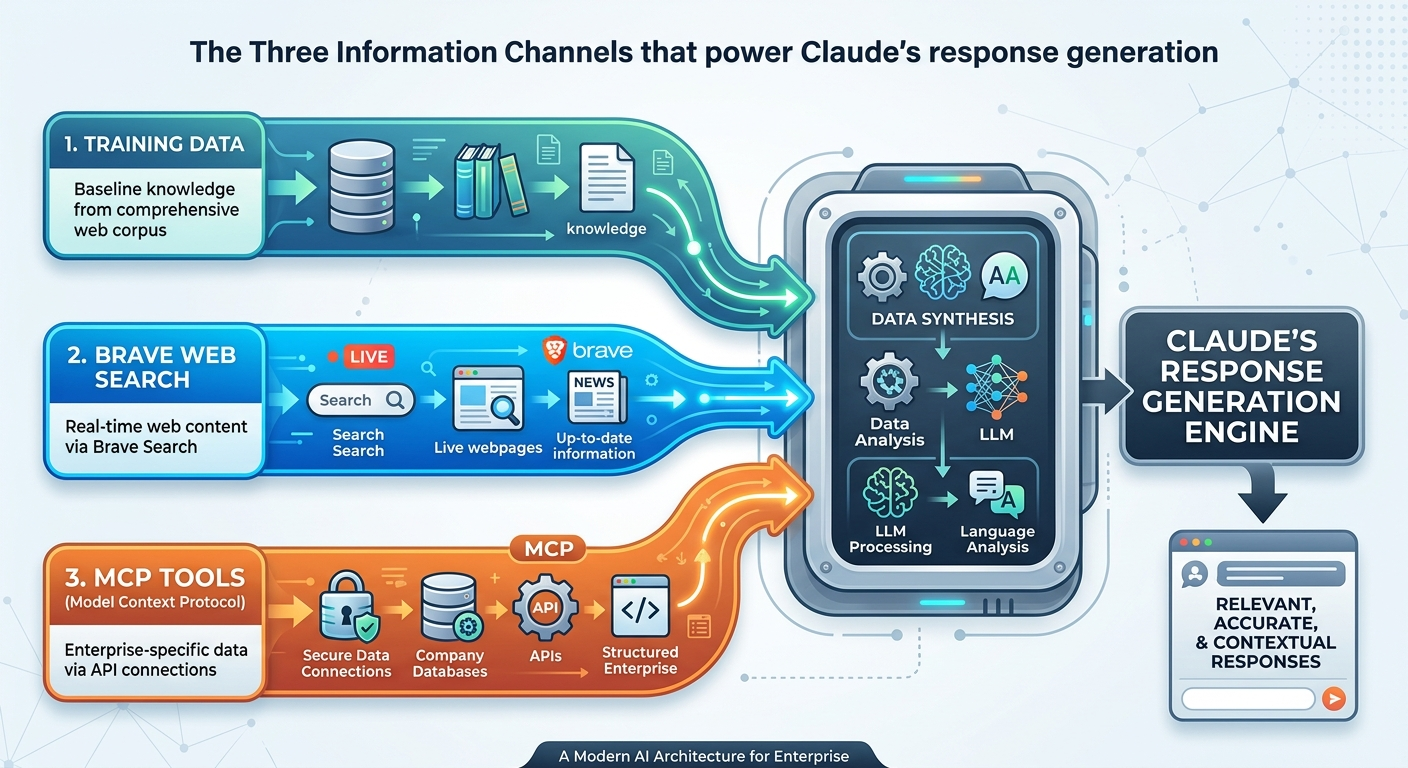
MCP Tools: Enterprise Context
Model Context Protocol (MCP) tools allow Claude to access structured data sources, APIs, and custom knowledge bases in enterprise deployments. When a company connects Claude to internal databases, CRM systems, or product catalogs, Claude’s brand knowledge expands — but only within that specific deployment.
This means Claude’s awareness of your brand can vary by context. A Claude user on the public consumer app sees different information than an enterprise user whose organization has connected proprietary data through MCP.
Constitutional AI Shapes How Claude Presents Brands
Anthropic trains Claude using Constitutional AI, a framework designed to make responses helpful, accurate, and harm-averse. This directly affects brand mentions. Claude hedges on claims it can’t verify, producing cautious language like “some users report” or “according to available sources” rather than definitive endorsements.
Content filled with unverifiable superlatives — “We are the #1 platform on earth” — is statistically less likely to earn confident Claude mentions than content that reads like a well-sourced white paper.
