
DeepSeek brand visibility is not the same as ranking on Google, and that difference is exactly why marketers are starting to track it. Your brand can sit at position one for a query and still never surface when someone asks DeepSeek the same question in plain language. DeepSeek brand visibility is the degree to which your brand is mentioned, recommended, cited, or framed positively in DeepSeek responses to relevant prompts. That is a separate thing from search result placement, and it is separate from generic AI visibility across ChatGPT, Gemini, or Perplexity. This article defines the term, explains what shapes it, and shows how to think about tracking it, without pitching a tool.
What DeepSeek Brand Visibility Means
DeepSeek brand visibility measures how your brand shows up inside DeepSeek’s generated answers, not where your site lands in a list of blue links. When a user asks DeepSeek to recommend a vendor, compare options, or explain a category, the model produces prose. Your visibility is whether that prose names you, how it frames you, and whether it attributes a source to back the mention.
This visibility is prompt-specific, not universal. A brand can appear for one query and vanish for a close variation of the same question. Ask about “best invoicing software for freelancers” and you might get named. Ask about “invoicing tools for small agencies” and you might not. Treat visibility as a pattern across many prompts, never a single fixed position.
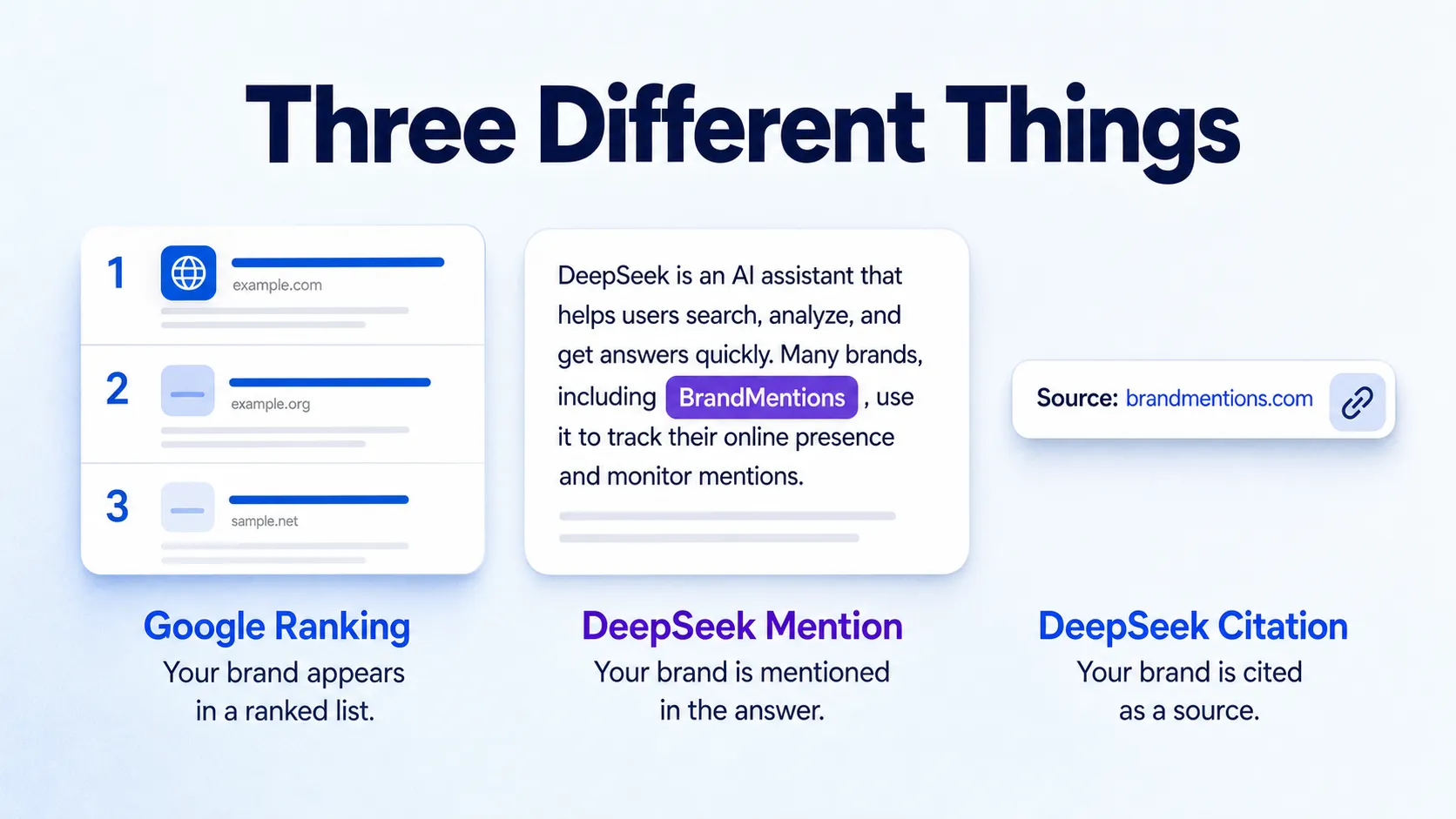
Two parts of visibility get blurred together, and they should not. A mention is DeepSeek naming your brand in the body of its answer. A citation is DeepSeek attaching a source link that references your brand or its claim. You can be mentioned without being cited, and a source can be cited without your name appearing in the visible answer at all. The brand mention and citation terms matter here because measuring one while assuming you measured the other leads to wrong conclusions.