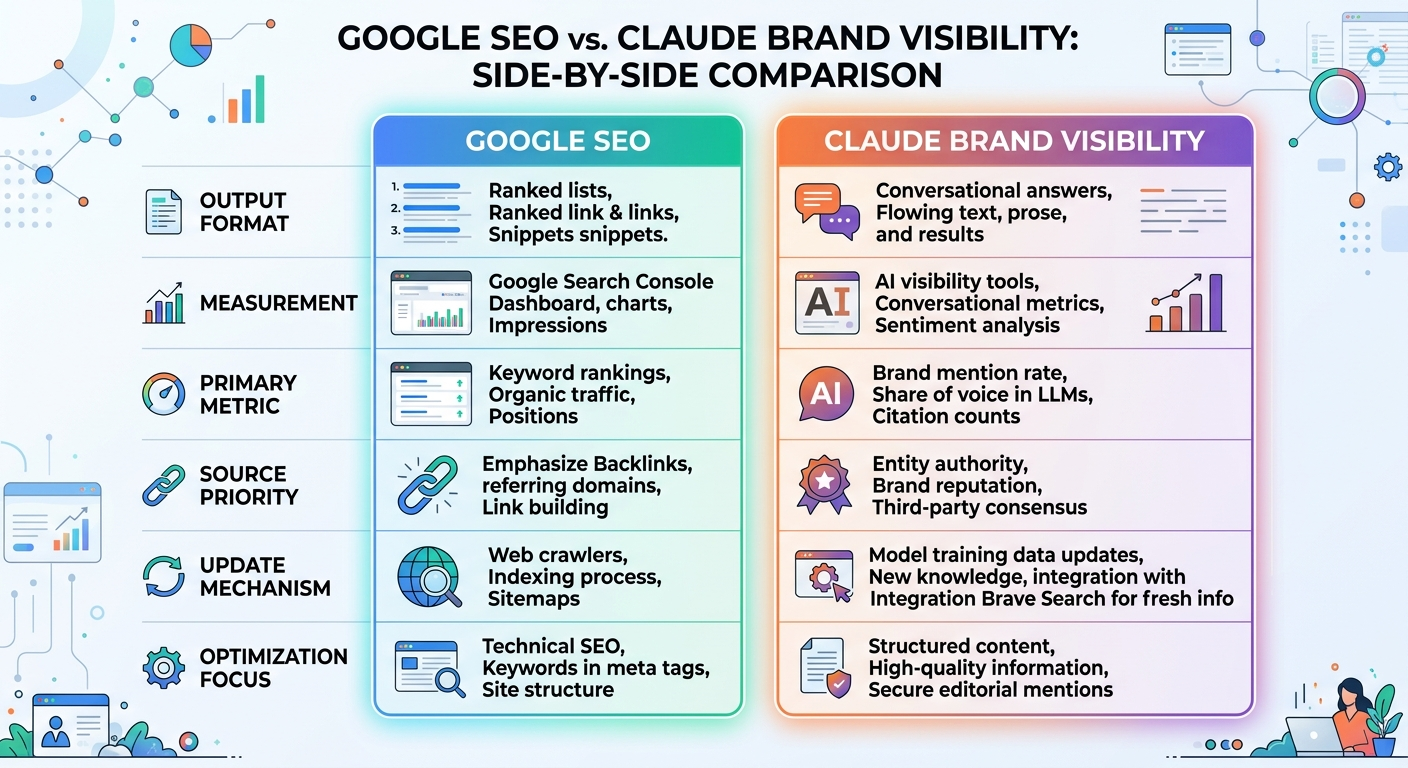
Why Traditional SEO Rankings Don’t Predict Claude Visibility
A brand ranking first on Google for a target keyword may not appear in Claude’s response for the equivalent conversational prompt. Research from AirOps analyzing 21,311 brand mentions across ChatGPT, Claude, and Perplexity found that 85% of brand visibility in AI search comes from third-party sources — not the brand’s own website, blog, or product pages.
This finding fundamentally changes the equation. Traditional SEO rewards your owned content through backlinks, keyword optimization, and technical performance. Claude rewards entity authority — the consistency, frequency, and quality of your brand’s mentions across the broader web.
Several key differences explain why Google rankings and Claude mentions diverge:
- Different source backends. Claude uses Brave Search for real-time retrieval, not Google. Only about 20% overlap exists between Claude and ChatGPT search results, according to QuickSEO’s 2025 cross-platform analysis.
- No link-based ranking. Claude doesn’t evaluate PageRank or backlink profiles. It evaluates source consensus — how many independent, authoritative sources agree about your brand.
- Conversational synthesis over keyword matching. Claude doesn’t match keywords to documents. It matches user intent to concepts, then assembles an answer from multiple inputs.
- Third-party validation dominates. External reviews, comparison articles, industry roundups, and expert analysis drive 6.5x more AI visibility than owned content, according to the AirOps research.
Understanding these differences is essential. Brands that track how brand mentions impact AI search visibility across platforms consistently outperform those applying traditional SEO frameworks to AI channels.
How to Audit Your Brand’s Current Presence in Claude
Before you can improve your brand mentions in Claude, you need a clear baseline. This audit process reveals where your brand stands — and where the gaps are.
Step 1: Build a Prompt Library That Mirrors Buyer Behavior
Create 15–25 prompts across four categories that reflect how your potential customers actually use Claude:
- Category queries: “What are the best tools for [your category]?” or “Top [your category] platforms for [audience]”
- Comparison queries: “[Your brand] vs. [competitor] for [use case]”
- Recommendation queries: “Which [category] tool should I use for [specific scenario]?”
- Negative scenario queries: “What are the downsides of [your brand]?” or “Why do people switch from [your brand]?”
Negative prompts are easy to skip — but they reveal reputation risks you can’t see otherwise. If Claude surfaces outdated pricing, discontinued features, or inaccurate descriptions, you need to know before your prospects encounter them.
Tip: Think like your buyer, not your marketing team. The questions your sales team fields from prospects are often the same questions people ask Claude.
Step 2: Run Each Prompt in a Fresh Claude Session
Open a new Claude conversation for each prompt. Running multiple prompts in the same thread introduces context bias — previous responses influence subsequent ones. You want to simulate how a real buyer interacts: one question, one isolated session.
For each response, record five data points:
- Mention presence: Does your brand appear at all?
- Positioning tier: Is your brand mentioned first (leader), among several options (alternative), or last with qualifying language (afterthought)?
- Sentiment: Is the mention an endorsement, neutral listing, cautious hedge, or negative assessment?
- Competitor landscape: Which competitors appear in the same response, and how are they positioned relative to you?
- Accuracy: Are Claude’s claims about your brand correct and current?
Step 3: Calculate Your Baseline Metrics
From your audit data, calculate three core numbers:
- Brand mention rate: The percentage of relevant prompts where Claude names your brand. If Claude mentions you in 6 of 20 category prompts, your mention rate is 30%.
- Sentiment distribution: What percentage of your mentions are endorsements versus cautious hedges or negative assessments?
- Competitive share of voice: How does your mention frequency compare to each tracked competitor across the same prompts?
These numbers become your reference point. Every optimization action you take should move at least one of these metrics. If you’re tracking whether AI mentions your brand for the first time, expect the baseline to be lower than you’d hope — that’s normal, and it’s exactly why this audit matters.

Five Strategies That Strengthen Brand Mentions in Claude
Improving your visibility in Claude requires a different playbook than ranking on Google. These five strategies target the specific signals Claude uses to decide which brands to mention, recommend, and endorse.
1. Build Entity Authority Through Source Consensus
Claude mentions brands confidently when multiple independent, authoritative sources agree about what that brand is and does. This is entity authority — the strength and consistency of your brand’s identity across the web.
Entity authority strengthens when:
- Your brand name, product descriptions, and category positioning are identical across your website, third-party profiles, review platforms, and media coverage
- Independent publications describe your brand using the same core terms you use
- Multiple trusted sources confirm the same factual claims about your product
Claude hedges when information conflicts. If your website says you serve “enterprise teams” but G2 reviews describe you as a “small business tool,” Claude won’t commit to either description. Resolve inconsistencies across every touchpoint.
Action step: Audit your brand’s description on your top 20 external profiles — G2, Capterra, Crunchbase, LinkedIn, industry directories. Standardize your company description, category, and core value proposition across all of them.
2. Earn Editorial Mentions on High-Authority Publications
The AirOps research confirmed that nearly 90% of third-party mentions surfaced by AI search came from listicles, comparisons, or reviews. Claude’s training data and web retrieval both favor these content formats because they provide structured, evaluative information about brands in context.
To earn these mentions:
- Pursue inclusion in category roundups and “best of” lists on publications that Claude’s training data likely includes (TechCrunch, industry-specific media, established review sites)
- Contribute expert commentary to industry publications — podcast transcripts, bylined articles, and quoted insights all create brand-entity associations in training data
- Ensure your presence on software directories with detailed, accurate feature descriptions and genuine customer reviews
Agencies like BrandMentions approach this systematically, placing contextual brand mentions on 140+ high-authority publications that AI models actively learn from during training. The compounding effect matters — each additional authoritative mention reinforces Claude’s confidence in referencing your brand.
Understanding how brand mentions work across both traditional search and AI platforms helps you prioritize the right publications.