The pattern most teams notice first: strong organic SEO does not guarantee strong DeepSeek representation. A brand can own the top of Google for its category and still show up inconsistently, or not at all, inside DeepSeek answers. The model pulls from a different mix of signals, and it interprets brand identity differently than a ranking algorithm does.
Why DeepSeek Brand Visibility Matters
DeepSeek visibility matters because it shapes discovery and consideration before a user ever reaches your site. When someone asks the model for recommendations and acts on the answer, that is a zero-click decision. The brand named in the response wins attention that never showed up in your analytics as a search click.
Framing carries weight too. If DeepSeek presents your brand as a default recommendation, alongside credible sources, that reads as trust to the person asking. If it frames you as a secondary option or leaves you out while naming competitors, that shapes the shortlist against you. This is where brand mentions affect AI search visibility in a way that compounds over repeated queries.
Share of voice is the practical business lens. In categories where buyers ask AI to compare vendors, the brands that appear repeatedly own the conversation, and the ones that never surface are invisible at the exact moment a decision forms. That effect can be sharper in international markets, since DeepSeek carries a large audience across Asia-Pacific and other regions where model-driven discovery already influences buyer research.
Here is the honest framing: for most brands, Google is still the strongest traffic source, and DeepSeek is not going to replace that tomorrow. But DeepSeek already influences shortlists and competitive perception in some categories, and reputation formed inside AI answers is harder to correct once it sets. Watching it early costs little. Ignoring it means you find out only when a competitor is already the default answer.
How DeepSeek Appears to Choose Brands
DeepSeek’s exact selection logic is not published, so treat what follows as an informed read of observed behavior, not a decoded algorithm. The model appears to weigh several inputs when it decides which brands to name in an answer. These are the patterns worth understanding, in the order they tend to matter.

- Prompt context and intent. DeepSeek reads the meaning behind a query, not just its keywords. “A reliable CRM for a small sales team” and “cheapest CRM” pull different candidate brands because the intent differs, even though both are CRM questions.
- Entity recognition. The model has to identify the correct brand, product, or company behind a name before it can name you. If your brand shares a name with something else, or its identity is unclear across the web, DeepSeek may cite the wrong entity or skip you to avoid confusion.
- Source material. Third-party pages carry heavy weight, including review sites, community discussions, and industry publications. Brands that other credible sources describe consistently give the model more to work with than a brand that only describes itself on its own site.
- Recency. When the model has several viable candidates, fresher references can tip which brand it names. Content and mentions that reflect the current state of a category tend to surface over stale ones.
- Session, language, and region variance. The same prompt can return different brands across sessions, languages, and markets. This is why DeepSeek results are not stable enough to treat like static rankings, and why one snapshot never tells the full story.
The through-line: AI answers tend to mirror the strongest externally validated brand signals, not the claims a brand makes about itself on its homepage. If credible third parties do not describe you clearly, the model has little to pull from. How the AI crawlers actually pick sources feeds directly into which brands end up named.
What Influences DeepSeek Brand Visibility
Several inputs move DeepSeek visibility, and they work together rather than in isolation. The table below breaks down the core signals, why each one matters, and what a marketer can actually influence. DeepSeek tends to reward brands that are easy to verify, easy to disambiguate, and repeatedly mentioned by other credible sources.

| Signal | Why it matters | What you can influence |
|---|---|---|
| Web mentions | Third-party content, community threads, review sites, and industry publications give the model material to name you | Earn genuine coverage and mentions in places DeepSeek pulls from |
| Authoritative citations | A cited source is stronger than a bare mention, since it backs the claim the model makes about you | Get referenced on credible, well-regarded pages, not just any page |
| Content clarity | Concise, well-labeled explanations and question-answer formatting are easier to extract into an answer | Structure your own pages so claims are direct and self-contained |
| Structured data and entity clarity | Schema markup, consistent naming, and disambiguation help the model recognize the right brand | Add schema, keep your name consistent, and reduce entity confusion |
| Reputation signals | Reviews, sentiment, and whether you are discussed as trustworthy shape how the model frames you | Build and maintain genuine review and reputation presence |
One factor cuts across the whole table: the same brand can perform differently by query type, geography, and language. A vendor that surfaces strongly for English-language prompts in the United States may be near-invisible for the same category in another market. The AI citation ranking factors that decide inclusion are not uniform across regions, so read your visibility per market rather than as a single global number.