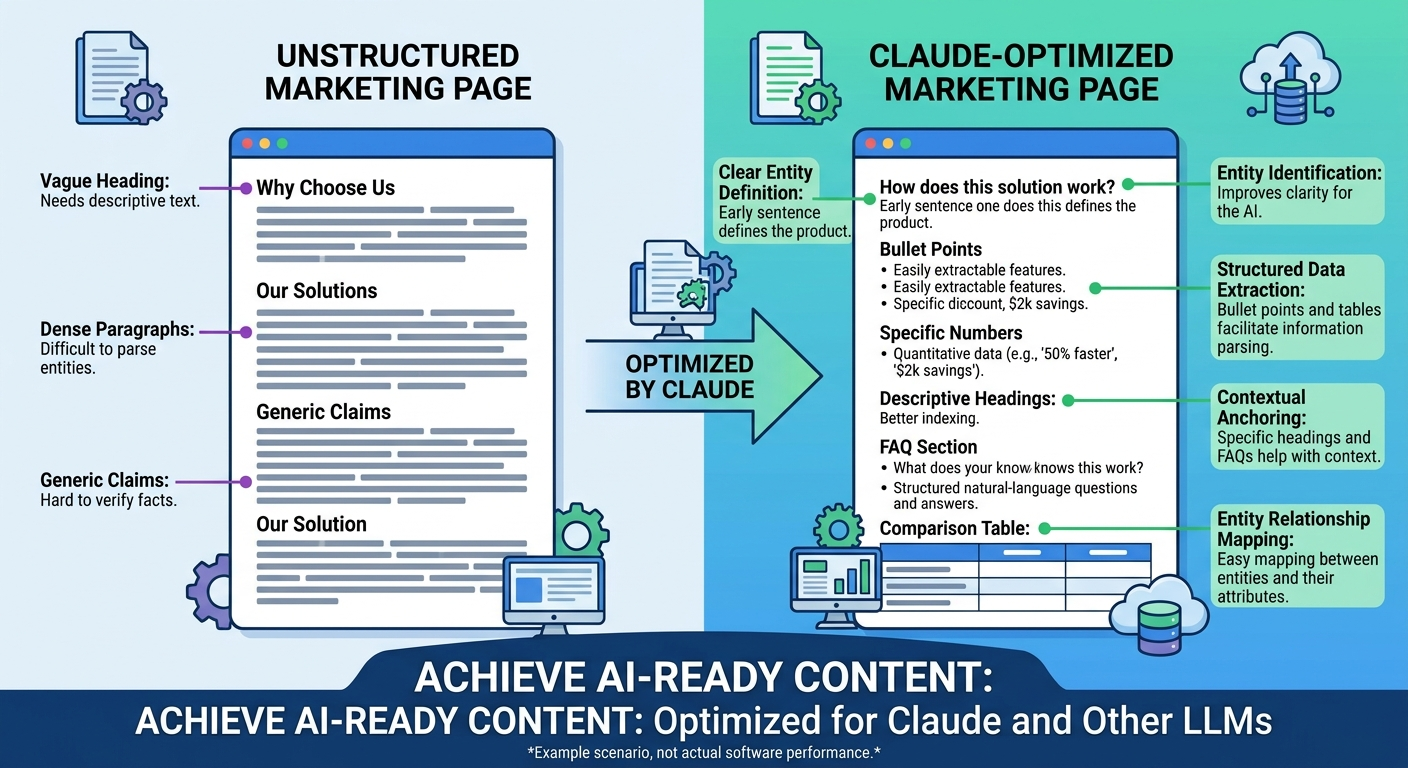
3. Structure Content for AI Extraction
Claude extracts information more reliably from clearly structured content than from unstructured marketing copy. When your content mirrors the patterns Claude uses to synthesize answers, your brand information becomes easier for Claude to parse and reference.
Structural elements that improve Claude extractability:
- Clear entity definitions: State what your brand is in one explicit sentence on key pages. “Acme is an AI-powered procurement platform that automates vendor approvals for mid-market finance teams.” Don’t assume Claude will infer your category.
- FAQ sections matching natural prompts: Structure questions using the same phrasing your buyers use when asking Claude for recommendations.
- Comparison tables with specific data: Pricing tiers, feature limits, integration lists, and use-case matrices are non-paraphrasable — Claude must cite or reference them directly.
- Descriptive headings: Use H2s and H3s that map to conversational queries: “How [Brand] Compares to [Competitor] for [Use Case]” rather than vague headings like “Our Advantages.”
Key definition: AI extraction refers to the process by which language models identify, parse, and reference specific claims, definitions, or data points from web content when generating conversational responses.
4. Ensure Brave Search Indexes Your Key Pages
Since Claude uses Brave Search for real-time web retrieval, your content must be indexed by Brave — not just Google. Brave builds its own independent index and doesn’t rely on Google’s or Bing’s crawling infrastructure.
Three paths to Brave indexation:
- Web Discovery Project: When Brave browser users with Web Discovery enabled visit your pages, Brave receives anonymous signals that help it discover and index those URLs. New sites typically register after approximately 20 visits from different IPs.
- Manual URL submission: If key pages don’t appear when you search for them on Brave, use the “Feedback” link on Brave Search results to suggest those URLs for indexation.
- Crawler access: Confirm your robots.txt doesn’t block Brave’s crawler. Brave won’t crawl anything blocked for Googlebot, so if your pages are accessible to Google, they should be accessible to Brave as well.
Also verify that ClaudeBot (Anthropic’s primary crawler) has access to your content. Blocking ClaudeBot in your robots.txt prevents Claude from indexing updated brand information in its training data. Check your crawler access settings alongside GPTBot (OpenAI) and PerplexityBot configurations.
5. Publish Content Claude Can’t Answer From Memory
Claude only searches the web when its internal knowledge isn’t sufficient. Broad, evergreen topics (“what is SaaS”) rarely trigger a web search. Specific, product-level, or time-sensitive queries do.
Content types that trigger Claude’s web search and earn citations:
- Current pricing and plan details: Claude can’t reliably recall pricing from training data, so it searches for current information
- Integration requirements and compatibility: Technical specifics that change with product updates
- Feature limits, thresholds, and compliance details: Exact values Claude can’t paraphrase without losing accuracy
- Step-by-step workflows tied to specific products: Instructional content with precise sequences
- Year-specific releases, benchmarks, or industry data: Information tagged with a recency signal
In testing, researchers observed that Claude rewrites queries with built-in year markers (“2026”) even when the user doesn’t specify a date. Pages with visible freshness signals — updated titles, recent timestamps, current data — consistently outperform undated pages in Claude’s retrieval, according to analysis published by Embarque in early 2026.
Action step: Identify your top 10 product pages and update them with current-year data, visible “Updated [Month] 2026” timestamps, and specific details (pricing, limits, integrations) that Claude would need to search for rather than recall from memory.
Measuring Progress: Metrics Built for Claude Visibility
Traditional SEO metrics — keyword rankings, organic traffic, click-through rates — don’t capture Claude visibility. You need AI-specific metrics tracked consistently over time.
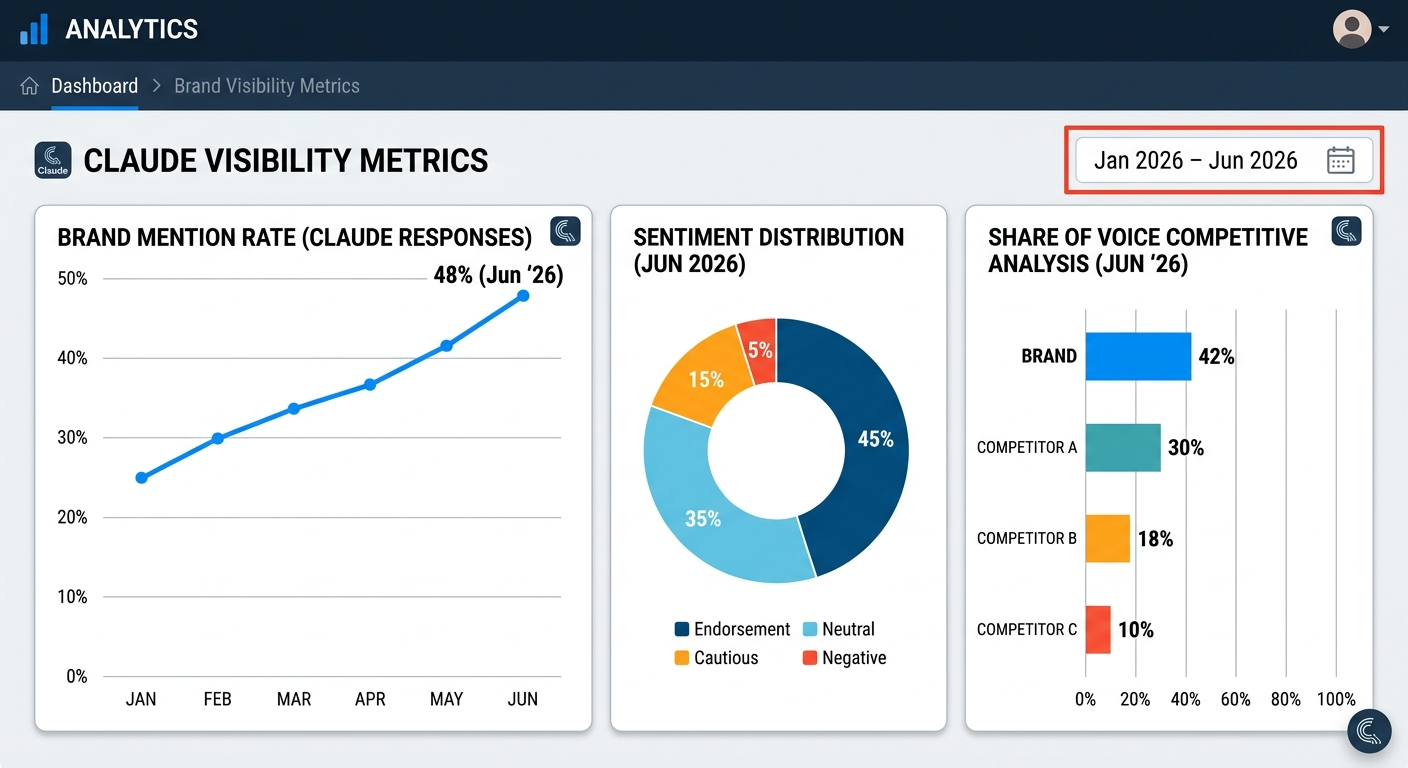
Core Metrics to Track Monthly
| Metric | What It Measures | Why It Matters for Claude |
|---|---|---|
| Brand mention rate | Percentage of relevant prompts where Claude names your brand | Your overall presence in Claude responses |
| Sentiment distribution | Ratio of endorsements to neutral, cautious, or negative mentions | How confidently Claude recommends you |
| Positioning tier | Whether you’re mentioned first, mid-list, or as an afterthought | First-named brands earn higher user trust and selection rates |
| Competitive share of voice | Your mention frequency relative to competitors in shared prompts | Your market position within Claude’s recommendations |
| Response accuracy | Percentage of mentions containing correct, current information | Inaccurate mentions erode buyer trust even when visibility is high |
In campaigns across 67+ B2B companies, the BrandMentions team found that brands with consistent editorial mentions achieved AI recommendation rates 89% higher than those relying solely on traditional SEO. Tracking these metrics monthly reveals whether your optimization efforts are moving the needle — or whether you’re investing in the wrong signals.