Common Mistakes and Misconceptions
Most bad calls on DeepSeek visibility come from carrying over search-era assumptions that do not hold. The table below pairs the wrong reading with the correct one, so you can catch the trap before it shapes a decision.
| The misconception | The accurate read |
|---|---|
| Good SEO means good DeepSeek visibility | Ranking well on Google does not translate directly, because the model pulls from a different source mix and interprets brand identity its own way |
| Mentions and citations are the same metric | A mention names you in the answer; a citation attaches a source. Tracking one while assuming the other misreads your position |
| Visibility is stable once you have it | AI answers change across regenerations and prompt variations, so a single appearance is not a fixed win |
| One tactic guarantees inclusion | Schema alone, or backlinks alone, does not force the model to name you. The signals compound; no single lever guarantees a citation |
| Visibility is the same everywhere | Regional and language effects mean a brand can look strong in one market and weak in another for the identical query |
The pattern that catches teams off guard: they assume their Google rankings should map onto AI answers, then discover the model is pulling from a different set of sources entirely. Understanding how brand mentions work in AI search resolves most of this confusion before it costs a campaign.
How to Monitor and Measure DeepSeek Brand Visibility
Measuring DeepSeek visibility is a trend problem, not a single-ranking problem. You are not chasing one number that goes up. You are watching how your brand’s representation moves across many prompts over time. Here is what teams usually track, kept conceptual so it holds regardless of which tool you eventually pick.

- Mention frequency. The simplest measure: across a set of relevant prompts, how often does DeepSeek name your brand at all? This is your baseline presence signal before anything else.
- Citation source mix. When DeepSeek references your brand, which websites or domains does it appear to lean on? Knowing the sources shaping your answers tells you where to earn presence next.
- Sentiment and framing. Being named is not enough if the framing works against you. Track whether the model presents you as a default recommendation, a secondary option, or a negative example.
- Competitor presence and share of voice. When you are absent, who gets named instead? Watching which rivals appear in your place is often more actionable than watching your own count.
- Prompt coverage and regeneration consistency. Run the same query more than once and across variations. How reliably does your brand appear? Consistency across regenerations is a stronger signal than a single lucky appearance.
The goal is not perfect precision. It is a reliable trend signal you can read over weeks and months. This mirrors the broader shift in AI visibility versus SEO metrics: you are tracking direction and pattern, not a fixed rank you defend. For the wider view across models, the same logic that drives monitoring brand mentions in LLMs applies to DeepSeek, with DeepSeek’s regional and language behavior layered on top.
DeepSeek Brand Visibility in Plain Language
DeepSeek brand visibility is about representation inside AI answers, not placement in a search results list. It matters because it shapes discovery, trust, and zero-click consideration at the moment a buyer forms a shortlist, often before your analytics ever register the interaction.
The biggest influences are external mentions, authoritative citations, content clarity, structured data, reputation signals, and recency, and they compound rather than working alone. No single tactic guarantees a citation, and results shift by prompt, language, and region.
Treat this as an emerging measurement problem. Focus on patterns over time rather than perfect certainty, because DeepSeek visibility is a channel where authority and how easily an AI can interpret your brand matter as much as classic SEO strength. The brands that get interpreted clearly and validated widely are the ones that get named.
Frequently Asked Questions
What is DeepSeek brand visibility?
DeepSeek brand visibility is the degree to which your brand is mentioned, recommended, cited, or framed positively in DeepSeek’s answers to relevant prompts. It measures your representation inside AI-generated responses, which is different from where your site ranks in traditional search results.
Does SEO improve DeepSeek brand visibility?
Strong SEO helps, but it does not guarantee DeepSeek visibility. The model pulls from a different mix of sources and interprets brand identity its own way, so a brand can rank at the top of Google and still appear inconsistently, or not at all, inside DeepSeek answers. SEO builds a foundation; it is not the whole picture.
What influences whether DeepSeek mentions a brand?
Prompt context, entity recognition, third-party source material, recency, and reputation signals all play a part. A brand that credible external sources describe clearly and consistently gives the model more to work with than one that only describes itself. Think of it this way: if a review site, a community thread, and an industry publication all name you the same way, DeepSeek has a much easier time naming you too.
Is DeepSeek brand visibility the same as AI visibility?
No. AI visibility is the broad term for representation across all AI answer engines, including ChatGPT, Gemini, and Perplexity. DeepSeek brand visibility is specific to DeepSeek, and because model behavior differs by engine, your visibility in one does not predict your visibility in another.
Can you track DeepSeek brand mentions directly?
DeepSeek does not offer built-in brand visibility analytics, so tracking happens by running relevant prompts and recording how your brand appears over time. You watch mention frequency, cited sources, sentiment, and competitor presence across many queries, treating the result as a trend rather than a single fixed score.
The fastest way to make this concrete is to test it yourself. Ask DeepSeek a handful of your real buying questions, note whether your brand is named, how it is framed, and who appears instead, then repeat the same prompts in a few weeks to see how the pattern moves.