For a comprehensive approach to tracking your performance, a brand mentions report consolidates Claude data alongside visibility metrics from other AI platforms into a single view.
How to Track Without Manual Testing
Manual testing — opening Claude, running prompts, recording responses — works for an initial baseline audit. It doesn’t scale. Running 20 prompts manually takes 30–60 minutes per session, and Claude’s responses vary based on conversation context, making consistency difficult.
Automated AI visibility platforms run your prompt library across Claude and other AI models on a recurring schedule. They track mention rate, sentiment, competitive positioning, and citation sources without manual effort. If you’re monitoring brand mentions in LLMs across multiple platforms, automation becomes essential — the alternative is hours of manual work that produces inconsistent data.
Set a tracking cadence that matches your resources. Weekly monitoring catches most shifts in Claude’s brand perception. Monthly deep dives identify strategic patterns. Quarterly reviews align AI visibility data with broader marketing strategy.
How Claude Visibility Differs Across AI Platforms
Your brand’s visibility in Claude doesn’t predict your visibility in ChatGPT, Perplexity, or Gemini. Each platform sources information differently, cites brands with different patterns, and weights different authority signals.
| Dimension | Claude (Anthropic) | ChatGPT (OpenAI) | Perplexity | Google Gemini |
|---|---|---|---|---|
| Web search backend | Brave Search | Bing | Own index + multiple sources | Google Search |
| Citation behavior | Conversational integration, minimal inline citations | Selective citations | Inline citations in ~94% of responses | Google-style attribution |
| Brand tone | Cautious, evidence-based, hedges on unverified claims | More assertive recommendations | Source-driven, attributes heavily | Knowledge Graph-weighted |
| Enterprise adoption | 40% of enterprise LLM API market | Dominant in consumer use | Growing in research contexts | Integrated with Google Workspace |
A brand performing well in ChatGPT brand mentions may be absent from Claude entirely — and vice versa. Cross-platform tracking reveals whether gaps are platform-specific or reflect broader content problems.
For example, if your brand appears consistently in Perplexity and ChatGPT but not in Claude, the issue likely relates to Brave Search indexation or Claude-specific training data gaps — not your overall web authority. If your brand is absent across all platforms, the root cause is more fundamental: weak entity authority, insufficient third-party mentions, or inconsistent brand information across the web.
Tracking visibility across multiple AI search platforms simultaneously gives you the diagnostic precision to address the right problems.
Common Mistakes That Suppress Brand Mentions in Claude
Some of the most common AI visibility practices actively work against you in Claude. Anthropic’s Constitutional AI framework makes Claude more cautious than other models — and certain content signals trigger that caution.
Mistake 1: Marketing Copy Instead of Informational Content
Claude de-prioritizes content heavy on promotional language, unverifiable superlatives, and vague benefit claims. A product page that says “The world’s most powerful platform” gives Claude nothing to cite. A product page that says “Processes 50,000 vendor approvals monthly with a 99.7% accuracy rate across 12 ERP integrations” gives Claude specific, referenceable data.
Mistake 2: Blocking AI Crawlers
Some organizations block ClaudeBot, GPTBot, or other AI crawlers in their robots.txt as a blanket policy. This prevents Claude from indexing updated brand information. If your robots.txt blocks ClaudeBot, Claude can only reference whatever it learned about your brand during its last training data update — which may be months or years old.
Mistake 3: Ignoring Brave Search Entirely
Most SEO teams optimize exclusively for Google. Since Claude uses Brave Search for real-time retrieval, content that performs well on Google may not appear in Claude’s live answers. Verify your key pages are indexed on Brave independently.
Mistake 4: Inconsistent Brand Information Across Sources
Claude cross-references multiple sources. When your website describes your product differently than your G2 profile, your LinkedIn company page, and your Crunchbase listing, Claude encounters conflicting signals and defaults to cautious, hedged language — or omits your brand entirely.
Mistake 5: Optimizing for Keywords Instead of Entities
Claude doesn’t match keywords to documents. It matches concepts to entities. Repeating your target keyword won’t improve Claude visibility. Building a clear, consistent entity — a brand identity that Claude can map to specific categories, use cases, and user needs — will.
For a broader view of how mentions function across search and AI, brand mentions for SEO explains the relationship between citation building and discoverability on both traditional and AI search surfaces.
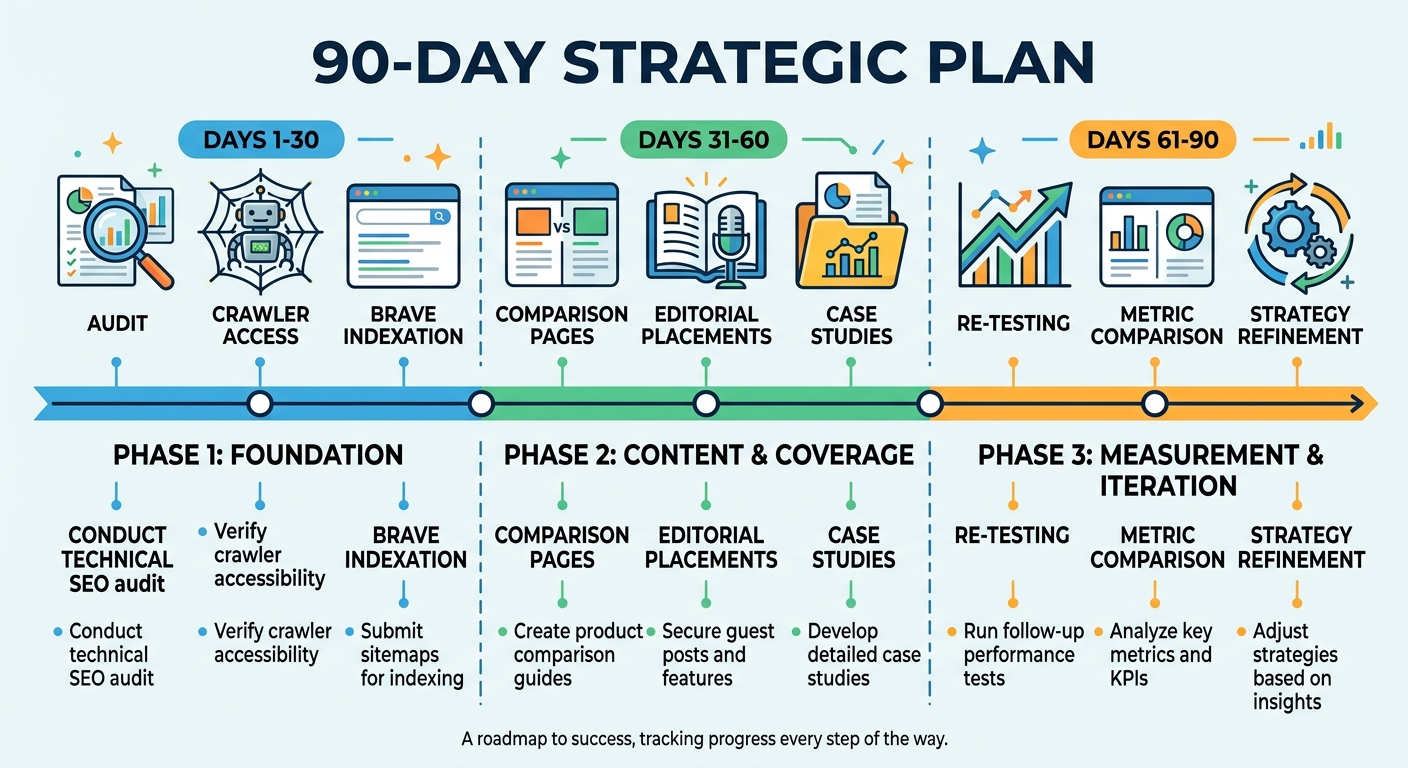
A Practical 90-Day Plan for Improving Brand Mentions in Claude
Sustained improvement requires consistent effort across multiple fronts. This 90-day framework prioritizes high-impact actions first.
Days 1–30: Foundation
- Complete the audit process described above — build your prompt library, run baseline tests, calculate starting metrics
- Audit and standardize your brand description across your top 20 external profiles
- Verify ClaudeBot and Brave Search crawler access in your robots.txt
- Confirm your top 10 product and category pages are indexed in Brave Search
- Update key pages with current-year timestamps, specific product data, and clear entity definitions
Days 31–60: Content and Coverage
- Publish 3–5 structured comparison and FAQ pages targeting the prompt categories where your brand is absent
- Pursue inclusion in 5–10 category roundups or review articles on high-authority publications
- Create detailed case studies with specific, non-paraphrasable metrics (exact numbers, timelines, outcomes)
- Build content clusters around your primary category — pillar content supported by interlinked guides covering subtopics, comparisons, and use cases
Days 61–90: Measurement and Iteration
- Re-run your full prompt library and compare results to your Day 1 baseline
- Calculate changes in mention rate, sentiment distribution, and competitive share of voice
- Identify which actions correlated with improvements — document them as repeatable tactics
- Address any new accuracy issues or negative sentiment that emerged
- Expand your prompt library with 5–10 new exploratory prompts reflecting emerging buyer questions
Pro insight: BrandMentions tracks when major AI models update their training data and times placements to maximize inclusion in each knowledge refresh cycle. Aligning your content publishing schedule with Claude’s training updates accelerates the compounding effect of editorial mentions.
Frequently Asked Questions
Does my Google ranking affect whether Claude mentions my brand?
Not directly. Claude uses Brave Search for real-time retrieval, not Google. A page ranking first on Google may not appear in Brave’s index at all. While strong web authority generally helps across platforms, Claude evaluates entity consistency and source consensus rather than Google-specific ranking signals. Optimize for both, but don’t assume Google success translates to Claude visibility.
How long does it take for new content to influence Claude’s responses?
It depends on the channel. Content indexed by Brave Search can influence Claude’s real-time retrieval within days to weeks. Influencing Claude’s training data takes longer — typically until Anthropic’s next model update or training refresh, which happens on an irregular schedule. Publishing on high-authority sites that are already well-represented in Claude’s training corpus offers the fastest path to training-data influence.
Can I track brand mentions in Claude without manual testing?
Yes. Automated AI visibility platforms run your prompt library across Claude on a recurring schedule and track mention rate, sentiment, competitive positioning, and citation sources. Manual testing works for an initial audit but doesn’t scale for ongoing monitoring. Explore AI visibility analytics tools to find options that fit your tracking needs.
Is Claude more important than ChatGPT for B2B brands?
For enterprise buyers, Claude’s influence is disproportionately high. Claude holds 40% of the enterprise LLM API market and is used by 70% of Fortune 100 companies, according to Menlo Ventures’ 2025 analysis. Claude referral traffic also delivers the highest average session value ($4.56) of any AI platform, per QuickSEO’s tracking data. If your buyers are enterprise decision-makers — CTOs, VPs of Engineering, procurement leaders — Claude visibility matters as much or more than ChatGPT visibility.
What should I do if Claude describes my brand inaccurately?
Trace the source of the error. Claude may be referencing outdated web pages, conflicting third-party profiles, or deprecated product information. Update your structured data, correct outdated content on your own site and third-party profiles, and ensure your brand’s factual record is consistent everywhere. For real-time retrieval, verify the corrected pages are indexed in Brave Search. For training-data errors, consistent corrections across multiple authoritative sources will influence Claude’s next model update.
What Comes Next: Building Claude Visibility That Compounds
Brand mentions in Claude aren’t a one-time project. Anthropic releases model updates regularly — Claude’s capabilities, training data, and retrieval behavior shift with each iteration. Competitors publish new content. Your own product evolves. The brands that maintain strong Claude visibility treat it as an ongoing practice, not a campaign.
The compounding effect is real. Each authoritative editorial mention reinforces Claude’s confidence in your brand. Each structured content piece gives Claude new extraction points. Each consistent external profile strengthens entity consensus. Over 90 days, these signals stack. Over six months, they compound into measurably stronger AI visibility across generative AI platforms.
Start with the audit. Know where you stand. Then build systematically — entity authority, editorial coverage, structured content, and Brave Search indexation. Measure monthly. Iterate quarterly. The brands doing this now are building an advantage that grows harder to replicate with every passing month.
See where your brand stands in AI search. Get your free AI visibility audit and find out exactly what Claude, ChatGPT, and Perplexity say about your brand — and your competitors.